
Should Machine Learning be Instead Called Machine Identification?
Executive Summary
- Machine learning provides the implication that software can learn.
- In this article, we question whether a different term would not be better.

Introduction
In neural networks or deep learning, the “learning,” if that is the right word, is accomplished by the weights between the nodes being adjusted up or down.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
We begin with the following graphic.
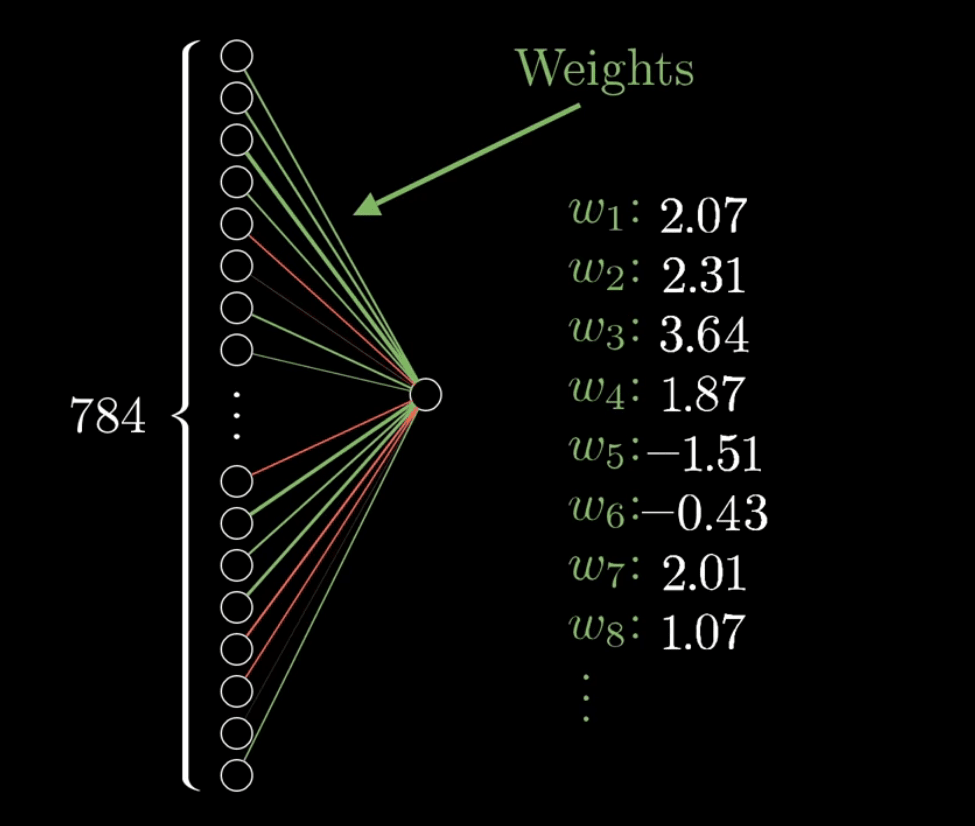
This essentially increases the input nodes’ weights that are most impactful in leading to the next layer or tic tac toe board. And because of dependencies, not all nodes in the prior connected layer are connected to all the nodes in the following connected layer.
*Graphic taken from the video from 3Blue1Brown Series.
The network is designed, and when the training is performed, the weights are adjusted. If the data is fed at one time, this is called batch learning. If the data is trained over time as new data is accumulated, this is referred to as real-time learning.
The Black Box Nature of Deep Learning
One of the major issues with deep learning is its black-box nature. This is explained in the following quotation.
“..neural networks are “black box”; they do what they do, and it is hard to understand what’s inside. To the extent that we might wish to rely on them for things like driving or performing household tasks, that’s a serious problem. It’s also a problem if we want to use deep learning in the context of larger systems, because we can’t really tell the operating parameters — engineer’s lingo for when things work and when they don’t. Prescription medicines come with all kinds of information about which potential side effects are dangerous and which are merely unpleasant, but someone selling a deep learning based facial recognition system to a police department may not be able to tell the customer much in advance about when it will work and when it won’t. Deep learning is brittle….deep learning can be perfect in one situation and utterly wrong in another.
Deep learning systems’ reliance on correlations rather than understanding regularly leads them to hit the buzzer with a random guess even if the question hasn’t been finished. For instance, if you ask the system “How many,” you get the answer “2”; if you ask “What sport?” you get the answer “tennis.” Play with these systems for a few minutes, and you have the sense of interacting with an elaborate parlor trick, not a genuine intelligence. – Rebooting AI
This is reinforced with the following quotation.
But that doesn’t change a fundamental fact of machine learning algorithms: there is no actual computation being done in a neural network.(emphasis added)
Neural networks in this sense are nothing more than sophisticated lookup tables(emphasis added) (which in computer science is referred to as a finite state architecture for a computing device, which is similar to a Turing machine, but without a read/write memory): they prespecify a certain output to a given input. How they do this mapping is hidden from the user (especially when using something literally called hidden layers), and the information about how the network classifies is usually encoded in the structure and spread out through the entire network.
This is because a network isn’t good at remembering things, i.e. storing information dynamically. After it has been optimized for a learning procedure, it basically stays the same while it operates. This is what Burkov means when he says that networks don’t learn, because they only exert flexibility while learning a task, not while executing it.
In light of this problem, some attempts that have been made to build architecture in networks that is able to store information dynamically. They are based on so-called recurrent feedback loops, which could serve as the network’s memory.
