
How Real is the Data Science Gap?
Executive Summary
- Many IT media entities propose a “data science gap.”
- We analyze how accurate the proposal of a data science gap is.

Introduction
At Brightwork Research & Analysis, we usually have popped the balloon of hype around AI/ML and its projected opportunities to improve forecast accuracy. However, a new hypothesis is now becoming popular in AI/ML circles, which is the question of the data science gap.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Comments About the Data Science Gap
“It should come as no surprise that demand for folks with data science expertise exceeds supply. In fact, according to some McKinsey, there are only half as many qualified data scientists as needed. The good news is the market will likely resolve the shortage in the long run. But in the short run, the talent gap creates some challenges for an organization looking to get ahead with data.
Thanks to their ability to use math and computer science to turn big data into business gold, data scientists are the rock stars of the advanced analytics world (at least as data scientists have traditionally been defined). As more companies start investing in AI, they’ve looked to data scientists to lead the way.
A LinkedIn report from August found more than 151,000 job postings for data scientists, with acute shortages being felt in big tech hubs like San Francisco, New York City, and Los Angeles.
The big data boom has been a boon for management consulting firms like Deloitte, McKinsey, Accenture, PwC, KPMG, and Booz Allen Hamilton, all of which have devoted large sums to attracting and retaining top data science talent over the past decade.” – Datanami
This article is very similar to most of the articles we found on this topic in that data scientists demand a data scientist shortage. This is based upon data scientists’ demand, but it leaves out how much of this demand is simply due to the hype cycle. For example, as we covered in the article How Many AI Projects Will Fail Due to a Lack of Data, IBM has been exaggerating AI projects’ capabilities. Nearly all of the major vendors have. As we covered in the article, The Next Big Thing in AI is Fake AI’s Benefits. This is the next phase of AI.
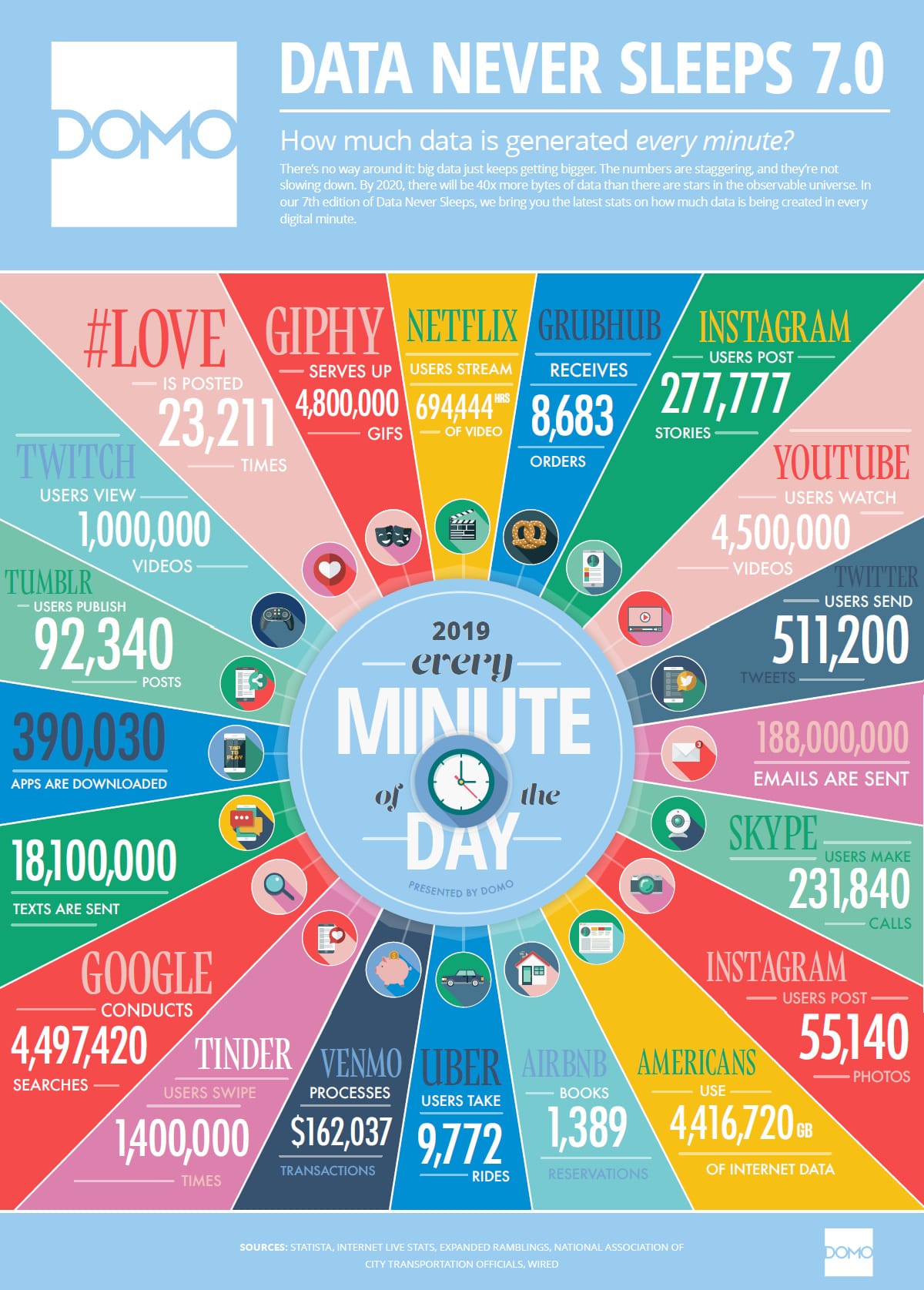
Various publications like to mention how data is growing. Data has been increasing since computers were invented.
However, an oversight by publications that publish coverage like this is the presumption of Big Data, and by extension AI/ML, this data is useful for making predictions. As we will cover, there is an excellent workload placed on data scientists that they are, in many cases, not able to meet.
The Job of a Data Scientist
The following quotation provides a realistic view of the job of a data scientist.
“When big data got going, all of a sudden everyone was trying to hire data scientists,” Snell said. “And you watch people’s LinkedIn profiles say ‘data scientist’ with 25 years of experience. That’s a title we invented last week! But suddenly we have decades of experience.” – Datanami
