
How to Understand Why HANA is a Mismatch for S/4HANA and ECC
Executive Summary
- SAP has proposed that HANA is a perfect fit for ERP. However, the evidence is that there is no advantage of HANA for ERP systems, but there are many disadvantages.
- In this article, we discuss where our data comes from related to HANA’s mismatch.

Video Introduction: S/4HANA’s Mismatch with ERP Systems
Text Introduction (Skip if You Watched the Video)
SAP restricted S/4HANA to just the HANA database, breaking with decades of having their ERP system be database independent and creating great inconvenience and higher cost for customers. SAP misrepresented this restriction in choice and massive inconveniencing their customers by stating that it was done for SAP customers because no database would ever compete with HANA. And one reason for this was that HANA had achieved zero latency on my query passed to the database, while every other database had latency. Sufficit to say, our research showed major cracks in these claims. You will learn whether HANA is a fit for ERP systems.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Notice of Lack of Financial Bias: We have no financial ties to SAP or any other entity mentioned in this article.
- This is published by a research entity, not some lowbrow entity that is part of the SAP ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on SAP is provided by SAP, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, SAP pays off all IT analysts -- who have the same concern for accuracy as SAP. Not one of these entities will disclose their pro-SAP financial bias to their readers.
What SAP Says About HANA and MRP
SAP has proposed that with HANA, there will be no more batch processing. The following is how they phrased this proposal.
“No More Batch — All Processes in Real-Time”
“…enterprises can dramatically simplify their processes, drive them in real time and change them as needed to gain new efficiencies – no more batch processing is required.”
No Batch Processing in S/4HANA?
SAP proposed that there will be no latency of any process in S/4HANA due to HANA. This means that no matter what process the company sets S/4HANA to do — that process will be completed in real time. If we look at MRMRP is commonMRP to be performed on a “net change” basis. This means that only product location combinations that have had a change are processed.
The reason for this is to limit the time spent processing. MRP is common to take several hours, and this job is typically scheduled every weekday in the evening not to disrupt business operations. Then, on the weekend, a second MRP planning run is usually scheduled that performs a complete recalculation of all relevant product locations.
HANA as Perfect for MRP?
In an article titled SAP’s HANA Deployment Leapfrog’s Oracle, IBM and Microsoft published in Readwrite. The following quote reiterates this popularity.
During a multi-site news conference in New York, Palo Alto Calif., and Frankfurt, Germany, SAP demonstrated HANA’s speed using its manufacturing resource planning software. In Palo Alto, Hasso Plattner, SAP co-founder and board chairman, said the database will eventually be available in all products, whether on-premise or in the cloud. “All SAP products will go HANA,” he claimed.
HANA’s primary benefit is read access, which is beneficial for analytics. For MRP, the processes used are far more critical, and one will not receive the same benefit. And it turns out that these statements by Hasso Plattner regarding MRP performance were false.
The Actual Problem with MRP Performance in SAP ECC
After seeing many MRP instances, the only situations that we have seen where MRP runtimes were a problem where there were system setup issues. One issue, for example, is when there are a large number of invalid location product combinations that must be processed.
With HANA, SAP claimed, there would be no latency. We should make sure we realize how large this claim is. This means that it should be possible to schedule a complete recalculation of the entire combination of product locations in the middle of the day, as the calculation will all be instantaneous. Two minutes later, an entire MRP run of every product location should be able to be performed, and once again, the time taken to run MRP should not be measurable. That is the definition of “no latency.”
This is a peculiar claim. And there are several reasons for this. Given today’s hardware and software capabilities, unless the model is small, it is not possible.
The first reason is that given today’s hardware and software capabilities, unless the model is small, it is not possible.
The second reason gets into what MRP does versus what HANA is. If one takes most of the ERP batch processes, but MRP is an excellent example, the bottleneck on processing is the calculation. That is the microprocessor load. Not the database load. So it would not be feasible that HANA, which only speeds analytical processing, to do very much to speed MRP or other types of processor intensive activities.
Hasso Plattner Weighs In
On November 30, 2015, Hasso Plattner, one of the co-founders of SAP, published “How to Understand the Business Benefits of SAP S/4HANA Better.”
“I just heard of a Chinese fashion manufacturer who installed SAP S/4HANA and reports a game changing improvement of the MRP2 run from more than 24 hours to under two hours. My advice for the smaller and midsize SAP Business Suite customers is to carefully watch the early adopters, soon approaching 2000, especially in related industries.” ‒Hasso Plattner
There are several curious things about this statement. First, This occurred before November 30, 2015. However, Hasso implies that this company moved from the pre-HANA version of SAP enterprise software — known as ECC — to HANA. (Yet, this earlier software runs on HANA.) He states that the Chinese company purchased and implemented S4 EM. However, as of June 2016, S4 EM was still some way away from the full release. Only S4 Finance — previously called SAP Simple Finance — is available for purchase.
