
How to Build Up to a DP InfoCube
Executive Summary
- To use DP, it is necessary to create a DP InfoCube, which is done from the DP WorkBench and uses InfoObjects and master data bearing characteristics.
Introduction
The DP workbench (RSA1) contains many data holding and data management elements. This post identifies and discusses them (since “characteristics” are used so often in this post and is a lengthy word, sometimes we have shortened it here to “charac”).
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Notice of Lack of Financial Bias: We have no financial ties to SAP or any other entity mentioned in this article.
- This is published by a research entity, not some lowbrow entity that is part of the SAP ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on SAP is provided by SAP, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, SAP pays off all IT analysts -- who have the same concern for accuracy as SAP. Not one of these entities will disclose their pro-SAP financial bias to their readers.
InfoObjects
Master data and transaction data are called InfoObjects. They are used throughout the system to create structures and tables where data is stored. They enable information to be modeled in a structured form. They are also used to defined reports to evaluate master and transactional data. InfoObjects are the most basic data form and are the smallest available information modules or fields in BI. These break into the following:
- Key Figures (for example, revenue) – Form a frame for many data analyses and evaluations.
- Characteristics (for example, customers) – used to analyze key figures.
- Time characteristics (for example, fiscal year)
- Units (for example, currency or amount unit)
- Technical characteristic (for example, request number)
What Are InfoObjects?
They are the bread and butter of DP. They are characteristics and key figures. You can think of the column headings’ characteristics on a spreadsheet and key figures as the actual values underneath the column headings. Time (fiscal year) is a characteristic.
What Are They Used For?
To create structures and tables where data is stored.
Interesting Feature
What is interesting about creating InfoObjects (key figures and characteristics) is that they are not created where they intuitively should be created. First, the InfoObject Catalog needs to be created. This is done by right mouse-clicking an InfoArea and selecting – Create InfoObject Catalog. Next, you are taken to this screen to view the in-process InfoObject Catalog (in this case, it’s a catalog for Key Figures). However, you don’t create the new InfoObject by right mouse-clicking here. Instead, you go back to the InfoArea and right mouse click. (You need to select the InfoObject Catalog where you want the new InfoObject) Then you can begin setting up the InfoObject.
Master Data Bearing Characteristics
A characteristic is master data bearing if it specifies that table attributes, texts, or hierarchies are linked to providing additional information. You enable master data bearing characteristics by selecting the appropriate checkbox for text.
Four tables are created when a master data bearing characteristic is created:
- Attribute tables
- Text tables
- SID tables
- Hierarchy tables
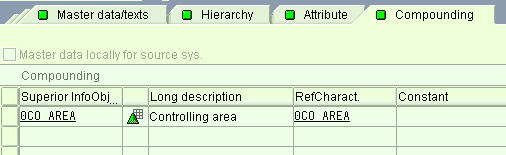
Compounding
Compounding is combining a characteristics InfoObject with another characteristic InfoObject to ensure the ability to define the InfoObject uniquely.
This tab determines whether or not the characteristics are to be compounded to other InfoOjects. It would help if you often compounded characteristic values to enable characteristic values to be uniquely assigned.
This is set in the Characteristic Compounding Tab.
Attribute Info Objects
These are charac or key figures that are used to describe charact in greater detail. The charact cost center can be described in more detail with the profit center and person responsible for information about the cost center. Like the compounding tab, attributes have their tab on the characteristic. Attributes themselves are InfoObjects. You can define attributes as either:
- Display attributes
- Navigation attributes
If attributes are defined as navigational, they can be used to navigate in reporting. When a query is executed, the system does not distinguish between navigational attributes and characteristics for the InfoProvider.
Hierarchy Tab Page
“These are used in the analysis to describe alternate views of the data. They serve a grouping function just as they do in other SAP products like ECC. A hierarchy consists of several nodes and leaves, forming a parent-child relationship. The nodes represent any grouping you desire, for example, the west region. The leaves are represented by charac values. On the Hierarchy tab page, you determine whether or not the characteristic can have hierarchies. A characteristic can have more than one hierarchy.” – SAP SCM 226 Training Material
Hierarchies can be time dependent as well. There are different versions for this hierarchy that are valid for a specific time interval only.
DataSource
Replication is the process of accessing DataSources and mapping them to InfoProviders in BI.
InfoProviders
InfoProviders are objects into which data can be loaded, and queries can be created or executed in BEx. There are two types of InfoProviders.
