
How Accurate Was Dr. Hubert Dreyfus on AI Predictions in His Book What Computers Can’t Do?
Executive Summary
- Dr. Hubert Dreyfus predicted many issues that AI would face when it tried to emulate human brains.
- How accurate were his predictions?

Introduction
Hubert Dreyfus’s book, What Computers Can’t Do, was initially published in 1972 and updated several times throughout the decades. Dr. Dreyfus was not an AI academic, practitioner, or mathematician. Instead, Dr. Dreyfus was a philosopher. His predictions around the limitations of AI hold up exceptionally well and far better than the far better-known Marvin Minsky’s predictions. You will learn about Dreyfus’ projection of the pathway to better machine intelligence and how the AI community turned their back on his insights in favor of the idea that a human brain is more strongly related to how a computer comes to conclusions.
Our References for This Article
If you want to see our references for this article and related Brightwork articles, see this link.
The Importance (and Rarity) of Checking the Accuracy of AI Assumptions and Predictions
In AI’s history, the accuracy of statements around what AI will accomplish is one thing that receives little attention. In many cases, some of the most prominent people in AI history will have low accuracy in their predictions on AI.
I have taken passages from this difficult-to-read book that caught my eye to observe how predictive Dreyfus was. Note that Dreyfus updated his book in the version I read, and his core assertions/predictions were unchanged from the 1972 original version. By 1972, there had been roughly 13 years of research in AI. What is impressive is that this book is, as of the publication of the article you are reading, 48 years old.
What is the Ontological Assumption?
Dreyfus speaks of the ontological assumption of AI.
The ontological assumption that everything essential to intelligent behavior must in principle be understandable in terms of a set of determinant independent elements allows AI researchers to overlook this problem. – What Computers Still Can’t Do
Let us define the term ontological as it is an obscure term for most people. Here is what Wikipedia has to say about the term.
Ontology is the philosophical study of the nature of being, becoming, existence, or reality. It is part of the major branch of philosophy known as metaphysics. Ontology deals with questions about what things exist or can be said to exist, and how such entities can be grouped according to similarities and differences.
The Epistemological Assumption
The second assumption that Dreyfus discusses is the epistemological assumption, which is the study of knowledge assumption. For computer people, this could be considered the “data” or domain knowledge. The ontological assumption that is generally proposed by AI academics and practitioners, but what Dreyfus is proposing, is usually unquestioned, as he explains next.
We shall soon see that this assumption lies at the basis of all thinking in AI. And that it can seem so self evident, that it is never made explicit or questioned.
As in the case of the epistemological assumption, we shall see that this conviction concerning the indubitability of what in fact is only a hypothesis reflects 2000 years of philosophical tradition reinforced by a misinterpretation of the success of the physical sciences. Once this hypothesis is made explicit and called into question it turns out that no arguments have been brought forward in its defense and that, when used as the basis for a theory of practice, such as AI the ontological assumption leaves profound conceptual difficulties. – What Computers Still Can’t Do
All of this roughly translates to unexamined assumptions. Evidence for this lack of examination is that in repeated comments about Marvin Minsky, he is lauded for proposing that the brain works like a computer. However, in nearly all cases of the many articles we read about Marvin Minsky, we did not find a piece that asked if the assumption was correct. The articles instead noted Marvin Minsky’s prominence in the field and then stated the assumption of computer = brain and left it at that.
It should be noted that many of the articles we read were written after Minsky’s death on Jan 24, many decades after Minsky’s hypothesis on the machine-brain equivalence had been disproven.
The Reassertions of Unproven Hypothesis
This problem is widespread inside and outside of AI.
