
Can Anyone Make Sense of the DMSA and ODMS Magic Quadrants?
Executive Summary
- Gartner produced a database magic quadrant that places all manner of entities in strange comparisons.
- Gartner’s DMSA and ODMS MQs make no sense without $$$.

Introduction
Gartner produces highly unusual Magic Quadrants. One is called the Data Management System and Analytics (DMSA), and the other is the Operational Data Management System Magic Quadrant (DMSA) MQ. This article will review these bizarre MQs and assign an accuracy rating.
Gartner’s DMSA MQ
These facts make it confusing what type of database is being compared. As discussed, that is only the beginning of the problem with this MQ.
These are not all database types but some of the major ones.
- Relational/RDBMS
- Key-ValueDocument
- Graph
- In Memory
- Search
If you look at how DB Engines lists databases, they always declare the database type.
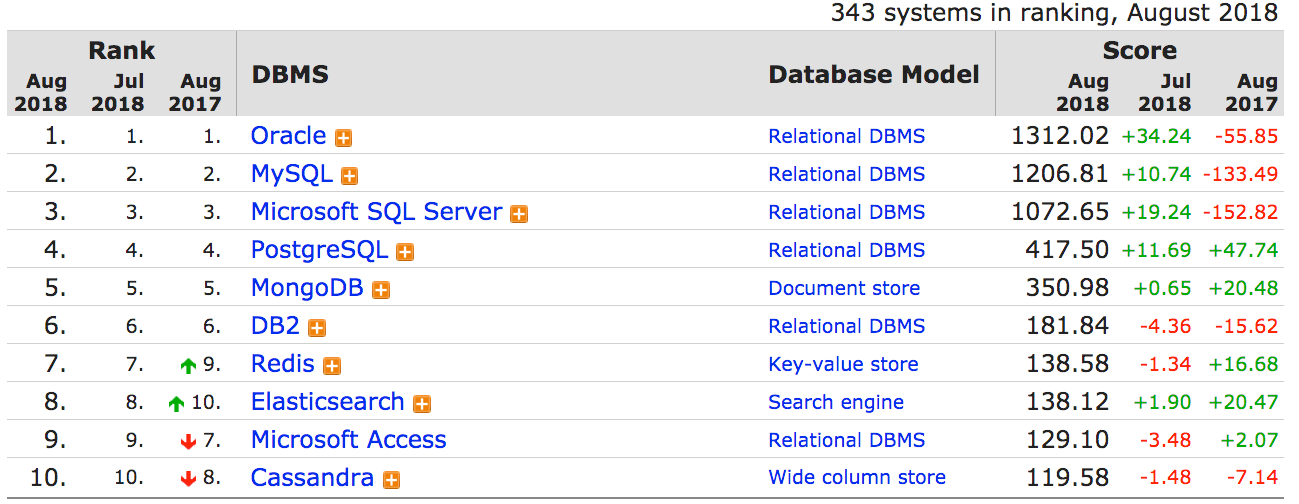
See the Database Model column. DB Engines lists the type of database or declares whether it is a mixed type. Some databases can combine more than one type into one database.
Hmmmmm…..Different Database Types for Different Purposes?
The different database types apply for various purposes. For this reason, they aren’t directly comparable unless they are in the same or a related variety. We have gone through a period where the number of database types has increased significantly, which will also mean a less dominant use of RDBMSs in the future. A significant factor driving this increase in database types being accessed is the DaaS providers like AWS, Google Cloud, and Azure that allow customers to spin up databases and test them at a meager cost. If the database is not desirable for the purpose, the database can be quickly deactivated, and the charges cease.
The DMSA MQ
Now, let us review how Gartner decided to lay the MQ.
