
How to Best Understand Bloor’s Research on HANA
Executive Summary
- Bloor Research investigated HANA, which calls into question SAP’s claims on HANA.
- These areas include the claims regarding in memory, HANA 2.0, the HANA platform, AnyDB versus HANA, and HANA’s supposed performance.

Introduction to Bloor Research’s White Paper on HANA
In June 2017, Bloor Research produced the white paper titled Exploding the Myths of SAP HANA. In this article, we will evaluate the accuracy of this Bloor Research article.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Notice of Lack of Financial Bias: We have no financial ties to SAP or any other entity mentioned in this article.
- This is published by a research entity, not some lowbrow entity that is part of the SAP ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on SAP is provided by SAP, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, SAP pays off all IT analysts -- who have the same concern for accuracy as SAP. Not one of these entities will disclose their pro-SAP financial bias to their readers.
Article Quotations
“If you are a long-time SAP application user then SAP would you like you to migrate to SAP HANA. However, this is not a simple decision: it is an expensive option, and it is disruptive from a technical point of view.”
This is quite true. I cover this topic of HANA’s expense in the article The Secret to Not Talking About the Cost of HANA.
“SAP HANA is a brand as well as a product. As a product, it is a database, but it is also the brand name for SAP’s latest enterprise resource planning (ERP) applications (S/4 HANA Enterprise Management) and the company’s cloud-based applications. This has enabled SAP to make marketing claims about “HANA” which we would argue have been misleading. We, therefore, deplore this deliberate blurring of the lines between what HANA is as a product and what it is as a brand.”
Brightwork has pointed this out multiple times, one example being How to Deflect That You Were Wrong About HANA. Another is the article Was the HANA Cloud Platform Designed for Cloud Washing.
In Memory?
“..SAP HANA is often marketed as an “in-memory” database. But in-memory is simply a deployment option, not an architectural description. Moreover, all databases make use of memory and always have done, so using “in-memory” as an epithet is simply marketing fluff. Where SAP HANA is different is that it is designed to run entirely in memory (whereas IBM Db2, for example, is designed to optimise performance regardless of how much memory is available).”
This is an excellent point.
Anyone who wants to can place an entire database in memory. But it is wasteful, and therefore it is rarely done. SAP seems to be the only vendor who thinks that this is a good use of resources. Typically tables that are accessed are put into memory. It makes little sense to place the entire database into memory as most of the database tables are not used most of the time.
Strangely, this is not brought up and commonly understood as SAP receives enormous differentiation from always proposing that they have an in memory solution when other vendors do not.
“optimizing memory usage is much more mature technology (for example, leveraging Db2 caching algorithms and buffer pools) and is likely to be more cost effective.”
SAP’s Brute Force Approach
So SAP’s brute force approach to improving the database’s speed is a poor use of resources as the ability to move tables into and out of memory is already quite sophisticated functionality at other database vendors. This explains why HANA cannot match Oracle 12c’s performance, as covered in the article What is the Actual Performance of HANA. It may not be able to match IBMs or SQL Server either. I simply have not researched the topic.
IBM is conflicted when criticizing HANA because they receive far more money from consulting in SAP than from selling DB2. But IBM’s funding and showcasing of Bloor’s research may indicate that IBM has tired of having not to defend its database against SAP’s exaggerated claims for HANA.
“Column stores enable a better compression rate which, in theory at least, reduces storage requirements. However, SAP HANA stores multiple copies of the in-memory data for redundancy purposes, and you also need a further copy for log space. In other words, most of what you gain on the swings you lose on the roundabouts: you would need a compression rate of approaching 90% to gain significant storage savings.”
Hasso’s One-Sided Statements
This is all true. And this is the problem with listening to anything that Hasso Plattner has to say. Hasso is consistently providing only one side of every argument. I don’t take anything he has to say seriously. Hasso is looking for low information IT decision makers to provide them with mostly false simplistic platitudes based upon erroneous information. For example, SAP has PowerPoints that show that HANA reduces the database footprint by 98.5%. This is, first, ludicrous, but secondly, it is not backed up by project experiences with HANA from the field. When you bring this type of comment to hardened database experts, they fall laughing. This is reminiscent of when Deepak Chopra went to CalTech and brought his magical thinking about how electrons have consciousness.
Here is what happens when you lie to people on a topic they know about.
That type of stuff may work at a book reading at the shop that sells meditation books, incense, and crystals, but it’s not going to fly where people understand quantum physics. So Hasso has to be careful not to take his act to people that know the subject matter. But in Hasso’s bubble, where everyone at SAP kowtows to him, and he is the 20 billion dollar man, no one has what it takes to tell him he is wrong.