It is routine that hypotheses are stated and then repeated without the hypothesis having ever been proven. This is a common tactic employed in defense of a hypothesis not working in practice to restate the hypothesis or the hypothesis’s virtuous nature. Many confuse repeating an unproven hypothesis with making a statement about something known to be true. We have found this issue across several areas that have consumed enormous IT investments. In the book The Real Story Behind ERP, we reviewed all the academic literature on ERP and found no research studies could find an ROI from ERP systems. We covered the claims of Big Data in the article The Pipe Dream and Misunderstanding of Big Data. We found that most of the claims are highly exaggerated and based upon erroneously extrapolating from the experience of enormous data monopolies to the benefits to companies not in this position. Time and again, once a series of financial incentives built up around a hypothesis, there becomes little interest in validating the hypothesis, and instead, the hypothesis is restated. The genius of the IT opinion shapers (vendors and consulting firms) is that they sheepdog investments into unproven hypotheses before the hypothesis has had time to be tested. When a large enough data sample is available to falsify a hypothesis, the hypothesis already has a mini self-reinforcing industry built up around it. Vendors and consulting firms pay IT analyst firms and IT media, which perpetually have their hand out for income, to restate their unproven hypotheses to customers to build a succession of evidence-free hypotheses, creating waves of investment based upon marketing assertions.
In many discussions I have had, the response to questioning the validity of a hypothesis has been for the respondent to repeat the hypothesis. This is particularly true of hypotheses that are appealing to believe. The person on the other side of the debate, asking for evidence, is then essentially asked to be drawn into whether the hypothesis is a good idea or “makes sense” rather than whether there is any evidence that it is true. People asking for evidence are often effectively sidelined by being characterized as being “negative” or lacking “vision.” Which are, of course, ad homeniums rather than presentations of evidence.
The Effect of Invalid Hypothesis Repetition
Through this method, the disproven hypothesis can continue for decades or hundreds of years without being held to account for being incorrect.
Dreyfus continues to describe the outcome of over 50 years of investment into the development of generalized intelligence (from a later edition of the book, which includes retrospectives).
In surveying the four assumptions underlying the optimistic interpretation of results in AI, we have observed a recurrent pattern. In each case, the assumption was taken to be self evident and actually am seldom articulated and never called into question.(emphasis added) In fact, the assumption turned out to be only one alternative hypothesis and a questionable one at that. The biological assumption that the brain must function like a digital computer no longer fits with the evidence.(emphasis added) The psychological assumption that the mind must obey a heuristic program cannot be defended on empirical grounds and on a priori arguments and its defense fails to introduce a coherent level of discourse between the physical and the phenomenological. – What Computers Still Can’t Do
Here, Dreyfus uses another word unused outside of the academic or cognitive sciences, which is phenomenological.
Phenomenological means the study of the structures of consciousness.
Dreyfus continues.
There is no reason to deny the growing body of evidence that human and mechanical information processing proceed in entirely different ways. The psychological epistemological and ontological assumptions have this in common, they assume that man must be a device which calculates according to rules on data which take the form of atomic facts. Such a view is a tidal wave produced by the confluence of two powerful streams. First, the platonic reduction of all reasoning to explicit rules in the world to atomic facts, to which alone such rules could be applied without the risk of interpretation. Second, the invention of the digital computer, a general purpose information processing device which calculates according to explicit rules, and takes in data in terms of atomic elements logically independent of one another.
After 50 years of effort however, it is now clear to all but a few diehards that this attempt to produce general intelligence has failed.(emphasis added) This failure does not mean that this sort of AI isn’t possible, no one has been able to come up with such a negative proof.
Rather, it is turned out that for the time being at least the research program based on the assumption that human beings produce intelligence using facts and rules, has reached a dead end and there is no reason to think it could ever succeed. – What Computers Still Can’t Do
This was written in 1972, but it may as well have been written in 2020.
It considers the enormous increases in processing power and techniques since 1972, which Dreyfus would have no way of knowing would occur. This brings up questions about how universal this observation is independent of processing power.
Good Old Fashioned Artificial Intelligence and the History of AI (to 1972)
Dreyfus comments below on the development of AI from the 1950s onward to 1972.