So the first question is, how is it possible that this Chinese fashion manufacturer was even using S/4HANA for MRP.
But if we leave this issue to the side for a moment (it is an important question, but let us take this in stages), the matter of how placing MRP on an analytics database versus a transaction processing database made such a difference in the MRP runtime is an important one.
- It is essential because, technically, the claim does not make sense.
- Secondly, information from the field is that MRP does not run faster on HANA, but instead that it runs slower.
Feedback from Customers on MRP on HANA
The following are descriptive quotes from a person from a customer that uses MRP on HANA. They are consistent but more detailed than similar information we have received from multiple sources.
“Running MRP on HANA and the performance of the MRP job is horrendous. It runs in 8-12 hours, while the same amount of data on MSFT SQL (Server) ran in 1 hour. So far I’m quite unimpressed. Especially considering how much $$$ we spent!”
Unsurprisingly the output of MRP is not used as he describes in the following quotation.
“We don’t use the results of MRP, but we use the output to feed downstream systems. Across the board transactional performance is horrendous, the stats speak for themselves.”
This brings up a question of why MRP is being run at this customer. Is this simply to justify having gone through the expense of buying and implementing SAP?
MRP engines are easy to find and can be integrated into SAP. This customer could simply have an external MRP engine to perform the processing and then put the results back into SAP.
And of course, this would allow the customer to use the results of MRP in the system — another benefit.
“Our ATP process is a heroic effort that takes an entire weekend with not a moment to spare. Jobs that we would usually run once a day in now take 8+ hours. Once we have all of our global companies in the same instance, I have no idea how our jobs are going to run with limited windows for downtime.”
The consensus of what we hear from multiple sources is certainly not “no batch processes and everything in real time” but rather significant MRP performance problems on HANA. These are problems that did not exist when MRP was run on Oracle or DB2.
These are problems that did not exist when MRP was run on Oracle or DB2.
A Lack of SAP Claim Verification
SAP often makes statements indicating that improved performance drives the migration to S/4HANOther amorphous examples typically accompany these statements (e.g., S/4HANA performance improvement during end-of-period close.) These statements are not checking out from the feedback that has come in from multiple SAP customers.
After extensive analysis, it turns out that these statements are not checking out from the feedback that has come in from multiple SAP customers.
Furthermore, Brightwork Research & Analysis has been the only entity specializing in SAP that has questioned whether the claims made by SAP in this area actually made any sense. Our view is that they never did make any sense, and they have been targeted at executives that think they can guess if SAP is telling the truth without relying on people with the right background to verify these claims.
Nothing to Say, Gartner, and Forrester?
Both Gartner and Forrester have been notably quite silent on whether any of SAP’s claims for HANA on transaction processing made any sense. This brings up the question of whether they have any interest in verifying information or see themselves as merely repeating mechanisms of vendors with the largest analyst budgets. Critiquing a vendor that pays you so much money would be biting the hand the feeds you. Gartner and Forrester can simply “look the other way” as one proposed capability of HANA is proven false after another.
Taken another way, if SAP pays about every media source, what media source has any interest in contradicting SAP? Isn’t it necessary to oppose vendors if the information provided by vendors is inaccurate? What is the definition of independence? In my last article, I quoted Gartner saying that “bias at Gartner is a non-issue.”
Not only Gartner but many other IT media entities, it seems like not only a massive issue but an issue that is not going away.
