
How Accurate Are SAP and Oracle on Using One Giant Database?
Executive Summary
- Both SAP and Oracle have proposed that their customers place all data for applications and analytics on one of their database instances.
- How accurate are the claims of the benefits of such a design?

Introduction
In the article Exadata and data consolidation, the breakthrough towards successful transformation! Published on April 28, 2019, Oracle re-proposed the concept of a single database for all of a company’s data. In this article, we review this concept for its logic and fit with the reality of databases.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Lack of Financial Bias Notice: The vast majority of content available on the Internet about Oracle is marketing fiddle-faddle published by Oracle, Oracle partners, or media entities paid by Oracle to run their marketing on the media website. Each one of these entities tries to hide its financial bias from readers. The article below is very different.
- This is published by a research entity, not some dishonest entity that is part of the Oracle ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on Oracle is provided by Oracle, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, Oracle pays off all IT analysts -- who have the same concern for accuracy as Oracle. Not one of these entities will disclose their pro-Oracle financial bias to their readers.
Too Many Databases?
In his article Boukadidi Mounir and Oracle propose the following problem with the current database environments at companies.
“Here is a frequently observed situation. An organization is having many data sources, ranging from many Oracle databases with different releases, with other database systems such as Mongo DB, Mysql, etc. some databases reside in the cloud and some on-premise. The setup is too complex; data is redundant and the quality of data is questionable;
This is a logical jump that the author has not supported and is contradicted from real-life environments. First, let us review why some of these things exist.
- MongoDB is a document database using JSON, which allows a great deal of flexibility. Many developers prefer to write using a database like MongoDB, where the schema will change as the application is developed rather than being locked into a rigid relational database.
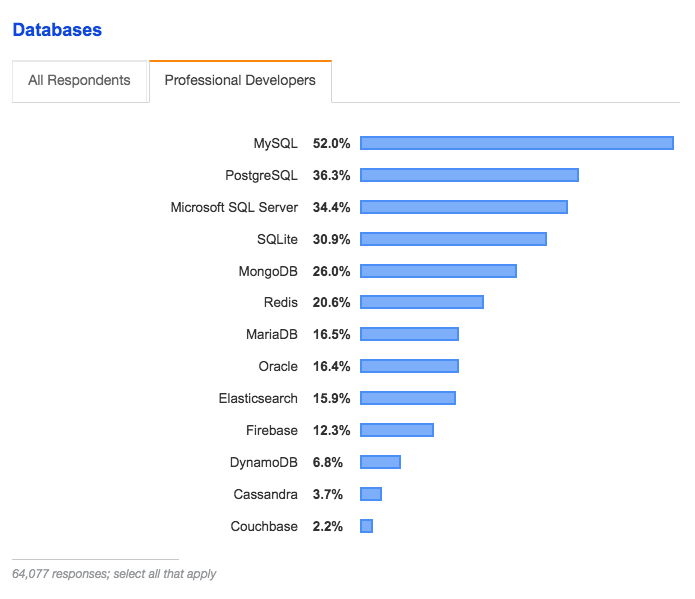
According to StackOverFlow, MongoDB is popular with developers and more popular than Oracle. Notice that other high ranked databases for developers are MySQL, PostgreSQL, SQL Server, and SQLite. These are all considered databases with high usability and low overhead. SQLite is very infrequently used for production but is often used for development. After the schema and SQL reach a maturity point, it is often ported to a more functional database.
- MySQL, while not a document database, is a straightforward database to get started with, and like MongoDB, it is open source, so this allows development without having to worry about a commercial license.
- Some databases do reside in the cloud, and others do reside on-premises, but there is also a reason Cloud providers offer near-instantaneous testing capabilities at a low cost. Under Oracle’s “One Giant Oracle Database Model,” before beginning development, every developer would have to check with licensing in their companies and get approval to use any database. Many of these databases would not become applications with many users, but Oracle would still have even the most incidental database brought up count as a full use license.
- The data is redundant, but data is redundant between applications and data warehouses. Technically, every spreadsheet that a company has is a form of redundancy. Data is transformed for different purposes, so the idea of moving to no data redundancy is a pipe dream offered by salespeople.