Hasso’s Similarities with Deepak Chopra
Like Deepak, Hasso is a world class BS artist. And he has tricked many people over decades.
The same problem applies to Hasso’s assertions regarding the “simplification” of the database, as is covered in the article, Does HANA Actually Have a More Simple Data Model?
HANA’s Costs?
“While this is only anecdotal evidence, we consistently hear that SAP HANA is the most expensive option you can invest in, both in outright terms and on a price/ performance basis.”
The TCO component costs of HANA support Bloor’s anecdotal evidence. After a long time of not being discounted, HANA began to become discounted. But the overall TCO of HANA is still exorbitant. Every cost factor you look for that makes up TCO is higher with HANA. Yet SAP paid Forrester to produce an indefensible paper on how HANA would reduce TCO, as is discussed in the article How Accurate was Forrester’s Article on HANA TCO.
HANA’s Lower TCO?
For a long time, SAP has continually proposed that HANA has a lower TCO than other database vendors. This was proposed by Jon Appleby (who is an SAP surrogate).
“I don’t want to get into detailed pricing debates on a blog, but I help customers implement SAP HANA every day, and it’s less expensive than Oracle, period.
Firstly, it’s available at a lower % of your SAP software estate than Oracle – so you will actually get a license payback if you implement HANA. Sure, that’s different to ROI, but it’s a nice place to start. For any apps where you don’t want to implement HANA, SAP throw in SAP ASE included in the price. And remember that if you buy S/4HANA in 2015, you will get all the future innovation included for the price of the SAP Business Suite on HANA runtime license last year.”
It appears that SAP is bundling ASE with HANA. But is this not contradictory to SAP’s argument about all non-columnar databases and all non-in memory databases being worthless? Is the argument that SAP will throw in ASE, a standard RDBMS design that can be used to replace Oracle, DB2, or SQL Server?
A Confused Argument
I thought the argument was that Oracle, DB2, and SQL Server had to be replaced because they aren’t 100% in memory and 100% columnar. Then SAP offers a non-in memory and non-columnar database with HANA?
SAP’s HANA runtime license is a highly deceptive method of slipping HANA into a company at a low cost, which will convert to a very high cost after it has been connected to another system. Therefore, the fact that future innovations are “included in the price” of the runtime licenses is just about the most deceptive thing I have ever heard. John Appleby assumes his customers are stupid and that he can trick them.
Whatever Jon Appleby is talking about here, the result is that HANA is far more expensive than the other options.
HANA 2.0
“There is one more specific point. SAP has released HANA 2.0 and standard support for HANA 1.0 will cease in 2019. This means that existing Business Suite and Business Warehouse customers running on HANA will need to upgrade HANA versions and, possibly, there will also be Linux version upgrades required, which will often be side by side appliance upgrades rather than in-place upgrades. As we shall see, this represents a recurring theme whereby SAP effectively forces users to upgrade between incompatible or semi-compatible versions of the same product. This is not just exploitative on the part of SAP, it illustrates the fact that these are not mature offerings. In our view, users would do better to wait before making any SAP investment decisions with respect to SAP HANA.”
And how does this upgrade impact the TCO? It puts it sky-high. Secondly, there is no performance justification for using HANA. Therefore this is money that the IT department is essentially flushing.
For a long time, SAP has continually proposed that HANA has a lower TCO than other database vendors. This was recommended by Jon Appleby (who is an SAP surrogate).
“One of the things which is great about working with HANA is that innovation comes seamlessly and often. There was a time when HANA updates came too often, but that pace has slowed over the last 18 months with two major releases a year, verified for datacenter usage. There are some more frequent updates for early adopters or those testing new functionality, but for most, it’s now possible to get great innovation every 6 months with minimal disruption.”
Seamless Innovations
First of all, these “innovations,” which are changes to HANA, are anything but seamless. They are filled with seams. The primary seam being that all HANA customers will have to upgrade to HANA 2. That is a pretty big seam. And all of these “innovations” bring HANA closer to what Oracle 12c, DB2, and SQL Server can do already.
Also, let us get real. These “innovations” are simply the product being developed. They are not things that other database vendors don’t already have, so they do not classify as innovations.
In this case, the term innovation was used to justify the fact that HANA is less stable. HANA has a much shorter history than Oracle 12c, DB2, or SQL Server. It would be like someone building a boat with no advantages over another boat, stating that because they are still building the boat and the other boats are finished, the first boat builder is engaging in more innovation.
No, they would be engaging in boat building.