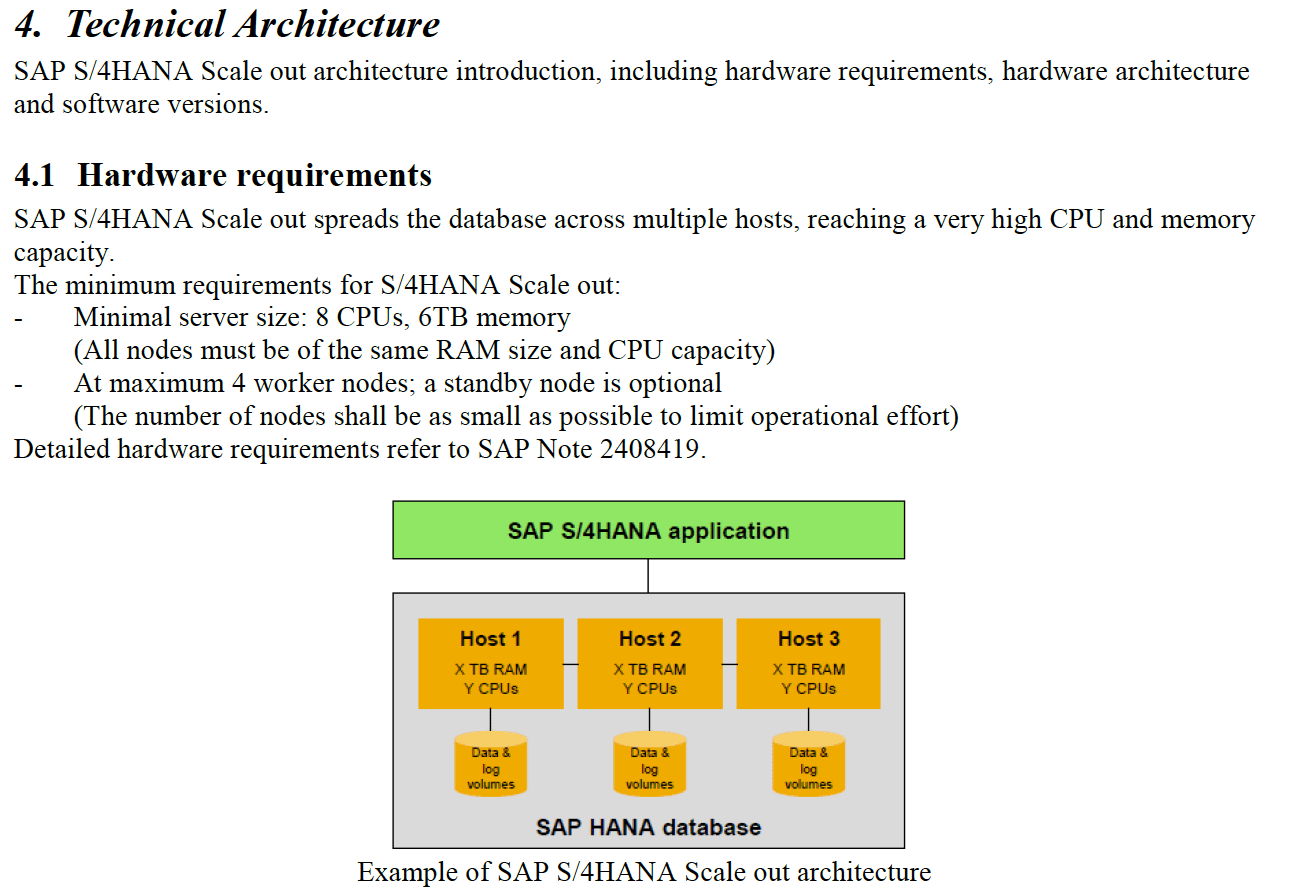
A Major Advantage for Using with ERP Systems?
Column based databases like HANA are not an advantage when the database in question supports an application like an ERP system or any other transaction processing system.
This is because transaction-processing systems tend to access all of the fields in a row. However, when the application in question is analytical, technically known as OLAP, then the database design/table configuration is a disadvantage because the typical query only accesses a few of the fields or columns in a table.
This is explained well in this paper from Oracle on their 12c product, another in-memory database.
“Oracle Database has traditionally stored data in a row format. In a row format database, each new transaction or record stored in the database is represented as a new row in a table. That row is made up of multiple columns, with each column representing a different attribute about that record. A row format is ideal for online transaction systems, as it allows quick access to all of the columns in a record since all of the data for a given record are kept together in-memory and on-storage. A column format database stores each of the attributes about a transaction or record in a separate column structure. A column format is ideal for analytics, as it allows for faster data retrieval when only a few columns are selected but the query accesses a large portion of the data set. But what happens when a DML operation (insert, update or delete) occurs on each format? A row format is incredibly efficient for processing DML as it manipulates an entire record in one operation i.e. insert a row, update a row or delete a row. A column format is not so efficient at processing row-wise DML: In order to insert or delete a single record in a column format all of the columnar structures in the table must be changed.”
This points out that for inserts, deletes, or updates — which a transaction processing system — like an ERP system — does all the time. The column based table is slower than the row based — or what is known as the relational database (although using the term relational to differentiate row based on column-based databases is not technically accurate as they are both relational databases — the distinction is the format and type of tables used)
ERP on HANA Processing Problems
Getting back to the main point of this section, ERP on HANA will not speed the processing of ERP systems for most of what ERP systems do. This is Oracle’s point in this quotation from John Soat.