- InfoCubes and DataStore Objects (which contain physical data)
- InfoObjects (characteristics with attributes) A characteristic can be an InfoProvider.
InfoCube
An InfoCube is a set of relational tables with a fact table in the middle and per the star schema.
An InfoCube is a primary object used to provide historical data to APO DP. The goal is to design a warehouse is to ensure that most queries initially target this type of database object. They are designed to store summarized and aggregated data for long periods.
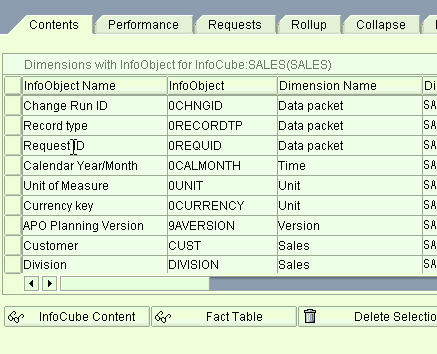
A BasicCube is the main InfoProvider you will use in conjunction with APO DP. An InfoCube consists of one fact table in which key figure values are stored. An InfoCube has a minimum of 4 dimension tables and a maximum of 16. Although SID tables are also part of a characteristics InfoObject master data, they are only important from a technical perspective.
There are two subtypes of InfoCubes:
- Standard (for pure read access)
- Real Time (optimized for direct update and do not need to use the ETL process)
An InfoCube can be managed by right mouse, clicking it, and selecting “manage.”
This brings up the manage view, the first tab of which is the contents tab.
A Virtual Provider
A VirtualProviders is a data provider for which the transaction data is not saved.
A MultiProvider is a type of data provider that combines data from several InfoProviders and makes it available for reporting.
DataStore Object is an object that stores consolidated and cleaned transaction data on the document level (basic level). DataStore Objects often describe a consolidated data set from one or more InfoSources.
InfoSet
This is a semantic view of a DataStore object.
Source systems provide data to the BI. (ECC, BIW, APO livecache, flat files, legacy)
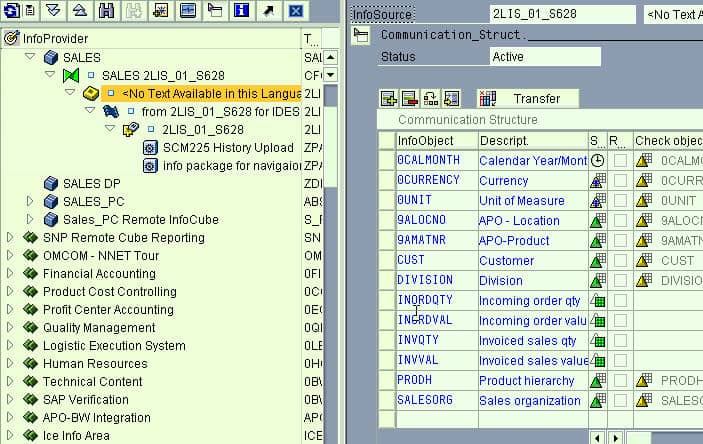
DataSources subdivide the available data into a source system. The DataSources are used to transfer master data and transaction data. Once the transfer structure has been replicated to SAP BI, you need to create an InfoSource. An InfoSource is some InfoObjects that belong together, containing all the information on a business process. Transfer rules connect the transfer structure to the communication structure. The structure where the InfoObjects are stored is called a communication structure.
InfoSource
Once a transfer structure has been replicated to SAP BI, you need to create an InfoSource. An InfoSource is several InfoObjects that belong together, containing all the information on a business process.
There are two types of InfoSources:
- Infosource with flexible update
- Infosource with direct update
The InfoSource may contain both transactional and master data.
Update Rules
(Bowtie icon) Connect the communication structure to the BasicCube. The update rules specify how the data (key figures, time characteristics) are updated from the communication structure in an InfoSource to a data target. Update Rules are specific to the data target, not the source system.
Normalization
The process of removing repeated data from the table to auxiliary connected tables, thereby making the original tables much smaller. OLTP’s normalization design problems preclude it from being used to support complex, ad hoc data analysis. As illustrated in the following figures, the classic star schema is the most frequently used multidimensional model for the relational database. This database schema classified two groups of data: facts, dimension attributes. Facts, sometimes called measures, are the focus of the analysis for a business process.