This quotation describes the effort that data scientists must invest.
“The best data scientists are the crazy ones, crazy passionate, willing to do whatever it takes to succeed. Someone exceeding the new 30,000 hour rule has a ridiculous amount of self-taught experience. Their toolkit is massive, and the problems they have encountered are very diverse. For the common data scientist branches (coding, hacking, stats/math) they should be very strong on all of them compared to their data science peers. A high degree of crazy/hyper-confidence is often found in the type-E individual.” – Expertfy
The “Double Consumption” of Data Scientists
Feedback from many projects indicates that the data is not anywhere near ready for algorithms when a project is begun. The data scientists turn into data mungers, as is expressed in the following quotation.
“What you think you will be doing
Implementing your fancy Machine Learning algorithms in the latest awesome framework. Maybe you will finally get to try out PyTorch. Or build your own as you have always wanted to do.
What you will actually be doing
Since you spent so much time dealing with data gathering and cleaning, the project deadline has crept closer. So you revert back to the programming language, library and tools that you have used forever.” – Towards Data Science
What we Know About Data Science (AI/ML) Projects
We are covering what very disappointing outcomes from Big Data/AI projects are.

The concept was that everyone would worry about making sense of the data later after they had already invested in a significant way into their data lakes and Big Data infrastructure and tools. This was a great way to get favored. IBM and Accenture, and everyone else that could make money on this were very much in favor of their clients, hiring them to do this.
But now the bill is coming due. And the argument is that we have a “data science gap.”
Why the gap?
There are not a sufficient number of data scientists who are sufficiently talented to get the value out of the data.
Perhaps. This is undoubtedly a conventional explanation. But it is a bit of a “Get Out of Jail Free Card” for those that proposed all of the natural benefits from data science and AI/ML.

Those that sell or publish for those that sell various hype trains eventually need to change the narrative when their overly rosy predictions don’t come true. This is where a Get Out of Jail Card or excuse comes into play. When we critique exaggerated statements by consulting firms and vendors, we are ordinarily said to be “negative.”
However, if the method followed is to make exaggerated statements and then come up with an excuse for why the prediction did not occur, then accuracy has no meaning. Regardless of the excuse given (and there will always be an excuse), this does not remove the predictor’s responsibility to be evaluated for their prediction accuracy. If a predictor is correct, they don’t say, “well, it was because of XYZ.” If the predictor is accurate, they say, “I was correct.” The excuse only comes into play when the predictor is wrong.
