
Exploratory’s New Way of Working with Data
Executive Summary
- Exploratory is an innovative new product with a new way of working with data files.
- We cover how to best manage data in Exploratory.

Introduction
Exploratory.io is a data science application and front end to the R programming language. It does many things, but it allows one to keep any number of states of data. This will be the subject of our first article on Exploratory.io.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Why is This Approach Better?
This is so much more powerful than dealing with files because it means the original values stay the same, but you can keep “adding” on top of them. But you have traceability to the initial values.

Any column can be “overwritten” with new values. Notice the option to either “Create New Column” or “Overwrite Existing.” This is a bit misleading as the values are not overwritten but instead are represented as new values in a particular step in Exploratory.io. Again, the original data or any state of data in the intermediate steps are still available.
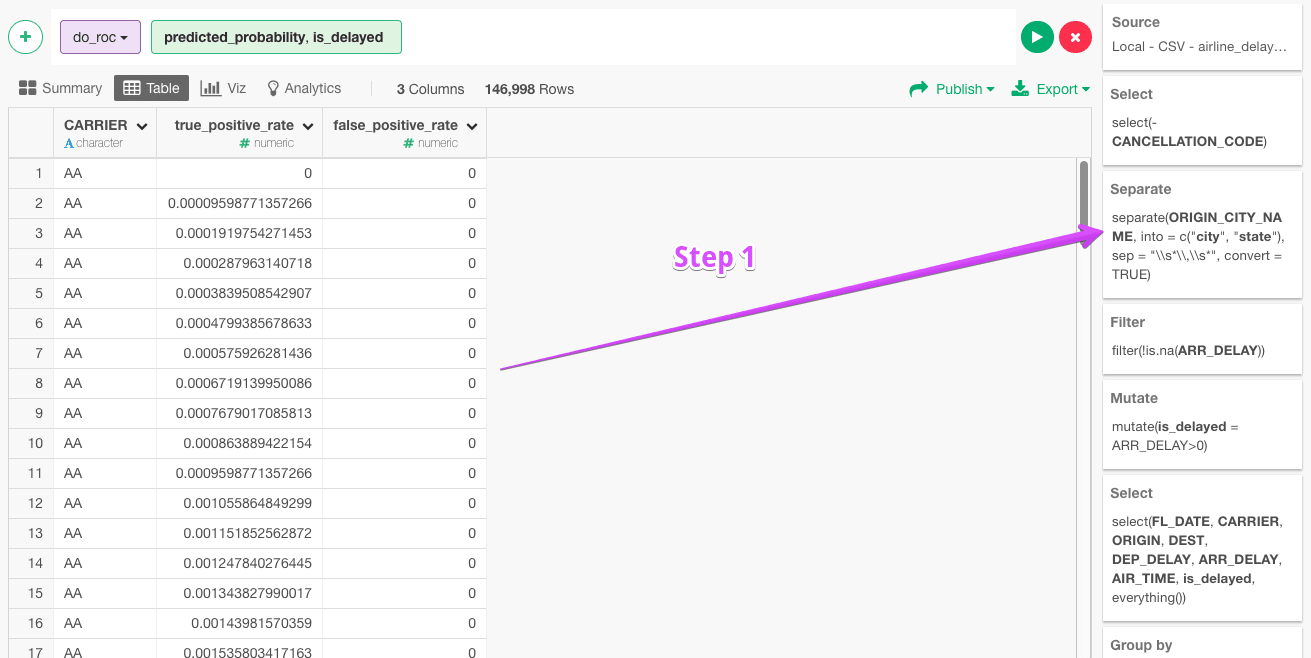
In Exploratory.io, all values show a certain way per step.
This means that Exploratory.io is more like a layer cake and a data versioning system.
Exploratory.io like a layer cake, if the layers were a point in time. So one might call it a layer cake combined with a time machine.