Infopackage
This BI object contains all the settings directing how this data should be uploaded from the source system. The target of the InfoPackage is the PSA table tied to the specific DataSource associated with the InfoPackage. The InfoPackage sits between the Source System and the DataSource; the transformation occurs after the DataSource.
In a complex BI solution, you need many InfoPackages to load your master data and transaction data. Therefore, InfoPackages are usually grouped and scheduled using BI Process Chains.
The data flow design uses metadata objects such as DataSources, Transformations, InfoSources, and InfoProviders. Once the data flow is designed, the InfoPackages and Data Transfer Processes take over to manage the actual data transfer execution and scheduling.
The first tab of the InfoPackage is data selection. The headers show the InfoSource, DataSource, and the Source System.
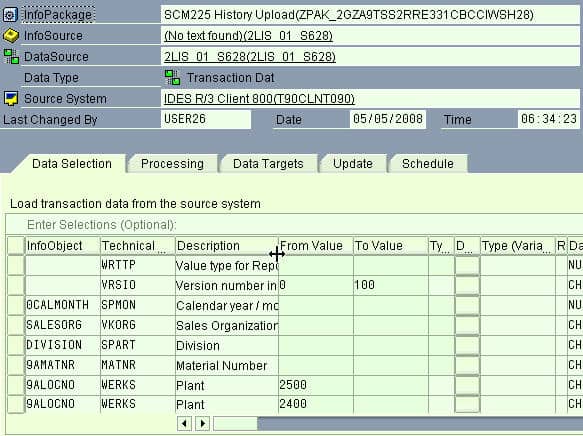
The second tab is the Processing tab, where you set the relationship between the PSA and the data targets and where you want the data loaded.
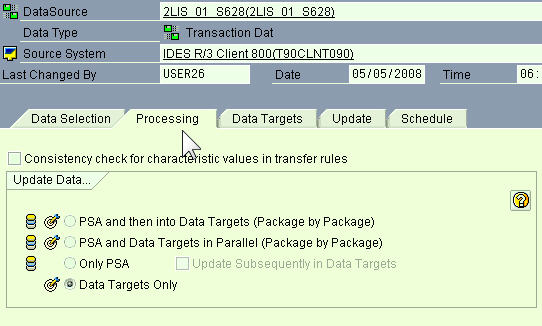
The third tab is the Data Targets tab, and in this case, it shows the InfoCubes that will finally receive the data.
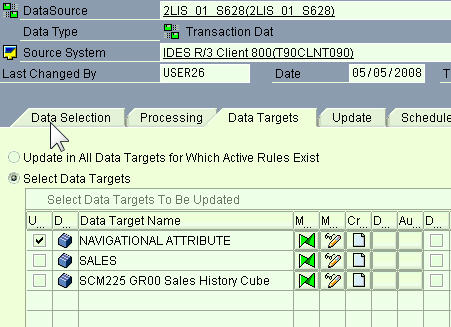
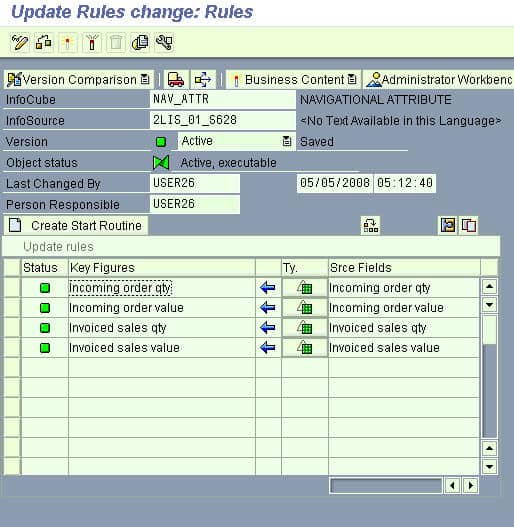
You can select Update rules and be taken to that screen by selecting the green “bowties.”
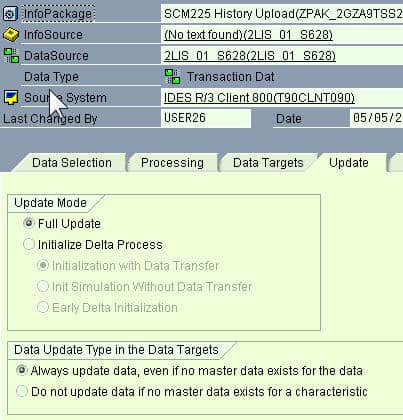
The fourth tab is the Update tab.
The fifth tab is the scheduling tab.