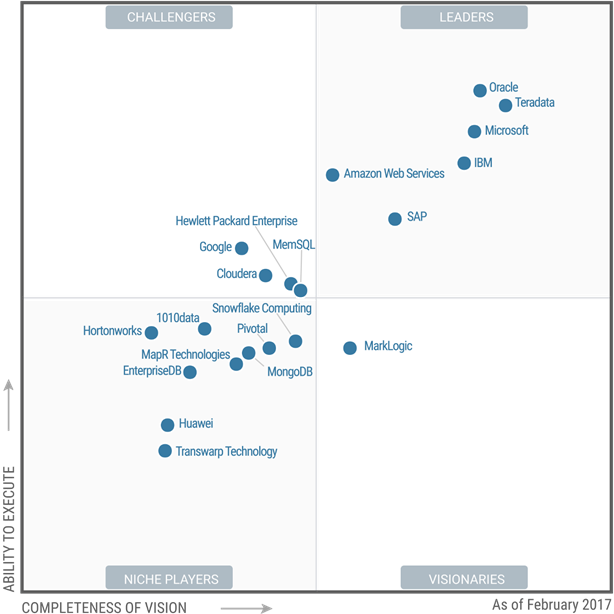
Two problems become apparent immediately. One is that the databases being compared are unclear. Second, why are different database types listed in the same MQ in the first place?
Which Database Is Being Compared?
The MQ includes a jumble of vendors, except the database is not mentioned in only a few cases. For example, we can guess that when Gartner states Oracle, they refer to the Oracle RDMBS DB (Oracle 18, Oracle 12, or Oracle 11). Oracle also has several other databases, but Oracle is only dominant in one database type, the relational/RDBMS. There is just a stunning lack of specificity in this MQ.
The Databases in the Magic Quadrant
The upper right, the so-called “magic” quadrant, is the most desirable quadrant.
If we stay up where Oracle is, we can see Teradata. Teradata also is categorized as an RDBMS, but it is highly specialized. Teradata’s specialty is called massively parallel processing, and if a customer is not looking for a data warehouse, Teradata will not be used. Oracle’s RDBMS, on the other hand, is also used for data warehouses, but it is a more general RDBMS. Therefore, it makes sense to compare Oracle RDBMS to Teradata as it has an RBDMS, but not without mentioning the context of the application the database is being put towards.
Microsoft’s primary database is SQL Server. This is another RDBMS; like Oracle, RDBMS is highly generalized in its use. Then we move to IBM, which has DB2 and Informix, both RDBMSs. DB2 is far more widely used than Informix, so is Gartner discussing DB2 here or Informix? We will assume it’s DB2.
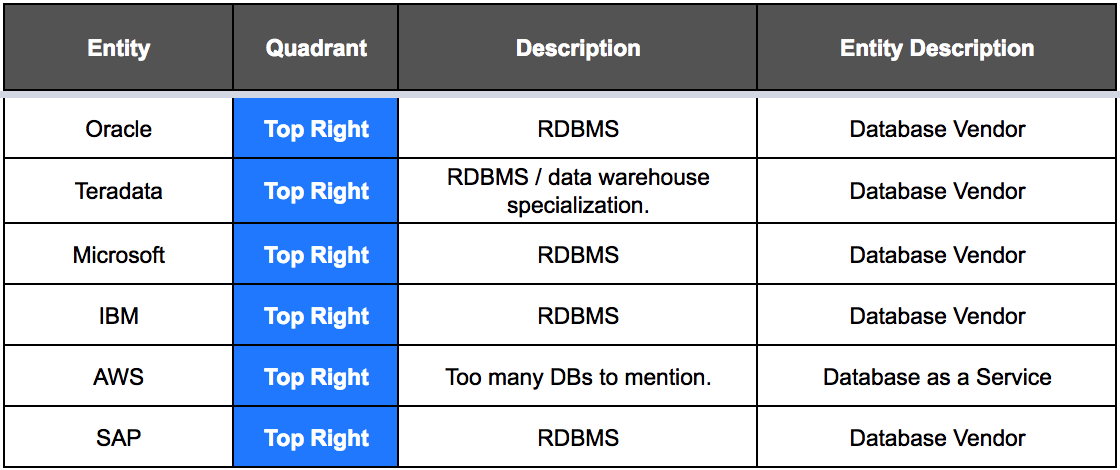
The following two closest companies are AWS and SAP. AWS is a particularly problematic comparison. AWS has databases like DynamoDB, Aurora, and Redshift, but it provides services for many databases. Here, the contrast created by Gartner ultimately falls apart. Not only does AWS provide its databases, but it also hosts the other databases in the MQ!
- So, what is AWS’s rating if the Oracle database is brought up on AWS?
- Oracle also tries to get companies to place the Oracle DB on Oracle Cloud. However, the Oracle Cloud is abysmal, and there are more Oracle DB instances on AWS than Oracle Cloud.
- So, if AWS is included in the analysis and is primarily a database service provider, then what is Gartner comparing exactly?
