
How Real is the SAP Machine Learning and Data Science Story?
Executive Summary
- SAP co-opted the term machine learning without having done much work in the area because it was “hot.”
- Many of SAP’s promises around predictive analytics have been transferred to machine learning.

Video Introduction: How Real the SAP Machine Learning and Data Science Story is
Text Introduction (Skip if You Watched the Video)
The term machine learning has been growing as a term to use and is now migrating into software vendors who intend to use it to sell software.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
We will begin this article by reviewing this graphic.
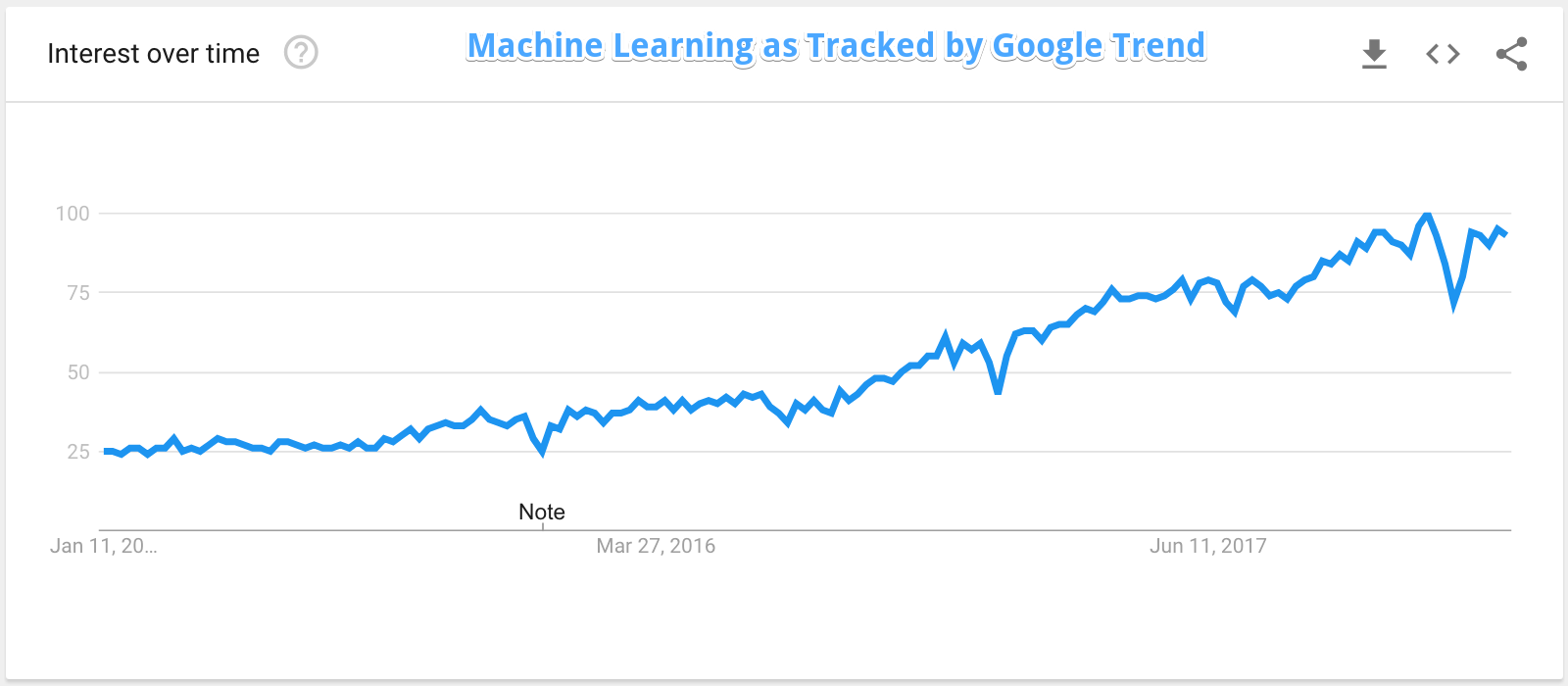
As we can see from Google Trend, the interest in the term Machine Learning is growing. It is now four times more popular as a searched term than it was just a few years ago.