The HANA Platform
“In fact, the SAP HANA Platform includes all of SAP’s major databases. That is, SAP HANA, SAP Adaptive Server Enterprise (previously Sybase ASE), SAP IQ (previously Sybase IQ) and SAP SQL Anywhere (also previously from Sybase). Of these, the product most likely to be used in conjunction with SAP HANA is SAP IQ. This is included within SAP BW (Business Warehouse) along with SAP-NLS (Near Line Storage solution), which provides the ability to transfer data from HANA to SAP IQ in an environment where SAP HANA is used for operational analytics while SAP IQ is used as the enterprise data warehouse. HANA 2.0 provides what SAP calls dynamic data tiering, to be used in conjunction with SAP IQ, but this is a relatively new release and it does not appear to be as capable (yet) as the proven and more mature offerings available from AnyDB vendors.”
While Bloor does not get into this point, it is worth asking, what does the vast majority of this have to do with HANA?
All of this is part of SAP’s overall strategy to use HANA to penetrate the database layer at customers with many database products that don’t have anything to do with HANA but are marketed as a combined brand.
For example:
- SAP IQ is marketed as the archival database to HANA. But SAP IQ is another column-oriented design, like HANA, so it is a strange archival choice.
- SAP Adaptive Server Enterprise is another Sybase product that was developed many years before HANA.
- SAP BW was also developed before HANA. It is one of the few natural fits for HANA as it is a data warehouse; however, why would it be part of a HANA Platform? It makes no sense and reeks of marketing commingling.
Bloor on the Adaptive Server
Bloor’s statements regarding IQ and Adaptive Server’s long-term future are accurate.
IQ is in decline, and Adaptive Server is in one of the steepest declines I have ever seen at DB-Engines. This is a site that estimates database popularity.
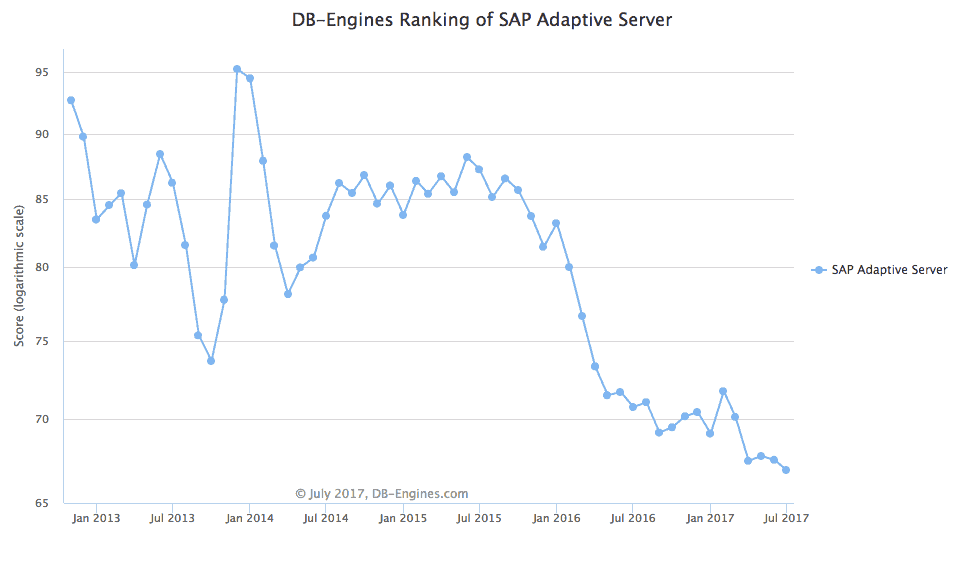
A good reason not to get acquired by SAP.
Hadoop for SAP BW EDW Archiving
“Conversely, SAP is now positioning both VORA and Hadoop (MapR) technologies as SAP BW EDW archiving tiers, thus creating further data platform choices and, potentially, IT operational complexity.”
Why would any company need SAP to connect anything to Hadoop? All of the technologies related to and connected to Hadoop are open source. If SAP is saying that you need to involve them in connecting to Hadoop, then someone at SAP provides some inaccurate information.
Companies that can keep SAP away from archiving will be better off as this has never been SAP’s strength. I have yet to hear anyone else proposing Hadoop for BW archiving. But if anyone knows differently, please comment.
Bypassing Technology Specialists to Target C Level Executives
“…discussions we have had suggest that SAP is putting significant pressure on companies to do this. On an a priori basis the key issues here are..”
- a) whether you will get significant price/performance benefits from this migration, and
- b) whether those putative benefits will outweigh the costs of that migration. Leaving other considerations aside, the answer to the first question is “it’s unlikely,” and the second question is “no chance”.