The top right “magic” quadrant is rounded out by SAP, which offers HANA and Adaptive Server (which SAP barely markets versus HANA but is more widely used than HANA). These are RBDMS, with HANA being a hybrid of RDBMS + column store/in-memory. They also offer…
- SQL Anywhere
- IQ
- Advantage Database Server. (Adaptive Server, SQL Anywhere, IQ, and Advantage Database Server were all Sybase DBs.)
The last three of which have a niche market share.
So what can be taken from looking at what Gartner values?
If we exclude AWS as an outlier to the group, Gartner thinks that RDBMSs are the best type of database for “data management and analytics.” How do we know this? This can be surmised because most of the RDBMSs in the MQ is in the top right quadrant, and 100% of the entities listed in the top right “magic” quadrant are RDB vendors, with Teradata being the same the same a particular case a provides a specialized data warehouse database.
The Bottom Right Quadrant
Let us look at the bottom right quadrant.

The only entity in the bottom right is MarkLogic. MarkLogic is a very niche database, and as there are only 20 entries in the MQ, it seems odd that it would be included in the MQ.
The Top Left Quadrant
Now, let us look at the companies in the top left of the MQ.

MemSQL is not a frequently discussed database, and this should be unsurprising as it is the 73rd most popular DB, according to DB Engines. Like 1010data, which we will discuss in a moment, it is a database with a very low profile. Hewlett Packard Enterprise is simply a consulting company. Yet, according to Gartner, they are the 9th most essential or magic “database” that should be in an MQ? HPE’s website shows its products as servers, data storage, software, and applications. Under software, they offer…
- Hybrid cloud management software
- Infrastructure management software
- Network management software
- Server management software
They also claim to have the most SAP HANA customers at 2,400. They offer hardware for the Oracle DB and hardware and database as a service for Azure. That is all very nice, but why is HPE in this MQ? It offers Stonebraker’s Vertica, which it bought in 2011, the 27th most widely used database according to DB engines. Interestingly, Vertica is not prominently mentioned on the HPE website.
Cloudera is one of several vendors that add to the Hadoop software ecosystem (Hadoop is not one thing or a database, but rather a constellation of database things). Google is like AWS, a service offering proprietary databases like BigQuery and BigTable. A DaaS that provides a variety of databases cannot be a Magic Quadrant designed to compare different databases. Again, the question of what database is being compared comes up. What database is Google? What database is Google Cloud?
Is this the correct question? Google is a search engine, and Google Cloud is what offers a database as a service to customers.
The Bottom Left Quadrant
Now, let us look at the companies in the bottom left or the undesirable quadrant of the MQ. We will call this the WQ or worst quadrant.
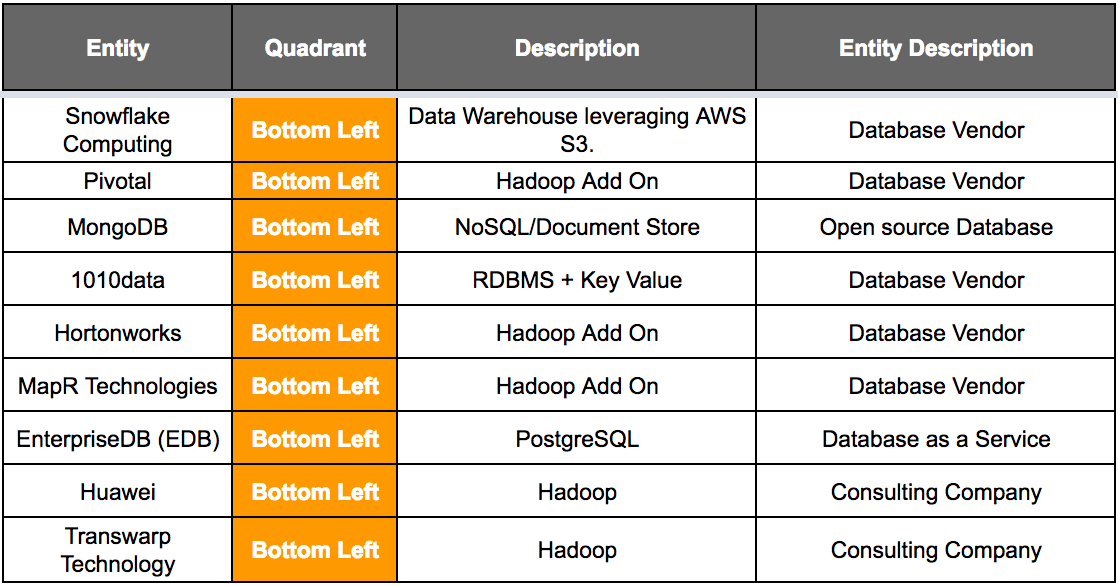
Snowflake only does data warehouses and competes with Teradata. And Snowflake is the 119th most widely used database, according to DB Engines. So should they be profiled in an MQ that has only 20 entries? Well, let us take a look into that, shall we?