We can see this very pattern in the history of GOPHI (Good Old Fashioned Artificial Intelligence). The program began auspiciously with Alan Newell and Herbert Simon’s work at Rand in the late 1950s. Newell and Simon proved that computers could do more than calculate. They demonstrated that a computer strings of bits could be made to stand for anything, including features of the real world and that its programs could be used as rules for relating these features. The structure of an expression in a computer then could represent a state of affairs in the world whose features had the same structure in the computer could serve as a physical symbol systems storing and manipulating such representations. In this way, Newell and Simon claimed, computers could be used to simulate important aspects of intelligence. That’s the information processing model of the mind was born. Newell and Simon’s early work was impressive and by the late 1960s, thanks to a series of micro world successes such as Terry Winograd’s SHRDLU, A program that could respond to English like commands by moving simulated idealized blocks. AI had become a flourishing research program. The field had its PhD programs, professional societies, international meetings and even its gurus. It looked like all one had to do was extend, combine and render more realistic. The micro worlds and one could soon have genuine artificial intelligence. Marvin Minsky, head of the MIT AI project announced within a generation the problem of creating artificial intelligence will be substantially solved.(emphasis added) Then suddenly, the field ran into unexpected difficulties. The trouble started with the failure of attempts to program an understanding of children’s stories. The program’s lack of common sense of a four year old and no one knew how to give them the background knowledge necessary for understanding even the simplest stories. – What Computers Still Can’t Do
This is where Dreyfus includes a critically insightful juxtaposition of the “early” 1950s Minsky with the “later” Minsky of the early 1980s.
It was not as Minsky had hoped, just a question of cataloguing 10 million facts. Minsky’s mood changed completely in the course of 15 years in 1982. He told the reporter the AI problem is “one of the hardest Sciences has ever undertaken.” – What Computers Still Can’t Do
Notice that Minsky’s comment may be valid (it is difficult, but there are a lot of complex problems in science, such as how ribosomes work dark matter, and coordinated ant behavior; the list is quite long). Still, it is also used to explain to the listener and himself, that his initial predictions had been proven false.
Minsky was a primary influencer on government funding in solving this problem. Minsky said on many occasions that the problem would be solved and solved very quickly. Why does the AI community refuse to hold Minsky accountable for his inaccuracy? Minsky is a “pioneer of AI?” However, pioneers are supposed to break through to new areas. However, they are not supposed to get lost along the way.

HAL was a highly sophisticated generalized intelligence that went beyond any programmed consciousness into at least semi-consciousness. It responded to a threat to be disconnected by the protagonist in the movie (Dave).
A generalized intelligence, like HAL, was estimated by Minsky for 2001 (and reading his quotation from the 1950s and 1960s, significantly before 2001). Minsky told Stanley Kubrick while working as a consultant on the film that HAL was a conservative estimate of what AI could do.
The reality?
By 2002, we had Roomba.
How does the plot of 2001: A Space Odyssey change if we use reality? Reality is where iRobot’s Roomba AI vacuum cleaner replaces HAL.

First, the movie would have to be renamed to 2002: A Space Odyssey (the Roomba was introduced in 2002), and the plot would require some adjustments.
- First, Dave would not have been able to talk to “Roomba HAL.”
- Second, Dave would have opened the bay doors without issue.
- Third, “Roomba HAL” would have been pushed to a background or “supporting actor” role.
- “Roomba HAL” spends the movie cleaning up the spaceship in the background.
- A sequel to this first movie, let us call it 2020: A Space Odyssey, would showcase an updated “Roomba HAL” that navigated around the room even better and more efficiently, but that would be the extent of the advancement between 2020 and 2001.
It is not hard to see that these movies would have had a hard time getting produced by Hollywood.
If Minsky had understood or been adequately incentivized to incorporate more reality into his predictions, he would not have been in the position of having to make excuses for why his predictions were so inaccurate.
What is GOFAI?
Dreyfus begins this quote by bringing up the topic of GOFAI.
GOFAI was the earliest approach to AI. And GOFAI is nicely explained from the following comment on Reddit.
Various AI researchers have critiqued the early GOFAI research, e.g [1].
Roughly, the main arguments in these critiques were:
- The representations used in the early GOFAI work weren’t meaningful representations of the real-world.
- The emphasis on formal logics and deductive reasoning ignored other methods of reasoning.