- The overall presentation up to this point is to mischaracterize choice and legitimate options as uncontrollable chaos. This is an inaccurate depiction.
Decision Making Processes Are Based on Intuition?
the decision making process is based on intuition rather than reliable data; business continuity processes are not supported properly as there is no infrastructure to support high availability and disaster recovery, RPO/RTO (Recovery Point Objective / Recovery Time Objective) are counted in days where business requirement is in minutes. Backups and archiving are at the level of the operating system, based on regular daily snapshots; and when it comes to security, and regardless of the many lines of defense already deployed, data resides clear in the database and there is little protection from the inside. The organization is running the risk of data breach, and sensitive data could be clearly viewed once access is granted (or stolen!). With all these challenges, and in the current setup, it’s obvious that any digital transformation will be too expensive with higher risk of failure. So what to do? How to proceed? and from where to start?”
Well, that is a lot of claims rolled into one. This entire paragraph rolls up too many concepts into one and looks like a bunch of stuff just thrown into a bucket.
First, as long term research, I can say that even when data is perfectly presented, it is still common for decision-makers to not go with the data. And changes in databases will not change this human feature. There is a frequent proposal by companies that have databases or analytics to sell that if we just had a faster database or better analytics, decisions would immediately improve. However, we could quickly improve decision making by promoting more analytical people into decision making roles, but decision-makers are rarely selected for these traits. But the claim here seems to be that the data in companies is of such poor quality that only intuition is available to decision-makers.
This is not true.
There is an effort to pull data out of systems, but that does not mean that it is utter pandemonium in the analytics space. As far as backups, it is quite rare for US companies at least to lose data. Companies could do much more to safeguard data, but that would not be significantly changed by moving to a single database.
This article goes on to propose using Exadata and to put as much data as possible on the single combination of Exadata and the Oracle database.
This overall analysis is critiqued by Ahmed Azmi as follows:
Ahmed Azmi on Database Monoliths
“When we talk about integration, we differentiate between data integration and process integration. Data integration extracts data from multiple operational sources into departmental or corporate stores for reporting, analysis, and forecasting. This is the classic data mart/warehouse approach. The problem here is twofold. Loss of business agility due to IT backlog and the creation of multiple silos and sources of the truth. Moving source systems into one database/platform do NOT remove the need for ETL because the source systems remain unchanged. The data models and formats of source systems are designed for transactions, not analytics (normalized) so the data still must be extracted, transformed (aggregated, rolled up, dimensioned) on the fly each time a query is executed. For large data sets and complex queries, the performance penalty on multiple joins and table scans increases exponentially.
Moreover, doing analytics on operational systems creates a single point of failure because compute, memory, and storage resources are shared. A data corruption, memory leak, or usage spike would be catastrophic. Without workload isolation, the blast radius will be global. This is covered in the article Why Did Netflix Migrate to the AWS Cloud? In process integration, different applications or system communicate via published APIs. For example, a shopping cart app sends a message to a fulfilment centre system via secure HTTP to verify/update inventory items than another message to customer master financials and finally purchase history system. Process integration applies to distributed NETWORKS instead of monolithic, centralized systems. “
SAP’s Proposals for Single Database to Rule Them All
SAP also promised a single database for all applications back in 2011. (Vishal Sikka), and under the same logic, it would eliminate ETL. The quotation and analysis in the article How Accurate Was SAP on Becoming the #2 Database Vendor by 2015? Secondly, even if every application a customer used sat on one DB, that does not mean the application database schemas are integrated. To do such a thing would necessarily require stitching all of Oracle’s applications into a single mega-application. That has not happened and is very unlikely ever to happen.
SAP never came anywhere near to having this come true, and SAP customers today use the same one to one relationship between applications and databases combined with a data warehouse as they did back before HANA was introduced.
Conclusion
The proposal that vendors like Oracle and SAP make has a simple outcome. To increase account control by having all data stored on the database of a single vendor. Oracle has a lot of database talent, so they know that proposing the Oracle database as the best database for all processing types is not a sustainable technical position to hold. This uni-vendor strategy has decades of failure behind it, but it is suitable for vendors and consulting firms, so it will continue to be proposed.