SAP has a lengthy history of co-opting things. It has nothing to do with it. Marketplaces, collaboration, inventory optimization, good UI design, databases, IoT, HTML5, and the list go on. SAP can immediately partner with a company and claim capabilities merely through an association of a partnership.
How SAP Has Co-opted the Term Machine Learning
SAP has co-opted the term machine learning with fantastic speed. And as they have done so, they have applied their standard marketing flourish, which means that the way SAP represents machine learning has little to do with how machine learning actually works.
I am a long-time SAP consultant and now SAP researcher, and it is difficult to recollect SAP using the term machine learning in any of that time…..until very recently, that is. However, as soon as SAP using the term, it has claimed to be the world experts in machine learning. In fact, in one video for its Leonardo product, it claimed to be “the only company” with machine learning to help its customers.
This is a typical video for Leonardo, SAP’s IoT and ML solution.
The term machine learning has begun to appear on SAP employees with startling speed. People with no background in forecasting or statistics and from utterly unrelated backgrounds ranging from CRM to Hybris to Fiori now have machine learning attached to their titles on LinkedIn.
Here is one example…
Digital transformation lead at SAP (Hybris, S/4Hana, Logistics, Machine learning)
What an exciting combination of skills!…..ML has nothing to do with Hybris or S/4HANA or logistics. ML is now just something to add to the new sexy term.
SAP has a video (that is now taken down) that categorized an ML approach, but the approach applied is ARIMA, which is a selection of options that include Exponential Smoothing, Seasonal Trend Decomposition, Trigonometric Box-Cox, Holt-Winters.
Someone should tell SAP that none of these methods is classified as a method of ML. They are traditional univariate statistical forecasting methods. ARIMA is primarily used as a univariate statistical approach (although it can be used for multivariate). But the video shows quite clearly that univariate analysis is being performed. ML is always multivariate.
Another video, which is also taken down, proposes ML to automate intelligent decision making in a company. It sounds like artificial intelligence and makes it sound like ML works like Skynet from the movie the Terminator. But ML algorithms don’t work like this at all. They are highly specific and run by data scientists or analysts, and they must be set up and will address a narrow area. In the scenario outlined by the video, the company that purchased this software would not need people really outside of performing physical work, as SAP “Skynet” would be doing all the thinking.
Repeating Claims Made in the Past That Never Occurred
Something to observe is how close SAP’s claims are in machine learning to its earlier claims about analytics. In a video (now taken down) which was made over 4.5 years ago. At that time, the term was “analytics.”
When visiting SAP accounts, none of the things described in this video are apparent. SAP has migrated its claims around “predictive analytics” to “machine learning” now that machine learning is hot and predictive analytics are not. In a few years, these same claims currently being used to sell machine learning software and projects will be migrated to whatever is the new term.
Fact-Checking on SAP’s Predictive Analytics Claims
The claims appear to be almost identical, but instead of using the terms predictive analytics and predictive algorithms, SAP merely substituted the term machine learning for the older terms and now makes the same claims but with a different term. SAP’s analytics solutions keep permutating and dying off.
