
Is SAP’s Warm Data Tiering for HANA New?
Executive Summary
- SAP is telling customers that they can use data tiering in HANA to use innovation in database design.
- How accurate is SAP data tiering being new?

Video Introduction: Is SAP’s Warm Data Tiering for HANA New?
Text Introduction (Skip if You Watched the Video)
SAP has communicated a new item for SAP HANA. SAP has proposed that this new item is an amazing technological breakthrough where the data is processed in the computer’s memory but then written to the disk for something called “persistence.” But it turns out that this item is not new but is an example of SAP simply renaming something old and saying they invented it. This is such a ludicrous level of lying, that it deserves an explanation. You will see how SAP deceives its low information customers into pretending its copying is innovation.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Notice of Lack of Financial Bias: We have no financial ties to SAP or any other entity mentioned in this article.
- This is published by a research entity, not some lowbrow entity that is part of the SAP ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on SAP is provided by SAP, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, SAP pays off all IT analysts -- who have the same concern for accuracy as SAP. Not one of these entities will disclose their pro-SAP financial bias to their readers.
Our Analysis
Let us begin by reviewing the quotes from SAP.
“SAP HANA native storage extension is a general-purpose, built-in warm data store in SAP HANA that lets you manage less-frequently accessed data without fully loading it into memory. It integrates disk-based or flash-drive based database technology with the SAP HANA in-memory database for an improved price-performance ratio.”
This is amazing.
Translated for the laymen, it means that SAP’s super-advanced technology enables companies to use both memory and disks and even flash drives in something called a “server.”
We have a top-secret image shown below. These photos of a prototype of the device used by HANA were smuggled out of SAP at high risk to our agents.

The server is a piece of hardware with the memory, the disk drives, and the flash drives inside a metal box.
But the story gets even better. Some of the data does not need to be accessed all of the time. This is what SAP calls “warm data.” Let us review the SAP explanation of this new data classification.
“Between hot and cold is “warm” data — which is less frequently accessed than hot data and has relaxed performance constraints. Warm data need not reside continuously in SAP HANA memory, but is still managed as a unified part of the SAP HANA database — transactionally consistent with hot data, and participating in SAP HANA backup and system replication operations, and is stored in lower cost disk-backed columnar stores within SAP HANA. Warm data is primarily used to store mostly read-only data that need not be accessed frequently.”
While undoubtedly impressive, it is different from SAP’s earlier statements about HANA, where HANA was to be better than all other databases because all of the data was to be loaded into memory. And through shrinking the database size, you could…
“Run an ERP system off of a smartphone.”
In an article published in 2013, John Appleby stated…
“HANA was the only in-memory database with full HA.”

The SAP HANA Native Storage Extension?
SAP calls this SAP HANA Native Storage Extension. However, it is actually nothing. It is merely a restatement of what all the competing databases have been doing for decades.
It’s called memory optimization.
Let us look at SAP’s graphic, where they describe their contraption.
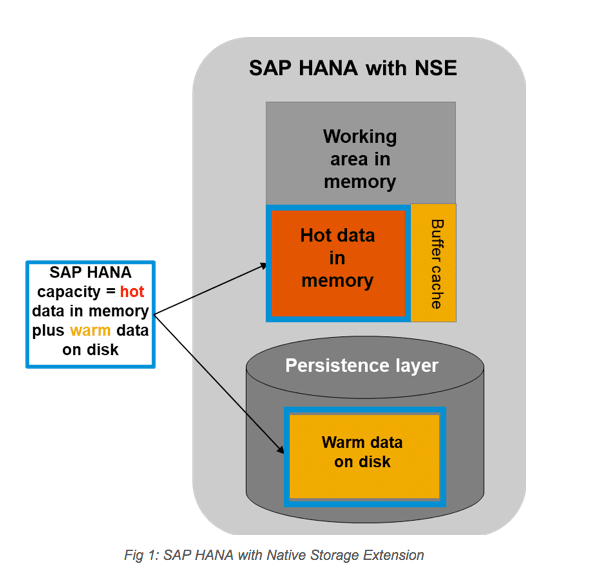
We congratulate SAP on this observation.
What is described above is a standard memory-optimized database. The same design used by other database vendors decades ago and still used to this day. Without being able to load data into memory, it would be impossible to perform a calculation or any processing. One can test this by taking any computer or server, removing the memory modules, and then rebooting the computer or server. But according to SAP, this design is perfect for replacing “legacy databases,” as the following quotation attests.
“The Perfect Architecture to Replace Legacy DBMS Technologies
SAP has a general sizing guidance for HOT vs. WARM data ratio and Buffer Cache size. However, it is ultimately the application performance SLA that drives the decisions on HOT vs. WARM data ratio and Native Storage Extension Buffer Cache size.
For the hardware to implement Native Storage Extension, simply add necessary disk capacity to accommodate WARM data and memory to accommodate Buffer Cache requirements as per the SAP sizing guidance.
The combination of full in-memory HOT data for mission-critical operations complemented by less frequently accessed WARM data is the perfect and simple architecture to replace legacy DBMS technologies. This also eliminates the need for legacy DBMS add-on in-memory buffer accelerators for OLAP read-only operations requiring painful configuration and management.”
But now the question arises,
“If SAP has such a similar design to other databases, why are those databases legacy?”
To this, we have the answer. But before we get to that, we would like to take this opportunity to introduce our innovation.
Introduction the Brightwork Piston Gas/Diesel System
This diagram describes something we have named a “piston.” It comes in two types, an energy source we call “gas” and a second which uses something called “diesel.” Our proprietary design deploys a four-stroke design, which is as follows, Intake, Compression, Combustion, and Exhaust. (Patent pending, so please respect our IP)
We are thinking of deploying this technology in some propulsion systems.
Stay tuned for more details!
Conclusion
SAP’s warm data tiering is nothing new. Furthermore, it contradicts everything SAP said about HANA years ago. HANA is now increasingly backtracking on earlier pronouncements designed to make it appear different from other databases.
From the beginning of HANA’s introduction as a product, SAP was told you could not place everything in memory. SAP told everyone that they did not “understand” and that with their proprietary technology, they had achieved zero latency because of their extraordinary ability to manage memory in a way that Oracle or Teradata, and others could not. This meant loading all data into memory with zero swappings. We had to investigate the HANA documentation to find it was actually memory optimized, and SAP lied about this.
SAP is not an all-in-memory database, nor has it ever been.

SAP receives a Golden Pinocchio Award for making something that all databases have sound innovative.