Is Big Data Dead…..Already?
This curious quotation..
“But despite the progress in AI, big data remains a major challenge for many enterprises.
There are lots of reasons why people may feel that big data is a thing of the past. The biggest piece of evidence that big data’s time has passed may be the downfall of Hadoop, which Cloudera once called the “operating system for big data.”
After acquiring Hortonworks, Cloudera and MapR Technologies became the two primary backers of Hadoop distributions. The companies had actually been working to distance themselves from Hadoop’s baggage for some time, but they apparently didn’t move fast enough for customers and investors, who have hurt two companies by holding out on (Hadoop) upgrades and investments.” – Datanami
And the following also from Datanami..
“Hadoop has seen better days. The recent struggles of Cloudera and MapR – the two remaining independent distributors of Hadoop software — are proof of that. After years of failing to meet expectations, some customers are calling it quits on Hadoop and moving on.
However, cracks began to appear around 2015, when customers started complaining about software that wasn’t integrated and projects that never entered production. Distributions were shipping with more than 30 different sub-projects, and keeping all of this software integrated and in synch became a major challenge.
“Hadoop is absolutely going away with cloud capabilities,” says Oliver Ratsezberger, CEO of Teradata, which was stung by the early Hadoop hype. “You don’t need HDFS. It was an inferior file system from the get-go. There’s now things like S3, which is absolutely superior to that.”
Ratzesberger was an early adopter of Hadoop, having used the technology while building software at eBay in the 2007-2008 timeframe. “We knew what it was good for and we knew what it was absolutely never built for,” he continues. “We now have customers – big customers just recently – in Europe who told me recently, the $250 million in Hadoop investments, they’re writing off, completely writing off, tearing it out of their data centers, because they’re going all cloud.””
And the following.
“I can’t find a happy Hadoop customer. It’s sort of as simple as that,” says Bob Muglia, CEO of Snowflake Computing, which develops and runs a cloud-based relational data warehouse offering. “It’s very clear to me, technologically, that it’s not the technology base the world will be built on going forward.”
“The number of customers who have actually successfully tamed Hadoop is probably less than 20 and it might be less than 10,” Muglia says. “That’s just nuts given how long that product, that technology has been in the market and how much general industry energy has gone into it.
The Hadoop community has so far failed to account for the poor performance and high complexity of Hadoop, Johnson says. “The Hadoop ecosystem is still basically in the hands of a small number of experts,” he says. “If you have that power and you’ve learned know how to use these tools and you’re programmer, then this thing is super powerful. But there aren’t a lot of those people. I’ve read all these things how we need another million data scientists in the world, which I think means our tools aren’t very good.”
Unless you have a large amount of unstructured data like photos, videos, or sound files that you want to analyze, a relational data warehouse will always outperform a Hadoop-based warehouse. And for storing unstructured data, Muglia sees Hadoop being replaced by S3 or other binary large object (BLOB) stores.” – Datanami
Ok, so wait -Big Data’s availability Big Data sources can be used to perform AI against. However, Big Data’s availability was one of the primary test cases for why AI would be effective. Because it was proposed, only AI would be able to tease out the insights from Big Data. It is extremely inconsistent to say, on the one hand, that the Big Data bubble is receding, taking with it many of its promised benefits, and then at the same time propose that AI has a great future.
Yes, I am aware that most of the quotes above relate to Hadoop. However, we are not asked to accept the assumption that the situation will significantly improve when the data is pulled from the now downtrodden Hadoop instances and placed into S3 or other “containers.” As explained throughout this article, the original proposals about Big Data are very likely to be true.
Statements About the Opportunity of AI Go Unchallenged in IT Media
Companies that have AI services and software to sell have been releasing pro-AI information to the marketplace. The IT media entities have done very little to fact check any of their statements — even though the statements come entirely from a position of commercial bias. The following quotation is a perfect example of this.
“If your competitors are applying AI, and they’re finding insight that allow them to accelerate, they’re going to peel away really, really quickly,” Deborah Leff, CTO for data science and AI at IBM, said on stage at Transform 2019.”
This is called “Fear of Missing Out.” But Deborah Leff does not bother bringing any evidence to support this claim that companies that apply AI allow them to accelerate. That question deals with the topic of benefit.