“SAP has not published a single benchmark result for any of its transaction processing applications running on HANA.”
I agree with John Soat that there is a very reasonable explanation for why SAP does not publish this…because the benchmarks are not impressive.
Where is Our Data Coming From?
The information that is provided below is from multiple sources. Some are from actual client sources. None of the sources is interested in being identified so that they won’t be.
Furthermore, we have more information regarding details than we will provide in this or other articles. The reason for this is related to source protection. The way that we can provide this type of information is that the sources aren’t identified or can’t be traced by SAP through the detail that we offer.
Regarding our credibility, the reader can review our SAP prediction accuracy list.
Our Independence
Brightwork is not paid by SAP or any other database vendor (or any non-database vendor for that matter.) We have no incentive to push one database above another. We don’t own stock in any database vendor or any other financial tie. Furthermore, our analysis in this area should not be seen as a general endorsement for any non-SAP vendor.
This differentiates us from Forrester and Gartner, who are paid by database vendors. Forrester sometimes declares these payments. Gartner never does.
The Problem Between HANA and ERP
The data we have analyzed show the following performance features of HANA.
- Simple queries for analytics run quickly but not any more rapidly than competing databases.
- Complex queries for analytics run more quickly than a row-oriented database, but not as fast as competing databases.
- Transaction processing (things like posting goods issue, decrementing inventory, etc..) runs significantly slower on HANA than on row-oriented databases. That is even when accounting for HANA’s better hardware.
- Processor intensive operations run significantly slower on HANA than on row-oriented databases. Again, this is even when accounting for HANA’s better hardware. An example of a processor intensive activity is MRP. See our article How to Interpret HANA’s Problems with MRP.
See our other article which questions Why Do Companies Continue to Run MRP from ERP systems.
The problem with this information on HANA’s performance profile? ERP systems’ primary activities are number 3 & 4, transaction processing, and processor intensive operations. Not 1 & 2. This means the overall system will run slower if the transaction processing and processor intensive activities are disadvantaged.
This is a severe problem for HANA’s value for ERP systems. The things HANA does well are not related to what ERP primarily does.
Transaction Processing Problems
HANA has had persistent problems in what should be the primary focus of any database that supports an ERP system, transaction processing. Transaction processing is the most important thing that any ERP system does, and SAP’s marketing around the importance of analytics has not changed the primary processing type of ERP.
On April 10, 2018, Lenovo published the technical paper, Lenovo SAP S/4HANA Scale out – Cycle 1.
This paper included some inaccuracies, which should not be surprising as Lenovo is an SAP partner and has a series of products they are trying to sell connected to HANA.