In more detail:
1: Many early AI research projects involved constructing a representation of a domain using first-order logic predicates, or something similiar. For example you would have a description of a restaurant domain as follows:
at(restaurant,Alice)
at(restaurant,Bob)
at(restaurant,Carol)
works_at(restaurant,Carol)
has_job(restaurant,waitress,Carol)
orders(Bob,pizza)
orders(Alice,sushi)
along with rules for reasoning about the domain, such as:
forall X,Y,Z. orders(X,Y) and has_job(restaurant,waitress,Z) -> serves(Z,X,Y)
which attempts to encode the rule that if person X orders food Y and Z is a waitress at the restaurant then Z will serve food Y to person X.
From the above representation we can deduce:
serves(Carol,Bob,pizza) serves(Carol,Alice,sushi)
The main problem with this approach is that it isn’t clear where the meaning of those predicates comes from. As far as the computer is concerned our above representation could be encoded as follows:
a(r,A)
a(r,B)
wa(r,C)
hj(r,w,C)
o(B,p)
o(A,s)
forall X,Y,Z. o(X,Y) and hj(r,w,Z) -> s(Z,X,Y)
The natural language labels for the predicates have no meaning to the computer, as far as it’s concerned the above two representations are equivalent.
This argument relates to what is called the symbol grounding problem for symbolic AI [2].(emphasis added) Namely the problem of assigning meaning to the symbols used in a representation. This is quite a difficult philosophical problem, it touches upon issues of intentionality [3] and meaning in natural language. The basic gist of the problem is: how does the symbol ‘Alice’ in the above representation connect with the actual living person Alice in the real-world?
The practical approach to resolving the symbol grounding problem is to work on connecting the AI agent with the real-world, through some kind of input, and having the symbols in the representation derive their meaning from representations of the input.
The other difficulty with symbolic representations is their reliance on common sense knowledge to be useful. The simplistic restaurant representation above doesn’t represent much of the complexity of a real-world restaurant, e.g. Carol wouldn’t serve Alice and Bob if her shift ended.
By far the largest attempt to encode commonsense knowledge is Doug Lenat’s CYC project [4]. It had been running for decades trying to encode everything that the average human could be expected to know about the world.(emphasis added) I think it is generally accepted that it hasn’t succeeded yet, and as far as I’m aware it isn’t the focus on much recent AI research.
As a brief comment, AI research in this third AI bubble has been mostly around neural networks/deep learning, with a revival of other forms of old machine learning techniques placed into “new bottles,” which constitute most of the parts of AI that are concentrated on forecasting, combined with data mining for the development of causal forecasting methods.
These are all investments in narrow, weak AI solutions and the opposite of Marvin Minsky’s proposal of generalized intelligence or strong AI.
The quote continues and draws this distinction to strong AI, or what might be called the AI that results in HAL’s creation.
2: The second argument is largely aimed at the logicist approach to AI, which focuses upon the use of formal logics to create AI software. The main proponent of this approach was John McCarthy [5].
The logicist approach was criticised for ignoring or down-playing other methods of reasoning, such as: Abduction, Induction, Analogy, Argumentation, Statistical methods, Probabilistic reasoning.
The Logicist AI approach also raises the problem of descriptive or prescriptive AI. Are we trying to construct AI agents that reason similarly to people, including the possibility of making mistakes when reasoning? Or are we trying to contruct AI agents that reason correctly?
Logicist AI stems from work in Mathematical Logic and Philosophy which focused upon the problem of how to reason correctly, irrespective or whether that reasoning was computationally feasible. Much of the work done in Logicist AI can be seen as an attempt to create AI agents that can be mathematically proved to reason correctly about the world when given a representation. The problem with this approach is that there is a lot of reasoning involved in creating a representation, reasoning which isn’t necessarily based upon a formal logic.
The proponents of logicist AI have their own counter-arguments which I suggest you look up if you are interested. This is an extremely brief discussion of the field.