A second topic is the probability of having success with AI. And a little further on, we will see a statistic regarding AI projects placed into production rates that question how big the word “If” in this statement is.
“Chris Chapo, SVP of data and analytics at Gap, dug deep into the reason so many companies are still either kicking their heels or simply failing to get AI strategies off the ground, despite the fact that the inherent advantage large companies had over small companies is gone now, and the paradigm has changed completely. With AI, the fast companies are outperforming the slow companies, regardless of their size. And tiny, no-name companies are actually stealing market share from the giants.”
Really?
Because the statistics on the US economy at least show the opposite of this. There has been a great consolidation of many industries over the past 20 years, mostly due to mergers and acquisitions. New small business formation is currently at a multi-decade low. Chapo goes on.
“But if this is a universal understanding, that AI empirically provides a competitive edge, why do only 13% of data science projects, or just one out of every 10, actually make it into production?
“One of the biggest [reasons] is sometimes people think, all I need to do is throw money at a problem or put a technology in, and success comes out the other end, and that just doesn’t happen,” Chapo said. “And we’re not doing it because we don’t have the right leadership support, to make sure we create the conditions for success.”
13% = 1 out of 10?
It is hard to see how 13% = 1 out of 10, as it is 1 out of 7.7, but that is the least of this comment’s inaccuracies. Hoover should brand the overall comment because it is an entirely vacuous statement. But notice that the assumption is that there is always a benefit from data science projects. Another observation is that unless these AI projects are incredibly inexpensive, or unless the insights coming from the 1 out of 7.7 is a profit generator, it most likely that AI projects have a strongly negative ROI. Also, going into production is not having an ROI. SAP modules are in production all over the world and are barely used. So the ROI projects are a subset of the 13%!
If someone tells me there is a 13% chance of only doing something, and the possibility of success is some subset of the probability of doing that thing, I would question what that thing is being done. Furthermore, we are discussing doing advanced AI projects. Simultaneously, it seems that many of the people discussing and making decisions on these topics do not seem to have mastered basic probability.
Chapo goes on to explain the data issues with data science projects.
“The other key player in the whodunit is data, Leff adds, which is a double edged sword — it’s what makes all of these analytics and capabilities possible, but most organizations are highly siloed, with owners who are simply not collaborating and leaders who are not facilitating communication.
“I’ve had data scientists look me in the face and say we could do that project, but we can’t get access to the data,” Leff says. “And I say, your management allows that to go on?””
Who Are the 13%?
Because IBM and others have projects to sell, there is a great hesitation to describe “who” is getting AI projects into production. This is explained in the following quote.
“Unless your name is Facebook, Amazon, Netflix, or Google – the notorious FANG gang (plus Microsoft) – you’re chances of pulling off a successful AI or big data analytics project are slim, according to Ghodsi. “AI has a 1% problem,” he says. “There are only about five companies who are truly conducting AI today.”
“Those [FANG] companies have hordes of data scientists, like 10,000 or 20,000 of them. They have PhDs and experts from universities they hired that used to be professors,” he says. “But [the rest of the Fortune 2000] say ‘We don’t have access to Silicon Valley engineers. We just don’t have those. There’s not enough of them. The people who make huge Silicon Valley engineer salaries over here – that’s not the rest of the world.’ So how can other companies who don’t have the resources to just pour money into hiring 10,000 data scientists – how are they going to do it?”” – Datanami
The major consulting firms point to FANG outcomes, but the consulting companies can’t do this themselves. For example, IBM failed to turn their major AI project, Watson, into a successful product and ran into problems ranging from multiple data source reconciliation to entirely overestimating AI’s ability to solve the problem without providing subject matter expertise. We covered this in the article How IBM is Distracting from the Watson Failure to Sell More AI. That is, no matter how badly IBM failed at their own AI project, they would still like to sell their inability to pull of AI projects to other companies.
Fire and Forget on Funding AI Projects?
This brings up another question. Why wasn’t the data analyzed to determine its availability before the AI project was begun? Isn’t that the company’s responsibility for funding the project — to determine if the project has the necessary preconditions for success? Chapo goes on.
“But the problem with data is always that it lives in different formats, structured and unstructured, video files, text, and images, kept in different places with different security and privacy requirements, meaning that projects slow to a crawl right at the start, because the data needs to be collected and cleaned.”