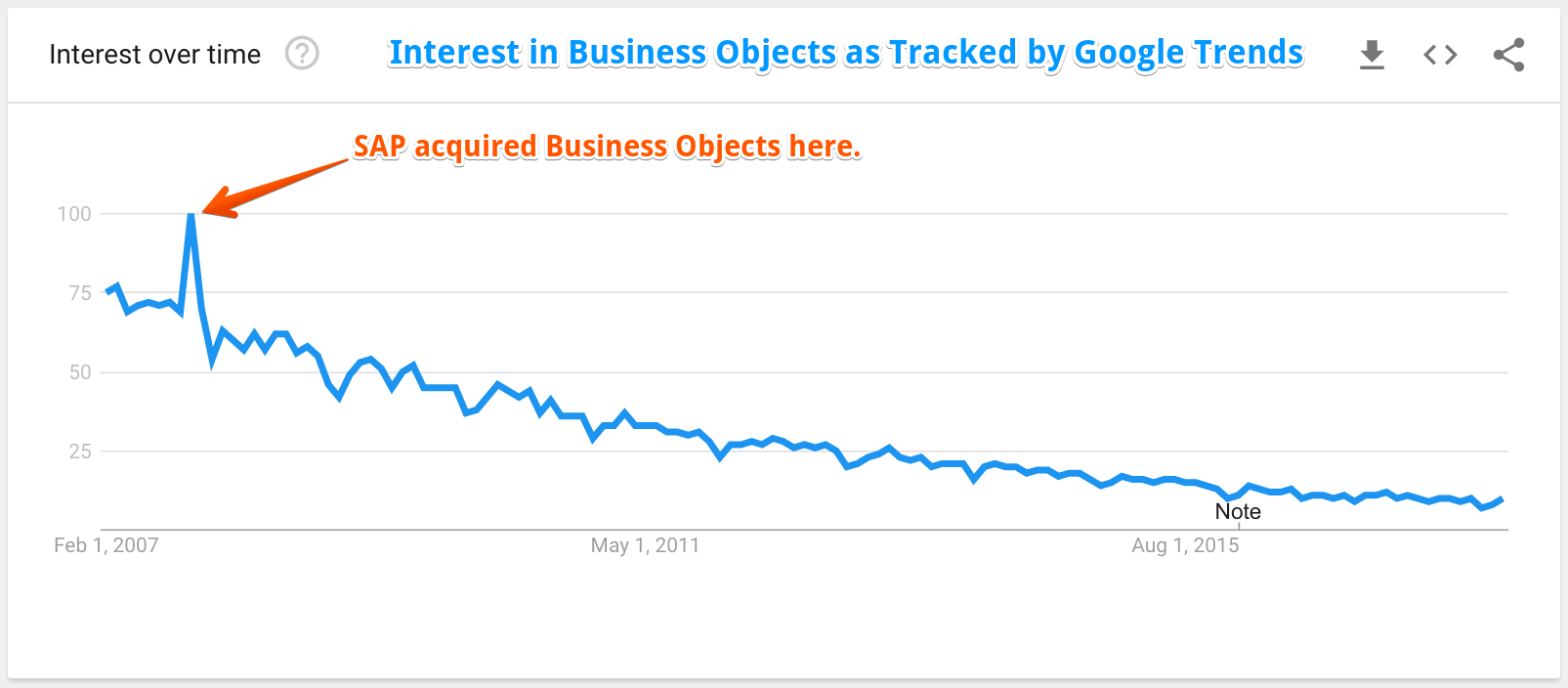
As tracked by Google Trends in Business Objects, interest has declined by a factor of 7.5 since before the SAP acquisition. For a while, Business Objects was going to be ported to most of SAP’s accounts after the purchase, but now Business Objects is in a steep decline and is barely discussed on SAP projects.