Snowflake has raised hundreds of millions of dollars, including $480 million in just 2018, and with that money, you can buy full coverage. Furthermore, Snowflake is rumored to be preparing for an IPO, and the Gartner rating will be used to promote Snowflake to potential investors, which makes Snowflake “highly motivated.” I recently read some complimentary articles about Snowflake in Forbes and know that Forbes takes paid placements, and it got me thinking about whether these articles were paid placements.
Pivotal is a Hadoop+ provider. MongoDB is an open-source document NoSQL database, but it is also a publicly traded company.
According to DB Engines, 1010data is the 142nd most popular database in general use, and we had never heard of 1010data before reading this MQ. 1010data “smells” like a company included because they brought enough cash. 1010data is below HAWQ and above Infobright in DB Engines’ listing, but neither Infobright nor HAWQ nor any other databases around them are in the MQ. None of the databases down this low area in the MQ.
Why?
Well, HAWQ is an open-source database. Infobright is private, but who knows if they were willing to pay? What can explain the selective inclusion of a database like 1010data? Again, 1010data is a very, very lightly used database. How do they rate a ranking in the top 20 of the MQ?
Hortonworks and MapR Technologies are Hadoop+, EDB is a PostgreSQL DaaS, and Huawei and Transwarp Technologies are consulting companies that do not have any offerings or additions to the databases they consult. The question arises again: why are consulting companies that are a) not databases and b) not known even to offer add-ons to databases in the top 20 most crucial database MQ?
The Descriptive Statistics to the DMSA MQ
The following statistics apply to the MQ.
- 5/8 RDBMSs, or 62% of the RDBMSs in the MQ, are in the upper right quadrant, or the magic and most desirable quadrant.
- Two RDBMS entries scored in the worst of the bottom left quadrant. One was an open-source DaaS. And the other is 1010data, which is barely discussed as a database.
- 6/8 NoSQL or 75% of the non-RDBMSs (NoSQL, Hadoop, and Document) are in the lower right or least desirable quadrant.
- 2/20 or 10% of the entries (AWS and Google Cloud) are DaaS providers with many databases and cannot be placed into an MQ like this.
- 1/20 or 5% of the entries are a single database DaaS (EDB), but the comparison should have been PostgreSQL, not EDB. EDB is not a database; it is an access provider and value-added add-on provider, PostgreSQL.
- 14/18 entries (AWS and Google Cloud are removed from this calculation), or 77% of the entries, are associated with an RDBMS or Hadoop. This understates the variety of database types being used.
- Only 0/20 of 0% of the entries are straight open-source database projects. Other open-source entries are not the project itself but one of the value-added services providers for PostgreSQL.
Why Are Different Database Types in the Same MQ?
No distinction is drawn in database type in this MQ. Many different types of databases can’t be compared to one another as they don’t do the same thing. In this MQ, we have MongoDB, a NoSQL DB with SAP, whose primary database is HANA, a mixture of column-oriented and row-oriented design. (But here again, SAP still sells ex-Sybase databases like SAP IQ and the Adaptive Server. Adaptive Server is more popular, so perhaps we should state Adaptive Server is the database.). How can MongoDB, or Cloudera is a distribution of Hadoop, be compared in an MQ against HANA? These databases have different uses and designs.
What the DMSA MQ Tells Us
From this MQ, it is clear that…
- Gartner does not like non-RDBMS entries.
- Gartner does not like open source. Open-source databases are becoming increasingly popular, but Gartner does not notice. No money
- Gartner has no problem placing highly illogical entries like MemSQL, 1010data, Huawei, and Transwarp into their MQ if those entities are willing to pay.
- Very few databases are specifically mentioned. We categorized the entries as Database Vendor, Database as a Service, Consulting Company, and Open Source Database.