In summary, the main problem with the GOFAI approach isn’t really the researchers or the methods that they used, but rather the scope of the problem. Researchers using the GOFAI approach were tackling the “Strong AI” problem [6], the problem of constructing autonomous intelligent software that is at least as intelligent as a person. Many of the more recent approaches are in the field of “Weak AI”, creating techniques for solving specific problems that traditionally require a person to solve them.(emphasis added)
An example “Weak AI” problem would be creating Computer Vision software to detect when a fight is about to break out in a crowd. This task typically requires a person to monitor the scene via a CCTV camera and spot the features that indicate a fight is about to break out. An AI solution might involve training a classifier to identify those features and analysing the live CCTV stream to check for them.
Weak AI problems tend to be more approachable using number crunching methods as we know how to effectively employ software in that role.(emphasis added) The “Strong AI” problem requires software which has a deeper understanding of how people represent and reason about the world.
[1] McDermott, D. (1987), A critique of pure reason. Computational Intelligence, 3: 151–160. doi: 10.1111/j.1467-8640.1987.tb00183.x [2] Harnad, Stevan (1990) The Symbol Grounding Problem. [Journal (Paginated)] (see http://cogprints.org/3106/) [3] http://plato.stanford.edu/entries/intentionality [4] http://www.cyc.com/ [5] http://www-formal.stanford.edu/jmc/ [6] http://en.wikipedia.org/wiki/Strong_AI
As we have discussed, most AI projects today deal with number-crunching and weak AI rather than understanding how the brain works.
This is a good time to pick back up with Dreyfus.
My work from 1965 on can be seen in retrospect as a repeatedly revised attempt to justify my intuition based on my study of Martin Heidegger, Maurice Merleau-Ponty, and later Wittgenstein that the GOFAI research program would eventually fail. My first take on the inherent difficulties of the symbolic information processing model of the mind was that our sense of relevance was holistic and required involvement in ongoing activity, whereas symbol representations were atomistic and totally detached from such activity. By the time of the second edition of what computers can’t do in 1979, the problem of representing what I had vaguely been referring to as a holistic content was beginning to be perceived by AI researchers as a serious obstacle.
Comments from Dreyfus Deep in the First AI Winter
What Dreyfus describes here is in the nadir of the first AI winter. The first AI winter is timed with the Lighthill report’s publication, which pointed out the lack of AI progress up to that point.
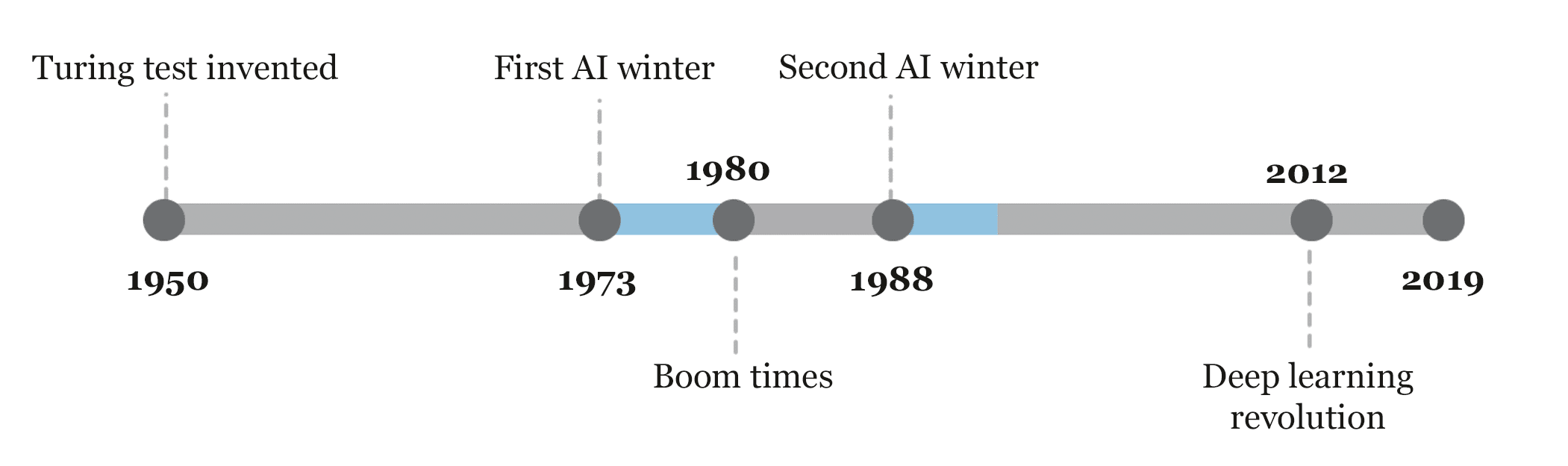
Graphic from Sebastian Schuchmann.