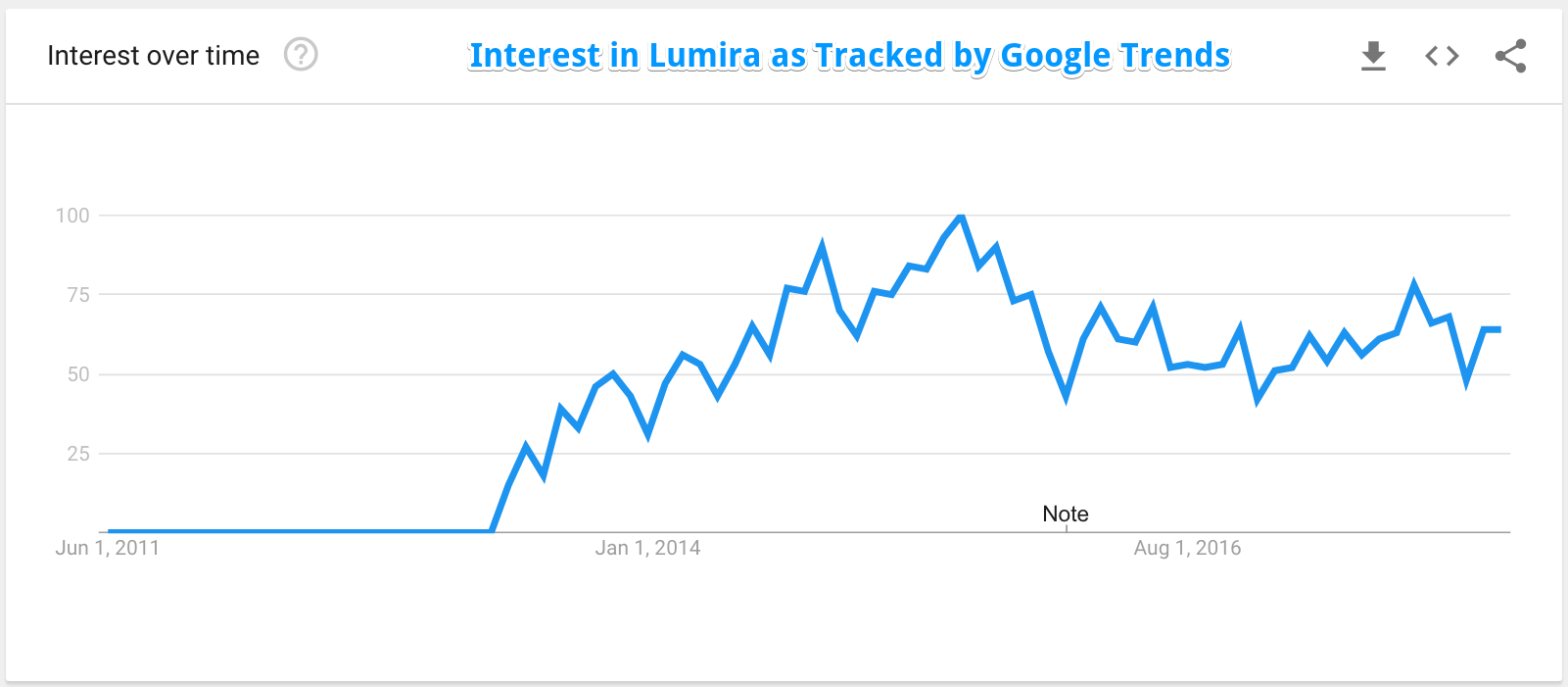
Then SAP Lumira would be the “Tableau killer,” but it has disappeared mostly from the market, although interest in the product is still there. Still, it is declining.
What Happened with HANA Predictive Analytics?
- The analytics that came with HANA never panned out. Companies that use HANA for analytics primarily use it with the BW, which is challenging to work with as it ever was before HANA was introduced.
- The idea was that companies would perform analytics in S/4HANA with Embedded Analytics. As we covered in the article The Future of SAP Embedded Analytics, Embedded Analytics never really developed. So few customers are live on S/4HANA that at this point, it is not a relevant discussion point.
- In one part of the video, a hand swipes through various offerings in a “library” represented by cards. The cards are linear regression, K nearest neighbor, K-means, C4.5 decision tree, and ABC classification. K nearest neighbor is an ML classification algorithm. K-means is a clustering ML algorithm, C4.5 decision tree is an ML classification algorithm. The ABC classification classifies products based upon revenues and has nothing to do with the other items on the list.
Therefore, SAP stated that it had ML algorithms in 2013, but for whatever reason, it called them predictive analytics.
In this way, ML can be seen as a way for SAP to rebrand predictive analytics. Something that is already tried and was not successful in doing. The screens in this video look fantastic, but again, I have never seen anything that looks remotely like this on any of my SAP clients. Furthermore, the video is highly confusing because it discusses using predictive analytics with HANA. However, HANA is just the database. This would be like saying one is performing predictive analytics with Oracle 12c or IBM DB2.