If you move higher in the layer cake, the data is rawer. The further down you go, the more processed it has become. Which is the right value for the data? All of them solely depend on what you are looking for. This changes the data management workflow, where the data is processed, and then the earlier stages are lost.
Data Processing as an Endpoint or as an Auditable Process?
The common concept is that the final data is the critical data, but this does not look at the overall data processing activity as a process but sees it more as an endpoint. This results in encapsulated and difficult to audit analysis. And it is partly a feature of the tools that have been available and have made a conscious decision not to focus on this type of functionality.
Exploratory.io has a far more nuanced perspective on the data processing process. Exploratory.io combines this time control capability with something called branching.
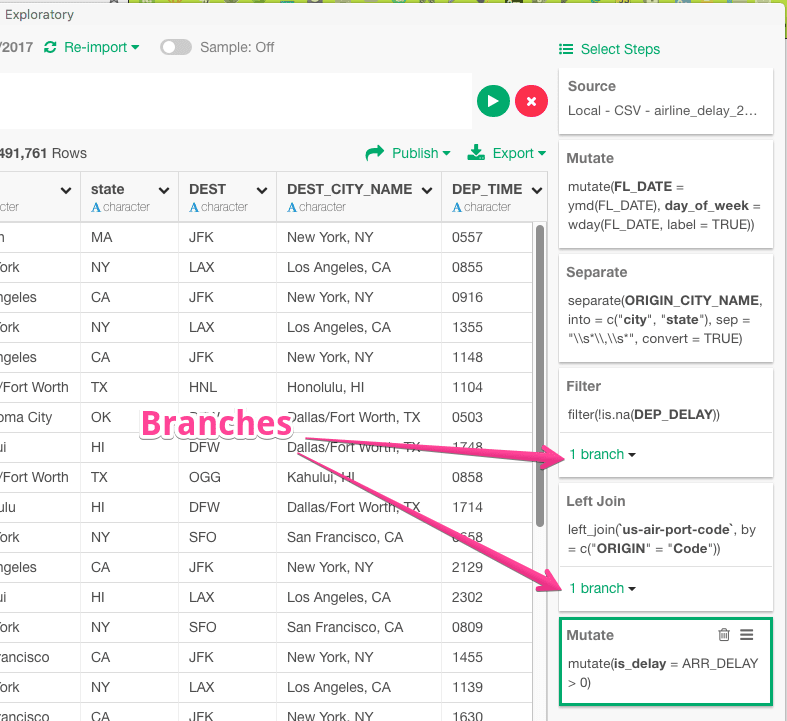
Branches are another example of Exploratory.io’s focus on keeping the entirety of the chain of alterations that occur in data science data processing. The branch allows a new timestream to be created, which will diverge from the parent timestream.
This way, two different analytical pathways can be created that do not interfere with each other but are based (or at least partly based) upon the same original data set.
This is a dramatically different way of working with data and means that versioning is managed in Exploratory. One does not have to maintain a separate version of files in a directory. Make sure they are correctly named and end up with a list you then have to interrogate.
Imagine how much easier this is you leave the work for months and then come back to it!
How to Best Manage Data in Exploratory.io?
My observation on data management efficiency when using Exploratory.io is that I want to get the data in CSV or Excel at the most basic level and then do all the manipulation in Exploratory.io.
The Logic of Moving Away from Storing Data in Excel Files
I have recently created the CSV file because I don’t need to do anything to it before putting it into Exploratory. Even basic things like text and number manipulations can be performed in Exploratory, as is explained in Kan Nishida’s article 5 Most Common Text Data Wrangling Operations in Exploratory.
So it just becomes about getting the data in the file as quickly as possible.
As a bonus, CSV files preview much faster and nicer in Mac vs. Excel. CSV has no formatting, nothing for the OS to process before showing it to you.
Even a file with many columns previews quickly in Mac, meaning that there is little need to open the file in a text editor unless one wants to alter the file. One usually wants to see what is in the file. Mac does not “love” previewing Excel files. Therefore, this creates the incentive to open the Excel file, which is time-consuming, and it means you can’t see your data files as well.
Storing Raw Data in a Cleaner and More Auditable Way
Storing data this way improves the ability to check one’s files quickly rather than encapsulating Excel data. But it is only feasible if you use a data science application like Exploratory (or if you are manipulating the files in R and can keep all of your arrays straight) that allows all the work to be done manipulating the files outside of Excel.
Conclusion
Exploratory.io gives data scientists a new way of dealing with data. It’s not “entirely new,” but it is new for practical purposes. It is certainly new to me.
It will change the way we do our analysis and how we store data for that analysis.