The Method of Gartner’s Madness
If one were to analyze this MQ without understanding how Gartner works, the impression is that the overall MQ is entirely insane. But looked at from another way, it makes perfect sense. Gartner receives around 1/3 of its income from vendors. Some of the most commonly used databases are now open source. However, an open-source project cannot pay Gartner anything. This is why Gartner cannot follow where databases are going. The growth is in non-RDBMS and open source. Therefore, instead of rating PostgreSQL (which can’t pay), Gartner rates EBS (which can pay). The same applies to the Hadoop entries. Hadoop is managed as an open-source project. Therefore, Gartner will not rate Hadoop as a database or grouping of database components but instead evaluate companies that charge money on top of Hadoop, like Cloudera, MapR Technologies, and Pivotal. To Gartner, even entities purely consulting companies like Huawei, Transwarp, and HPE (Vertica) warrant inclusion over prevalent databases Redis or Elasticsearch because the former entities are multinationals who can pay. In contrast, the later entities are open-source projects, but they are actual databases.
Gartner’s ODMS Magic Quadrant
Gartner has another database-oriented MQ called the ODMS MQ. This uses the term operational data management system. Reviewing the 2015 version versus the 2017 version of this MQ is instructive.
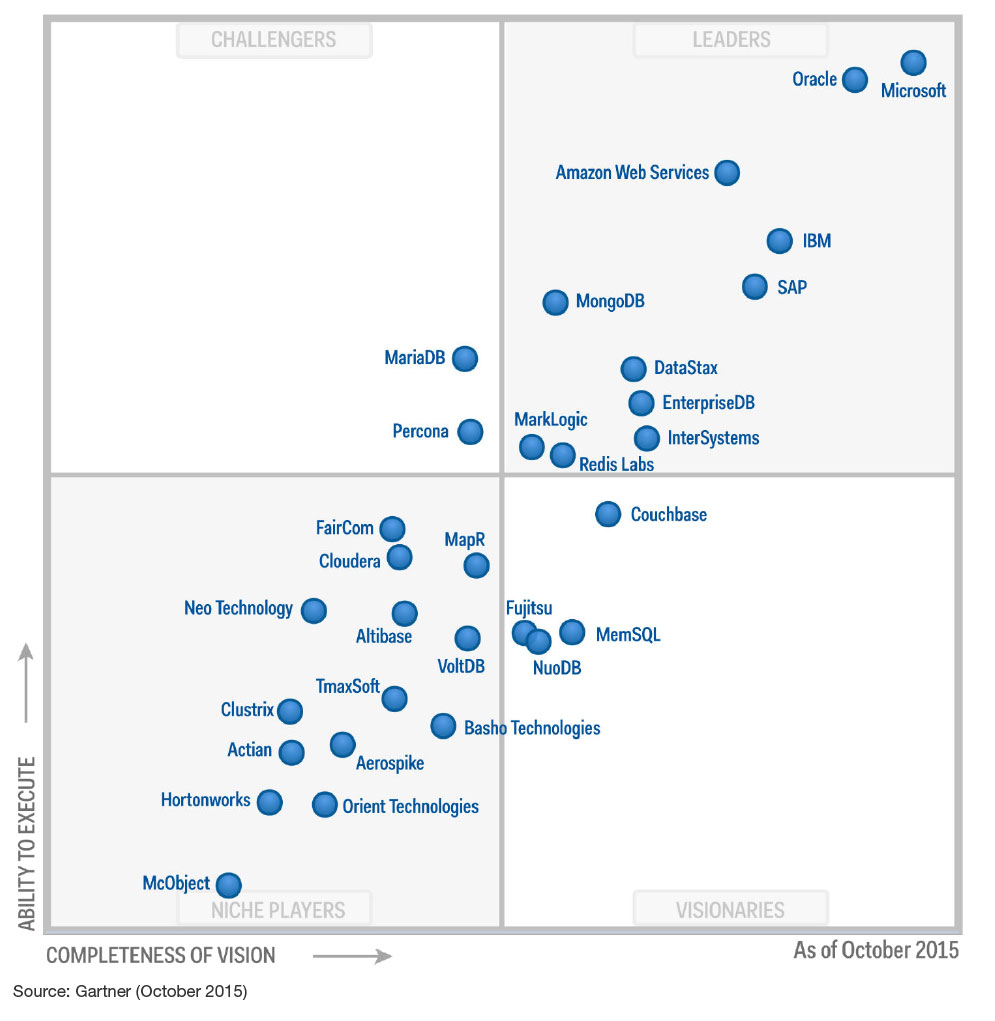
One could go through the same exercise we just did with the DMSA MQ that we did with the OMDS MQ.