SAP Strives for Maximum Confusion
SAP has a way of explaining things so that they are maximally confusing, and the boundaries between what the different items do are blurred. By listening to SAP, you know less about a subject than before you started. SAP’s statement regarding analytics does not describe the analytics application that sits on the database. This would be the same as saying one is running ERP with Oracle 12c or IBM DB2. Analytics and ERP systems are the application. You work in the application. The application sits on the database.
What tool is being recommended to work with HANA? Does it seem like a tool called Predictive Analytics? That is what the screens shown in the video are? Does that product exist? It is 4.5 years since this video was published, and where is the SAP product Predictive Analytics?
SAP’s Extraordinary History of Puffery
To appreciate SAP’s latest attempt to co-opt a term, one must review SAP’s history of co-opting other areas.
Previously, with HANA, SAP pretended that they were better at databases than Oracle, IBM, or Microsoft. That assertion has had seven years to be evaluated, and it has turned out to be untrue, which we have covered in articles like What is the Actual Performance of HANA?, and HANA as a Mismatch for ERP and S/4HANA.
Now SAP is trying to propose that they are the best company for machine learning with virtually zero histories in even linear regression.
However, other large vendors like SAS have been deep into mathematical programming types that are the basis for machine learning since their inception, with SAS owning a major development language for statistics. With HANA, SAP proposed it was better than Oracle in databases. Now with machine learning, SAP is saying that it is better with statistics and algorithms than SAS.
Using Machine Learning
Machine Learning is an incredibly misleading term that seems, the less ethical the software vendor, the more they are willing to proposing magical improvements from the usage of the technologies that underpin the term.
SAP is one of the least “reality bound” vendors that we analyze, so naturally, they have recently come out of nowhere to tout all their great machine learning conquests. We expect machine learning to be SAP’s new “girlfriend or boyfriend” for a while until something else topical arises, and then SAP’s marketing department with tires of its current “girlfriend or boyfriend” and move on to the next.
Machine learning describes a series of mathematical approaches to data analysis and a prediction that apply to multivariate data sets. Most forecasting today in business is univariate…. so for example, sales history. Machine learning means the use of multivariate data sets. Thus sales history + weather or + product family or + economic factors, etc..
How machine learning is really at least in part old wine in new bottles is the analysis of how many of the machine learning algorithms for the programming language R are categorized as the following:
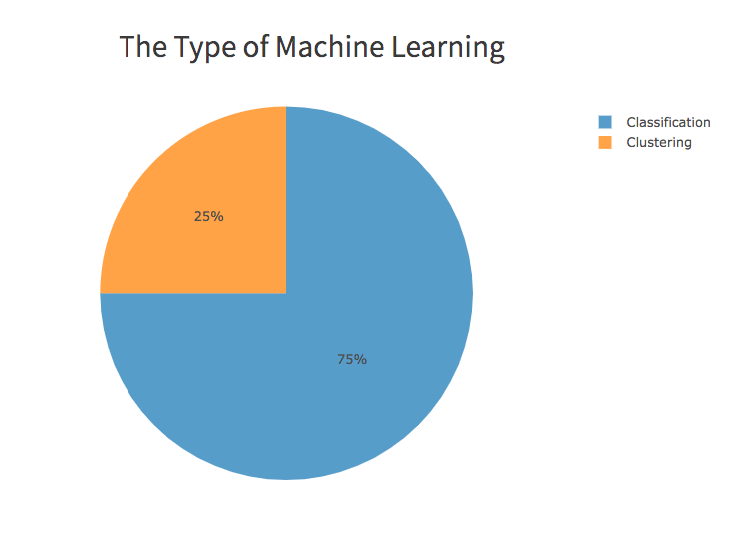
Classification and Clustering
Classification places observations into buckets, and the classifier algorithm performs this. If the classification were known, then it would be assigned already as a field. So, for instance.