Strangely, this would be news to anyone. Did anyone think that corralling the data would not entail these issues? Chapo goes on.
“Oftentimes people imagine a world where we’re doing this amazing, fancy, unicorn, sprinkling-pixie-dust sort of AI projects,” he said. “The reality is, start simple. And you can actually prove your way into the complexity. That’s where we’ve actually begun to not only show value quicker, but also help our businesses who aren’t really versed in data to feel comfortable with it.”
This seems to leave out who made these proposals. Where did these pretenses come from? Where they perchance promoted by the sales and marketing arms of vendors or consulting companies?
We publish data science’s reality, but we would be fired immediately if we worked for IBM or Accenture because being realistic about AI and data science is considered extremely bad for sales. People that discuss reality are not team players. At these companies, whoever can tell the biggest lie tends to set the agenda.
The Assumed Incredible Relationships in Big Data
What is left out is that the relationships and insights contained in the data, that is, the Big Data, were most often overstated in the first place. This is reminiscent of the Abu Ghraib scandal during the Iraq invasion. The US military began torturing Abu Ghraib prisoners because they weren’t getting the “intel” they thought they should be.
One problem.
The vast majority of prisoners got to Abu Ghraib because they were reported by people that knew them to collect the reward money. They were not turned in because they were members of the resistance (which the US called insurgents), but because there were desperate times in Iraq for Iraqis at that time. They were turned in for a reward. Furthermore, there was never any trial to determine guilt or innocence; the act of being turned in was enough for any length of detention. Because of this, most of the prisoners at Abu Ghraib were everyday people. They had no intelligence to provide. And further recall, the US was looking for something that was a false pretext for the war, WMDs. This means that the US military asked people who did not know about something that did not exist.
The Rough Sequence of Information Analysis
The first question is whether the source has the information before you presume that more aggressive methods will bring out the insights that one desires. Tens of thousands of AI/ML projects have been approved without the evidence being brought forward that the ideas are either there or that they are worth the effort to extract in the first place. The only real evidence for many of these claims is of the most hypothetical nature. For instance, the idea that an ML algorithm performed well in an M4 Forecasting Competition is based on lab-type data. These are data sets that are of far higher quality than is generally found within companies. The problem is that the better the data, the more advanced methods will tease out insights.
Upon reviewing the data sets from the M4 competition, it was immediately apparent that the M4 competition does not apply to any of the clients I have ever had. For years we have heard about how the real “action” in AI is in a mathematics branch called deep learning. So what is the evidence that deep learning is effective at creating predictive models?
“While deep learning approaches have given us better results in some applications, the technology is not being used outside of two primary use cases: image recognition (i.e. computer vision) and text recognition (such as natural language processing). For most data science use cases that don’t involve manipulating images or text, traditional machine learning models are hard to beat.
“I would say right now there’s actually no proof that [neural networks] can perform better,” Xiao says. “If you have data sets that are tens of thousands or hundreds of thousands in number and you have a traditional regression problem and you’re trying to predict the probability that someone is going to click on an ad, for example, neural networks — at least the existing structures — just don’t perform as well as other methods.”
That probably comes as a surprise to many in the industry who figured deep learning was going to drive data science into the AI future. “I don’t think that’s the answer that most people want to hear,” Xiao says “People like to throw around the term AI, but we’re not quite to that level yet.”” – Datanami
*From Research Gate
Neural networks or “Deep Learning” are a type of sophisticated decision tree. It isn’t easy to see how Deep Learning techniques will outperform simpler time series forecasting techniques for the vast majority of items that must be predicted. Many AI projects are being justified based on Deep Learning, without the funders of these projects realizing the limited applicability of Deep Learning.
If you torture people pretty soon, you start getting intelligence. Fake intelligence that is. The same thing is true of data. If you analyze data from enough dimensions, and with enough financially biased consulting firms and vendors riding the bandwagon, soon relationships will begin to “appear.” With the hundreds of variables that many data science projects are using, overfitting and illusory correlations will be reported as real. Remember, the previous investments into Big Data and the AI/ML project must be justified. The relationships and benefits must be there — I mean, all that money was spent on the data lakes!
There is a gap, alright, and it’s the differences between the promise of Big Data and reality.
Conclusion
Major consulting companies and vendors that have bet big on Big Data and AI/ML are not going to back down from the claims because the projects are by, in large, not meeting the sales presentations around them.