“And this is not just our opinion: if you are a C-level executive just ask your own IT staff about their opinion. We would lay long odds that they will agree with us. In fact, it is clear from discussions we have had on this topic, that SAP is targeting C-level executives, and bypassing IT SAP solution and/or client architectural teams, for precisely this reason.”
Right. The worse the value, the less the solution makes sense. The more you need to remove the process from those that can evaluate and validate the information provided. This is the standard practice employed by vendors that know they have a weak value proposition.
“…is further worth commenting that SAP’s “Simplification List for S/4 HANA” runs to 408 pages! Particular note also has to be taken if SAP Industry Solution (such as IS Utilities) functionality has been developed and deployed beyond S/4 Simple Finance and/or Simple Logistics.”
Brightwork has pointed this out in the article How to Best Understand the S/4HANA Simplification List. The term “simplification” applied to a list as complex as this list is is the term simplification as merely a term of propaganda. That is how the US Congress names bills that have the opposite outcome from what the bill is named.
Column-Oriented Rows
“Data may be held in columnar format. This is not an all or nothing choice. Where it makes sense to use columns you can use columns and where it makes sense to use rows you can use rows combined with conventional indexes. Column-organised tables do not have secondary structures, such as materialised query tables, thereby eliminating any need for synchronisation. If you are looking for the sort of HTAP-based environment discussed previously then we believe that this is a more complete solution, albeit that Db2 with BLU does not formally meet the definition of HTAP.”
Yes, SAP makes it seems as if they are the only vendor that offers a database that can store data in a columnar format. This is, as noted above, incorrect. IBM DB2 can do it. Oracle 12c can do it. SQL Server can also do it. And while SQL Server is well regarded as a good value database, I don’t know anyone who considers it an innovation leader. Here is the quotation from SQL Server’s documentation on the columnar store.
Here is the quotation from SQL Server’s documentation on the columnar store.
“The columnstore index in SQL Server 2012 stores columns instead of rows, and is designed to speed up analytical processing and data-warehouse queries. Whilst columnstore indexes certainly do that effectively, they are not a universal panacea since there are a number of limitations on them. When used appropriately, they can reduce disk I/O and use memory more efficiently.”
Therefore if all the database vendors that are options for SAP can do this, and if all the database vendors that are options for SAP can use SSD and RAM in as much volume as necessary, what is HANA’s advantage?
IBM’s Memory Assumption
“Unlike SAP HANA, which has been designed purely to provide in-memory capability, Db2 with BLU Acceleration has been designed on the premise that your environment will always exceed the amount of memory available. Of course, you can always pay significant amounts to have perhaps hundreds of terabytes of memory, but that is organisations.”
Yes, SAP has the least sophisticated interpretation of the interaction between memory and databases than SAP’s database competitors.
John Appleby stated the following back in 2013 on this topic.
“All three of the major RDBMS vendors have released in-memory add-ins to their databases in the last year. All of them support taking an additional copy of data in an in-memory cache, or in IBM’s case columnar tables. All of them provide improved performance for custom data-marts. But make no mistake; caching data has been around for a long time, while an in-memory database platform to run transactions and analytics together in the same instance is a new innovation.
Traditional database caching solutions are similar to the GM and Ford response to hybrid cars – take their existing technology and bolt new technology to it. SAP HANA is more akin to Tesla, who rebuilt the car from the ground up based on a new paradigm.
And so HANA’s capabilities from a business application perspective are 3 years ahead in technology from what others have.”
That is curious because none of these proposals by SAP/John Appleby seems to allow HANA to compete with Oracle 12c in either benchmarking or feedback from the field. And by the way, John, how many cars does Tesla sell in a year?
Is the Tesla Analogy Accurate?
Right. However, even if the Tesla analogy were correct, it may not necessarily apply to HANA. For instance, I could say that HANA is just like cold fusion. That is a lot of hype with no benefit. But have I proven anything by saying this? No, I have not. Analogies only work if the person offering the analogy is not intent on misleading the listener.
Caching Data
Caching data has been around for a long time, and it works very well. The fact that something has been around a long time is not an argument against it, and it is an argument in favor of it. Things that are around for a long time work. Moving all of the transactions and analytics together is infeasible because databases don’t work that way. If John Appleby does not know this, then he should not be writing about databases. Because it is infeasible, it is not an innovation (check the definition of innovation, it must be a positive contribution). As is pointed out in the article, What is HANA’s Actual Performance, SAP has never released a benchmark for HANA transaction processing? It is the speed demon on transaction processing that John Appleby claims. Why not? Furthermore, results from the field show that HANA has a performance degradation in transaction processing.