The Brightwork Database and Data Warehouse Scoring Criteria
| Criteria | Criteria Definition |
|---|---|
| 1. Database Type | Does the database fall into the category of a relational, document, column, graph, etc.. |
| 2. Core Market | This is where the database tends to be used with the highest frequency. |
| 3. Memory Optimized or All In-Memory | Determines whether the entire database is run as loaded into memory. |
| 4. Price Score | Prices vary greatly for databases, a major reason being the comparison of open source and commercial databases. |
| 5. Maintenance Overhead Score | One of the least discussed features of a relational database. Maintenance overhead is determined by factors ranging from the SQL used by the database, to the ease or difficulty of configuration to the documentation that supports the database. |
| 6. Licensing / Audit Liability Score | Databases are often purchased without considering the long term licensing and audit liabilities. And even among commercial vendors (there is no auditing for open source), there is a large variance in audit likelihood per vendor, as well as the potential payouts. |
| 7. Usability (i.e Loved/Hated Score) | This score is taken from Stack OverFlow's "most loved and most hated" which is their poll of developers preferences with respect to databases. In the case of HANA, it is not rated by Stack OverFlow, because it is little used, so we inserted our own value based upon feedback from the field on HANA. |
| 8. Functionality Score | This is what the database is capable of doing. This is not a scoring of how easy or difficult it is to bring up functionality within the database. |
| 9. Managed Service / No DBA to Install, Patch or Upgrade | Is the database offered as part of a managed service like that offered by AWS. |
| 10. Autopartitioning / Autoscales | The ability to automatically adjust to scale. |
| 11. Pay Per Section / Per Hour | A function of the availability of the database on cloud service providers that off this capability. |
| 12. Pay Per Storage Used / Not Per Processor | This is a function of how the database is priced. Oracle, for instance, is priced per processor. |
But the intent is to run the algorithm such that the new classification can be found, and for forecasting purposes, be used to perform forecasting. The desire is to find a classification that has predictive power. Interestingly, classification is often performed with logistics regression, regression with the dependent variable that is not numeric but is a category (So Blue, Green, Red, etc..)
The way ML algorithms are often classified is by being..
- Classification or Clustering, and then
- Regression or not regression.
That is, they are often both classification and regression or some other combination.
However, as a classification is a type of regression, we can see the thread of ML coming back to regression.
Clustering is similar to classification but is attached to the graphical presentation of data, hence the algorithm’s ability to separate a scatter plot into clusters. Clustering is far less common in the business world than it is in the sciences.
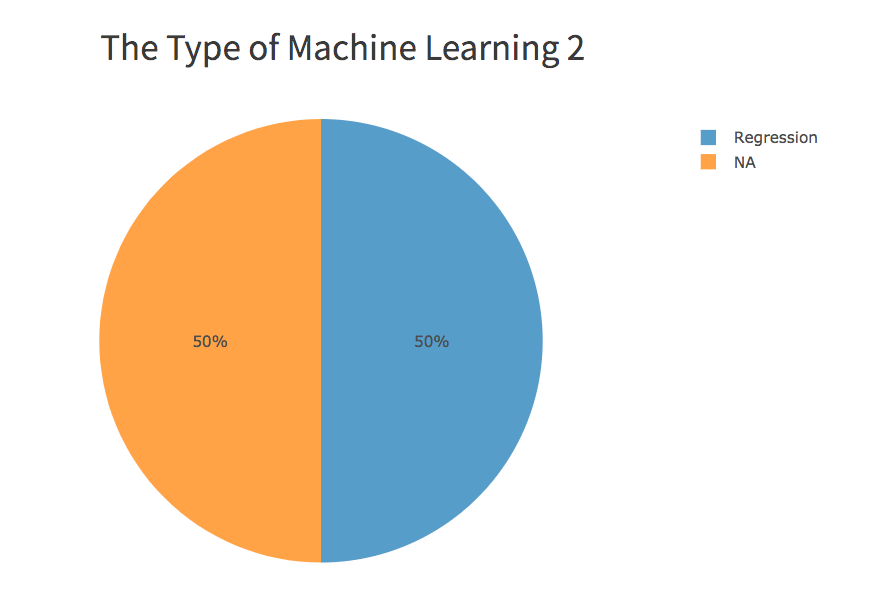
Of the most common ML algorithms, 1/2 is a type of regression.