Notice the listing of exceptionally lightly used databases like Altibase (they just went open source in 2018 but were closed source at the time of this publication) and Clustrix, ranked 181st by DB Engines. Again, the preference for listing companies rather than databases continues.
Now let us review the same MQ but for 2017.
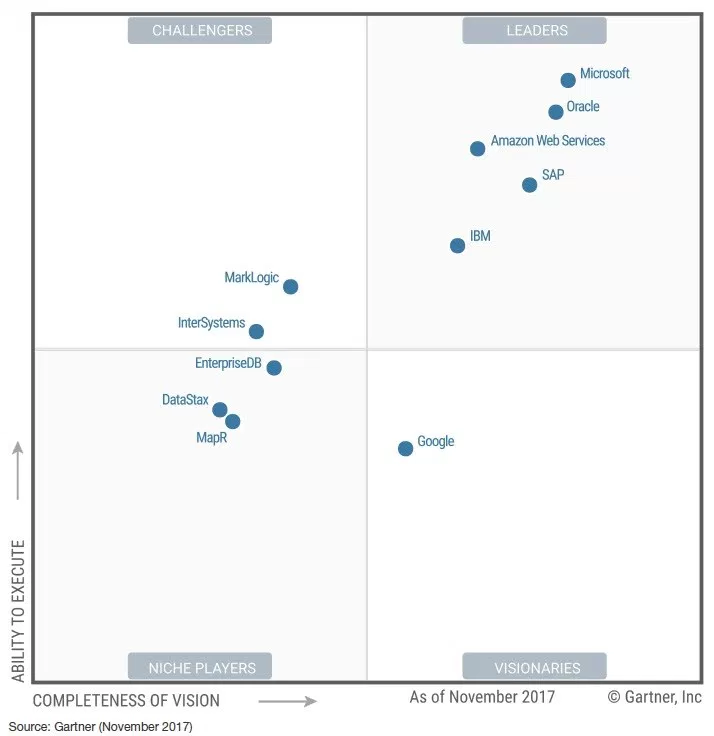
The 2015 version of the ODMS MQ has 31 entries. But by 2017, it drops to 11. The open-source entries are all gone, even though three performed very well in the 2015 version of the MQ.
This brings up an interesting question.
How can an MQ have so 2/3rds of its entrants disappear in just two years? Three entrants in the upper right quadrant in 2015 are not anywhere in the MQ in 2017.
Conclusion
There is a severe problem when such MQs with so many glaring inconsistencies can be published without invoking widespread ridicule. When one researches databases, one is constantly confronted with how well an entity performed in the Gartner MQ listing, but without questioning whether the Gartner MQ is anything more than an ability to pay.
Gartner has a self-explanatory method on how to score entities in its MQ.
- Gartner figures out how much each entity paid.
- Gartner then moves the dots around to make it look like it is not organizing them.
- Gartner throws in occasional misdirection entries like MariaDB or MongoDB that did not pay Gartner or perhaps paid little. Gartner could not maintain the illusion that the MQ has any legitimacy without some entries known to be good but will not or cannot pay.
- Gartner then places generalized company profiles below the MQ, which gives little insight into why the entries score as they did in the MQ. As Gartner says, “90% of the analysis is not written down.” This incentivizes customers to sign up for one-on-one briefings with the analyst. Therefore, the objective of the MQ is to make them impenetrable or not to make sense. That way, the customer/buyer has to reach out. Academic research or any research works in the opposite manner of this. When I read academic research (or any research for that matter), I am not required to reach out to the researcher to ask them, “What are you talking about?” But with Gartner, that is how they make their money. Therefore, the more impossible the MQ, in a way, the better.
Gartner’s DMSA and ODMS MQ make absolutely no sense from the database perspective and can only be understood from how Gartner receives its funding, where everything falls into line, and it makes perfect sense.
These MQs receive an accuracy rating of 1 out of 10, which is useless for decision-making concerning DBs. But it does tell us who is paying Gartner to be included in this MQ.