To pull out of the first AI winter, the field had to pull away from generalized intelligence investment and narrow and reduce the expectations of developing “expert systems.” And the overstatement of what expert systems could do then led to the second AI winter. What happened to expert systems is itself and in an interesting story, which we will cover in another article.
Dreyfus continues with the debate around symbolic representation being the approach to mastering the goals of AI. According to Dreyfus, many AI researchers proposed that intelligence is nothing more than symbolic representation and manipulation. The following quotation is, in my view, the best explanation of the oversimplification of cognitive skill development by many (most?) AI researchers that I have come across through researching the history of AI.
What I needed was an argument against those who assume that such skills were representable in symbolic form. As it turns out, my brother Stuart provided the missing argument in the phenomenological account of skill acquisition. Skill acquisition, he pointed out usually begins with a student learning and applying rules for manipulating context free elements. This is the grain of truth in the information processing model. Thus, a beginner at chess learns to follow strict rules relating such features as center control and material balance. After one begins to understand the domain, however, one sees meaningful aspects, not context free features. Thus, the more experienced chess player sees context dependent characteristics, such as unbalanced pawn structure or weakness on the kingside. At the next stage, a competent performer learns to set goals and then look at the current situation in terms of what is relevant to achieving those goals. A further stage of proficiency is achieved when after a great deal of experience, a player is able to see a situation is having a certain significance tending towards a certain outcome and certain aspects of the situation standout is salient in relation to the end, given an approximate board position for example, almost all masters would observe after a few seconds sense of examination that when white must attack the kingside
Finally, after even more experienced one reaches the level where one sees immediately what must be done. A chess grandmaster, for example not only sees the issues in a position almost immediately, but the right response just pops into his or her head. There is no reason to suppose that the beginners features and rules or any of those features and rules play any role in such expert performance that we once followed a rule in learning to tie our shoelaces does not show as Edward Feigenbaum argues it does that we must still be following the same rule subconsciously whenever we tie a lace that would be like claiming that since we needed training wheels and learning when learning how to ride a bicycle, we must now be using invisible training wheels whenever we ride. There is no reason to think that the rules that play a role in the acquisition of a skill play a role in its later application.(emphasis added) When mind over medicine, when mind over machine came out, however, Stuart and I faced the same objection that had been raised against my appeal to holism. In What Computers Can’t Do, you may have described how expertise feels critics say, but our only way of explaining the production of intelligent behavior is by using symbolic representation.(emphasis added) So that must be the underlying causal mechanism. Newell and Simon resorted to this type of defense of symbolic AI quote, “The principal body of evidence for the symbol system hypothesis is negative evidence. The absence of specific competing hypotheses as to how intelligent activity might be accomplished either by man or by machine.”
The proposal that we should set about creating our Artificial Intelligence by modeling the brains learning power, rather than the mind symbolic representation of the world that drew its inspiration, not from philosophy but from what was soon to be called neuroscience.
It was directly inspired by the work of D. O. Hebb.. – What Computers Still Can’t Do
This is back to the core issue humans think is not found by looking at mathematical algorithms, particularly for robust AI applications. Dreyfus predicted that mathematicians’ overly mechanistic assumptions rather than neuroscience to mimic a human brain (strong AI) were doomed to failure.
However, the mathematicians drove AI research and who were listened to and who, in my interpretation (based upon the research results into strong AI), drove AI research into a black hole.