Percent Regression, Percent N/A
Machine learning is a branch of data science. And surveys into the algorithms used by data scientists show that regression is the most common method used to find relationships among data scientists. Other methods are used, but it should be remembered that data science is still a growing field, and the most advanced data science activity is not in mainline businesses. They are in the sciences and high finance. So the most advanced data science methods are applied in specialized areas of the economy.

It’s time for a cork check on the hype around machine learning! Many of these ML methods have been around for a long time.
How New is the Bottle of Machine Learning
Hardware and software keep improving, so in essence, progress is continual. I was checking a functionality recently in software that was written around 18 years ago. It required a detailed 3.5 pages of code with various if statements to process what is processed today with a single command. But with ML, there seems to be a clear intent to explain it as something completely new. Yet, regression has been around for a very long time. Regression is available in SAP DP, which is a supply chain forecasting application, for example. However, it is not very much used. This is because it is usually too complex to be implemented in a business setting with short timeline expectations for improvement. More complex methods take more training time, which usually is also in short supply. This is jarring to people who do not work on forecast projects, but my observation from working on many of them and having been on forecasting projects since the mid-1990s.
Sometimes the topic of environments that use SAS for forecasting comes up. SAS is a sophisticated high investment type of forecasting product (primarily that they have a more standard forecasting product, but it’s not their bread and butter). However, it is essential to recognize that SAS is infrequently outside of just a few industries. For example, SAS is very popular in finance and insurance. The budgets are far more significant than usual in the cases, and there is much more time to concentrate on producing sophisticated forecasts for a smaller number of forecasted items.
Conclusion
Machine learning has been around for a while, although it has recently been picked up as a marketing term for some vendors, and this push is making ML become far higher profile than before. This does not demonstrate success with ML on projects. It does indicate that marketing departments at companies are publishing it and expressing it as something important to customers.
Throughout SAP’s history, they have had precisely zero to do with machine learning. All that SAP is doing is putting open-source algorithms into their software (perhaps that is) and declaring that they are all about machine learning. This will be true for a while but will most likely change when a new “girlfriend” comes along and SAP switches to whatever happens to be trendy at that time. When that happens, we can expect, as with predictive analytics, for the same claims to be recycled once again and applied in this case to XYZ rather than to machine learning or predictive analytics. With no one fact-checking SAP, SAP is free to repeat this strategy out into the future.
SAP has no real interest in making any of these things work for customers. Their enthusiasm is in co-opting to create something enticing to make sales and pump up the stock price by tricking Wall Street. If SAP had a real interest in making things work, they would go back and reinvest in making the things they made previous claims they failed to meet. But they don’t do that. SAP is primarily a marketing organization that jumps from hot topic to hot topic at this point in its lifecycle. That is the luxury of a company with such thorough control over the media output published about them and the consulting advice that their partner consulting firms communicate to customers.
But there is no reason to listen to SAP on machine learning, and there is no reason to wait for them to add machine learning items from the public domain and then claim they are something SAP came up with to “Leonardo.” The algorithms are available to use without SAP and without waiting for SAP to move from pretending to have something to do with machine learning to figure out machine learning.
The Undiscussed Issue Around Machine Learning for Forecasting
The problem with machine learning, as presented for forecasting, is that the current error measurement within companies is undiscussed. Many projects, including forecast improvement projects, are sold without any consideration for the outcome. The intent is to make exaggerated claims and then stall the project’s measurement of results to accumulate the maximum number of billing hours. This is currently a massive problem with AI/machine learning projects.

If your forecast improvement project is sold based on pretenses, you do not want the forecast value to be measured. For this reason, IBM postpones forecast error measurement on their projects as long as possible, preferring to talk about how significant the INPUTS are and the tremendous future potential for forecast improvement.
IBM has been obvious that they measure success by the number of projects sold, not the forecast value add as we cover in the article How Many AI and Machine Learning Projects Will Fail Due to a Lack of Data?