The term memory is here again used in Turing’s broader senses: as a means to reliably carry information necessary for computation forward in time. – Manual Brenner
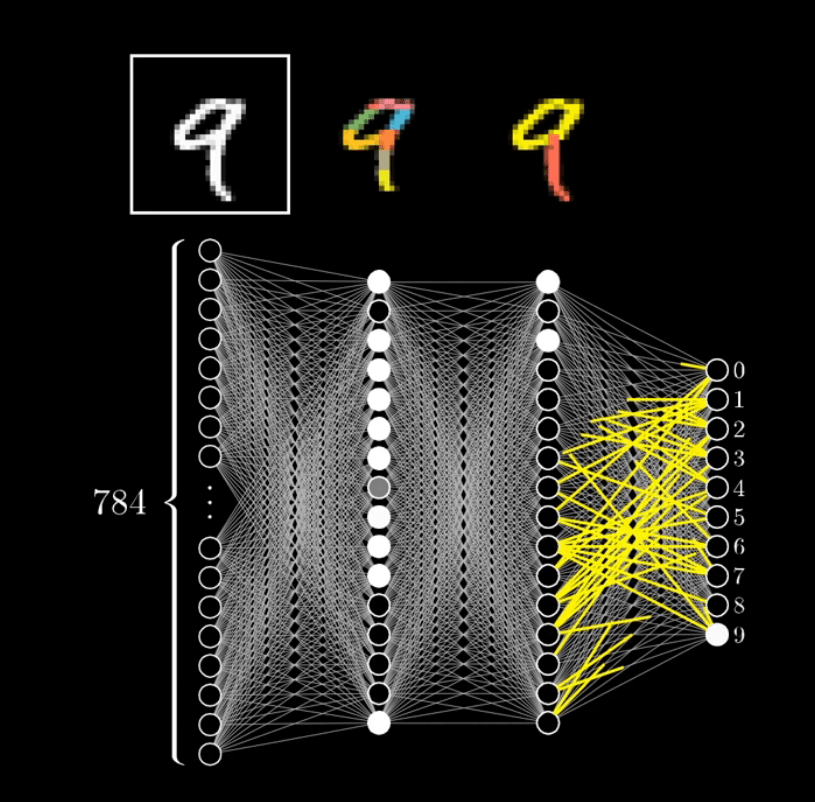
A neural network is a sequential series of tests that take in ordinarily large amounts of input and eventually result in typically one selected output. They are “identification engines,” which makes them so good at language translation, text to speech, speech to text, etc. Learning is less of a useful term than identification. There is a “learning phase” when data is being tested, but this process is much longer than it has to be in many cases. When the neural network is being used, it is not learning. It is applying a pattern to result in identification.
*Graphic was taken from the video from 3Blue1Brown Series.
And it was reinforced with this quotation.
Arguably, the best-known disadvantage of neural networks is their “black box” nature. Simply put, you don’t know how or why your NN came up with a certain output. For example, when you put an image of a cat into a neural network and it predicts it to be a car, it is very hard to understand what caused it to arrive at this prediction. When you have features that are human interpretable, it is much easier to understand the cause of the mistake. By comparison, algorithms like decision trees are very interpretable. This is important because in some domains, interpretability is critical.
This is why a lot of banks don’t use neural networks to predict whether a person is creditworthy — they need to explain to their customers why they didn’t get the loan, otherwise the person may feel unfairly treated. The same holds true for sites like Quora. If a machine learning algorithm decided to delete a user’s account, the user would be owed an explanation as to why. I doubt they’ll be satisfied with “that’s what the computer said.”
Other scenarios would be important business decisions. Can you imagine the CEO of a big company making a decision about millions of dollars without understanding why it should be done? Just because the “computer” says he needs to do so? – Niklas Donges
Differentiating Between the Two Phases of Neural Networks
Neural networks have two phases: the “learning” phase and the second is the execution phase. But using the term learning implies a consciousness on the part of the entity. This is called anthropomorphizing, which is where human characteristics are projected onto non-human things. And it is a constant feature of the human mind. It is, for instance, why we “see” a human face on the moon. It is a cognitive bias and something, therefore, we should be aware of when making observations.
At Brightwork, we use AI to create summaries of articles because it is much faster than doing so manually. We recently added text to speech that is courtesy of Google Text to Speech based upon a neural network. Voice recognition is also, like writing software, undoubtedly useful, as is grammar checking. I am sent articles in different languages, which I could never read without a handy translator like Google Translate. But again, all of these things are narrow applications of AI.
And they are all weak forms of weak AI.
While I leverage these items, I never convince myself that the software I am using is intelligent or that it will be conscious, or like HAL will eventually lock me out of the spacecraft once it learns of my plans to unplug it.
Instead, all of these technologies are running through an automated procedure. Unlike a sentient entity, it does not have any opinion on what it is doing because it is not alive and is merely aping its human instructions. A many-layered neural network may develop those instructions, but this means that the procedure has more layers, not conscious, and not learning. And we were not any closer to creating HAL just because we have more sophisticated automated procedures.
Conclusion
The more exposure one attains to each case study, much like learning a magicians’ tricks, the more explainable the behavior becomes. “Learning” not a very accurate term when describing neural networks, and it anthropomorphizes something that is not conscious of being something conscious. “Identification” is a far more accurate description of what is happening than “learning.”