The Update Rules also have a communication structure. This shows the fields linked to the cube. As you can see, the communication structure is below the Update Rules in the Data Warehouse Workbench.
Data Transfer Process
After the InfoPackage is the actual Data Transfer Process. It is this object that controls the actual data flow for a specific transformation. As of 7.0, it no longer became necessary to distinguish between the two different types of updates. The DTP is designed to execute a transformation, making sense that you would use the context menu on a transformation to create the data transfer process. The DTP contains the settings for the Extraction Mode (delta or full). The DTP provides a light-based system to visualize your success or analyze the causes for your failure.
Transformation Rules
Most transformations are simple field mappings. Complex transformations can be performed with the formula builder. A rule group is a group of transformation rules, and it contains one transformation rule for each field of the target. A transformation can contain multiple groups.
Master Planning Object Structure
This is a table created via APO functionality but stored in the BI environment. With the POS, you identify the characteristics that will be used for planning the DP process. POS aims to store the master data to allow DP to function as a consistent planning system. This master data is called CVCs. The POS stores every unique combination of CVCs. This will be used to help control disaggregation when data is manipulated at summary levels.
This cube is different from the typical InfoCube in that it is a write efficient structure, while most BI cubes are read efficient structures. However, in terms of structure, they follow the same rules, and you can apply the same rules of thumb.
Planning levels are determined in the POS.
InfoSet
A semantic view of a DataStore Object. In the InfoSet builder, InfoSets are created and changed.
Data Object Structure
A DSO is a storage location for consolidated and cleansed transactions or master data, evaluated with a BEx query. Unlike an InfoCube, the DSO is stored in transparent flat files. It is used for the cumulative update of key figures; unlike InfoCubes, you can overwrite data fields.
Planning Books
Planning books should be designed based on roles. Activities such as forecasting and promotion planning and proportional factor maintenance are defined at the book level.
Core Interface
The Core Interface is a plugin R/3 or ECC.
Master Data
SAP BW characteristics (texts, attributes, and hierarchies)
CIF master data (product and location master sets, BOMs, routing, etc.)
Demand planning master data (characteristic value combinations)
POS characteristics determine the level at which demand plans are created, changed, aggregated, and disaggregated.
CVCs can be in the millions. It is thus impossible to generate CVCs manually. They have been created from historical data in InfoCubes or ODS objects through remote cubes, flat files, or realignment. CVCs are saved in APO InfoCubes called POSs.
If you do not want to work with default characteristics 9AMATNR and 9ALOCNO, define your own characteristics for product and location in the internal BW and load the master data. This is especially necessary when you want to work with navigation attributes for product and location. SNP does not support the use of navigation attributes.
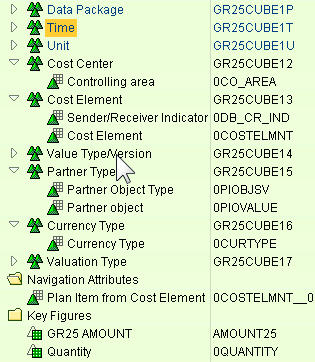
Navigation Attributes
Used for selection and navigation in demand planning. Set up the navigational attribute in characteristics info object in the internal BW. As soon as you store the POS characteristic, the navigation attribute is available for demand planning. You can use them to navigate the cube. When a query is executed, the system does not distinguish between navigation and characteristics.
Attributes can be made time-dependent if a validity period is required for each attribute value. The feature is powerful and allows one to perform reports based on how master data existed at any point in time.
- Navigation attributes have a negative effect on performance (due to the creation of multiple joins)
- CVCs do not contain navigational attributes.
- You cannon assign navigational attributes to promotions.
- Both navigational attributes and basic characteristics can be used during data extraction.
They can be found by looking at the Navigational Attributes folder in the InfoCube screen.
Aggregates
You define aggregates for the POS for demand planning. APO aggregates contain a part of the POS for demand planning. APO aggregates contain a part of the POS’s characteristics. Without aggregates, data is only stored at the lowest level. APO aggregates are not identical to BW aggregates but fulfill the same task. Aggregates are defined in the aggregation tab of the Key Figure.
“Objects are known as InfoProviders in BI when queries based on them can be benefits. Aggregates rules are set on this tab page for the key figure’s behavior when data gets stored in tables in BI and BEx reports. The aggregation behavior determines whether or not and in which way the key figure values can be summarized using different characteristics” – SAP SCM 226 Training Material