Conclusion
Over more than 70 years, AI research has repeatedly made claims around generalized intelligence. These claims have quickly and repeatedly been picked up and further exaggerated by media outlets. The following is a perfect example of the extreme predilection of media to perform this exaggeration.

Rosenblatt’s perceptron, a highly simplified precursor to today’s neural networks, had minimal capabilities. However, 62 years ago, The New York Times presented this “baby neural network” as a soon-to-be conscious generalized intelligence.
Notice the title and the perceptron is an “artificial brain.” Already?
Isn’t calling this an electronic brain jumping the gun a bit New York Times?
In each case, which includes the 2nd AI bubble (the expert system lead bubble) and the 3rd (and present and neural network lead) AI bubble, AI research had to pull away from generalized intelligence to focus on narrow problems. Dreyfus predicted the problems with generalized intelligence at least by 1972, and certainly before this he had been wrestling with these topics before he published his book. However, cognitive scientists and philosophers had little impact on the trajectory of AI research. Two groups have dominated AI research: mathematicians and computer/software specialists. These two groups are not experts on the mind or how the brain works.
- Neuroscience primarily focuses on medical solutions to brain maladies, not on mimicking the brain (observe where their funding comes from; neuroscience research is monetized through applications to medicine).
- Philosophers are concerned with exploring the mind, also not mimicking the brain.
This has meant that philosophers and neuroscientists have spent little time being concerned with or addressing AI researchers’ claims about how the brain works or that the brain works along with the principles of a digital computer and can be mimicked by a digital computer. Dreyfus’ book and related research are instances where we have a crossover into the AI discipline from someone outside of the field.
Let us review two misnamed or inaccurate analogies developed by AI research: the appropriation of the terms and constructs neuron, learning, and deep learning.
- Neural Networks Work Like Neurons or Like Giant Interconnected Tic Tac Toe Boards?: A perfect example is the naming of “neural networks,” which, while sharing some superficial characteristics with neurons, do not approximate neurons and instead have a close analogy with giant tic tac-toe boards. In articles on AI, the assertion is repeatedly made that neural networks are modeled on the human brain without investigating the claim.

Is it less exciting to hear of neural networks described as giant interconnected tic-tac-toe boards? Would this impact funding? Did those seeking funding co-opt biological brains’ prestige by claiming that this approach was modeled after the human brain or mimicked the human brain?
- Learning or Adjusted Weights on Node Connections?: The naming of the weight changes in the connections between the nodes of neural network topographies is termed “learning.” However, before AI co-opted it, the definition of learning was a function of biologically developed biological brains. Notice the definition of learning from Wikipedia now includes some machines.
Learning is the process of acquiring new, or modifying existing, knowledge, behaviors, skills, values, or preferences.[1] The ability to learn is possessed by humans, animals, and some machines; there is also evidence for some kind of learning in certain plants.
However, I have run many “machine learning” algorithms that are not learning. The output statistics that the user has to observe. When regression analysis is performed on a computer, Excel is not “learning.” It adjusts weights to minimize the distance between data points and a straight line. Other more advanced forms of machine learning are similarly computing an algorithm. The human learns when observing the output of the system. If the machine-learned, the human would not be necessary.
- Deep Learning, or Multilayered Tic Tac Toe Boards?: Deep thought is a term used to describe profound thinking. However, “deep” in the term “deep learning” applies only to a neural network’s many layers. Why was this term used? Deep learning means that the neural network must matriculate through more layers. When one navigates through the initial interpretation of the term “deep learning,” it is an inevitable letdown to find what the term refers to. Why was this done? Why is deep learning not called multi-layered neural networks or multi-layered tic-tac-toe boards? How much of this naming was due to promotional reasons?
The adverse outcomes of having a field dominated by groups that don’t study biological brains are the development of repeated analogies, which are incorrect, and predictions about AI, which are inaccurate. The concerns of the claims around AI being made at the time in a 48-year-old book that out-predicted the experts in the field of AI are evidence of this.