Hasso Plattner Congratulating John Appleby for Distributing False Information on HANA
Is it possible that John Appleby exaggerated HANA’s benefit in return for something of value provided to him by SAP? SAP implementations, perhaps? We know one thing. Hasso really really liked John Appleby’s articles.
“WELL DONE JOHN (and your team)!
HANA is just too good to be missed. I am currently working on a mixed system configuration, using both a SMP system for scale up and a cluster for scale out. We wont have any size limitations any more pretty soon.
The technical conversion of large ERP systems to ERP running on HANA is relatively easy and fast, but to check all the modifications and extensions unfortunately will take some time. Many large projects have started and I am very pleased, that You talk about Your experience all the time. I understand that customers are afraid of switching the database they are used to for many years. But at least they should really know what they might be missing.” – Hasso Plattner
Yes, when you mindlessly agree with everything Hasso sends over to you and serve as a passive repeater, you get a lot of positive feedback.
AnyDB Versus HANA
“SAP has been emphasizing the performance advantages that this brings to S/4 and HANA without mentioning that AnyDB support for CDS means that those users should get the same benefits that SAP Business Suite clients. The key issue here is that as SAP re-optimise many millions of lines of ABAP SAP Business Suite application code for HANA, databases like Db2 and/ or Oracle then leverage CDS in ways that result in significant performance benefits for existing SAP Business Suite users with AnyDB solutions.”
Right. SAP has proposed that only HANA can take advantage of the rewritten S/4HANA code. They do this when they state that S/4HANA has been optimized for HANA. But has it? As Bloor points out, it is optimized for AnyDB that can also have some columnar table capability (one does not need all the tables to be in columns as SAP states). A second argument used by SAP is that they cannot make S/4HANA run on AnyDB because they use stored procedures, which is code moved from the application layer to the database layer. Yet, there is no reason this code could not be either put back into the application layer or moved into AnyDB. IBM, Oracle, and Microsoft would be more than willing to help SAP do this. There is no technical reason why S/4HANA is limited to HANA. There is, however, a commercial reason, as covered in the article Why SAP Will Have to Backtrack on S/4HANA.
Performance Improvement from HANA?
…the bottom line is that if you have a performance issue it may be because you have not explored all the options. Migrating to SAP HANA for this reason is, in our opinion, unlikely to be the best option. It also depends on where the performance issue is. For example, our understanding is that HANA will not do much for you, in particular, if have you have long running batch processes and/or database intensive z code.
Right. But I think the evidence shows this is too optimistic. HANA will provide a performance degradation over at least Oracle 12c. I cannot say with as much confidence regarding DB2 and SQL Server, not because I think HANA would beat them, but simply because I have not researched those databases as I have Oracle 12c. But results from the field demonstrate that HANA only does one thing well — which is read, which is why its only application is analytics.
Migrating to S/4HANA
“To summarise, the only good reason, as we see it, to migrate Business Suite to SAP HANA, is that you intend subsequently to migrate to S/4 HANA.”
Hmmm…perhaps. But HANA comes with indirect access overhead, which should be a major concern. Secondly, what IT department would allow their application vendor to dictate which database they would be using? Also, why would you purchase a database from a vendor that had so aggressively misled you on the features of that database?
The rest of the Bloor paper deals with S/4HANA, so that we will cover that part of the white paper in a separate article.
Conclusion
Even though IBM funded this research, I cannot find any inaccuracy in the white paper. I have been a reasonably long time researcher of HANA, and I learned several things from the white paper. Bloor (Philip Howard) did an excellent job of synthesizing information about HANA and presenting this information. Some of the information presented in this article I have not seen presented elsewhere. I estimated that Philip was given proper access to several IBM DB2 resources who know that product. I am also chuckled to myself when reading it because I think the IBM DB2 group is sick to death of SAP’s exaggerations on HANA and finally fought the political battle necessary to get this research funded. Since HANA first came out, I imagine the DB2 group was told to shut up instead of offending SAP.
The only area where the bias shows is that all of the comparisons are to IBM. Yet Bloor and IBM certainly know that many of the statements that apply to DB2 also apply to Oracle and SQL Server. But they choose to focus on IBM because IBM funds the paper, which is their area of expertise. (I do this myself because most of my research into the competing product for HANA is in Oracle 12c) That does not mean there is any inaccuracy, but it brings up the reason for the omission. But Bloor does moderate this by consistently using the term “AnyDB,” which broadens the research finding to non DB2 databases.
Bloor receives a score of 9.5 out of 10 on their white paper.