Notice the hardware specification below from the Lenovo paper.
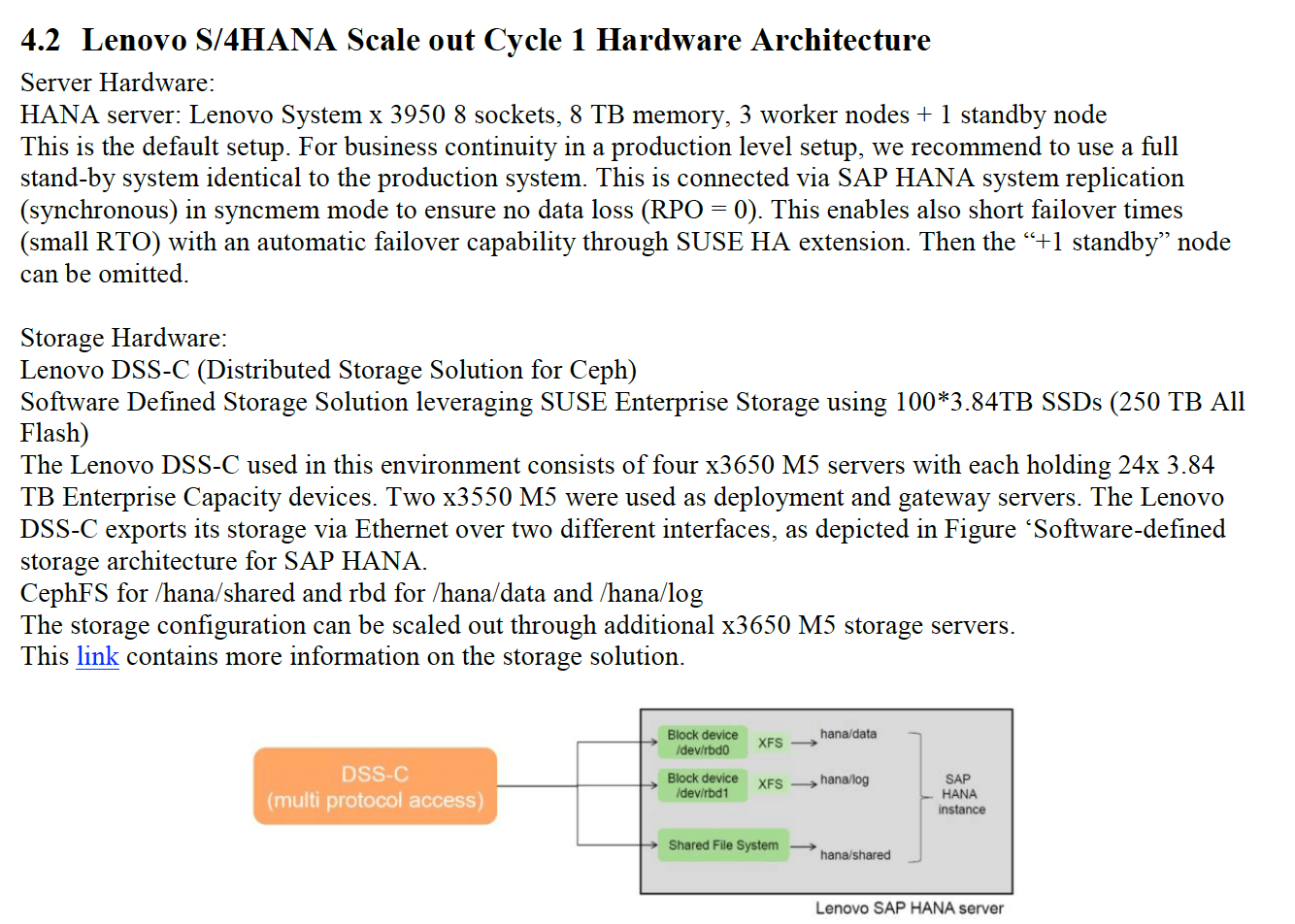
The HANA box has a higher hardware specification, but it is hidden with the AnyDB/ECC server configuration not called out.
Natural questions that arise.
- Where is the hardware configuration listing on the AnyDB/ECC server?
- How is the reader to know if the hardware is comparable? As we have pointed out in the article, How Much of Performance is HANA?, many improvements that have been seen from HANA are due to the entity testing HANA against older hardware and previous versions of AnyDB.
Either Lenovo does not know how to list the specifications of the box, or more likely, Lenovo is excluding the AnyDB/ECC listings to obscure the fact that the hardware is not remotely comparable. How can this go unnoticed by those that read these studies?
Now, look at the transaction processing.
![]()
Why are the exact comparisons redacted? Secondly, how is anyone to know how much of the improved transactions are from the HANA boxes higher hardware specification? And SAP promised massive improvements in performance across the board, so why are any of the transactions negative?
The redaction is quite odd, as there is no reasonable explanation of why this should be.
Analytics on S/4HANA?
Now one could construct a scenario where a bunch of analytics is performed in ECC/S/4HANA. SAP has stated this as their vision. The concept is that all analytics would be performed inside the ERP system. Let us go back to the Lenovo study.

This is compared against an older version of most likely either Oracle or DB2, which did not have the multimodel capability (that is column-oriented with row-oriented). However, why are any of the analytic scores slower than the older database versions?
- Observations from the field show HANA underperforming all competitor databases, even SQL Server, even in analytic workloads. This level of improvement, up to 2846%, shows the hardware difference between the ECC box and the HANA box.
- Once again, we have redacted actual scores. What is being hidden here?
Conclusion
Columnar databases are a disadvantage for ERP systems or any transactional processing system. That is what makes SAP’s statements SAP entirely inaccurate. Secondly, in any ERP system, data can be aggregated and updated to just a few hundred tables. These tables can be made columnar — while the rest of the database stays as row-based (or as is known as relational). This is the design deployed by Oracle 12C, and it calls into big issue the design used by ERP on HANA. Details on this plan are available in this article.
These tables can be made columnar — while the rest of the database stays as row-based (or as is known as relational). This is the design deployed by Oracle 12c, and it calls into big issue the design used by SAP for ERP on HANA. Details on this plan are available in this article, Which is Faster, HANA, or Oracle 12C?
Thus there is no way to see the HANA performance profile as anything but a net loss in ERP performance.
This means that the migrations of ECC to HANA and implementations of S/4HANA, what there are of them, resulting in performance degradation for the companies that implemented them.
Furthermore, SAP customers paid a very high premium for a reduction in performance.