
The Overestimation of Neural Networks and Deep Learning
Executive Summary
- Neural networks and deep learning have been the primary methods behind the AI boom.
- Neural networks and deep learning are also more limited than generally known.

Introduction
Articles on AI or machine learning very frequently propose that deep learning is where the real “action” has moved. Authors invariably leave out that deep learning has already been through several hype cycles and runs into its specific limitations. The following quotation explains the issues around deep learning.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
We begin this article with the following quote.
“One reason that people often overestimate what AI can actually do is that media reports often overstate AI’s abilities, as if every modest advance represents a paradigm shift.
Practically every time one of the tech titans puts out a press release, we get a reprise of this same phenomenon, in which a minor bit of progress is portrayed in many media outlets as a revolution.
The central problem, in a word; current AI is narrow; it works for particular tasks that it is programmed for, provided that what it encounters isn’t too different from what it has experienced before. That’s fine for a board game like Go — the rules haven’t changed for 2,500 years — but less promising in most real world situations.
..the real story is how narrow Duplex was. For all the fantastic resources of Google (and its parent company Alphabet), the system that they created was so narrow it could handle just three things: restaurant reservations, hair salon appointments, and the opening hours of a few selected businesses. By the time the demo was publicly released, on Android phones, even the hair salon appointments and opening hour queries were gone. Some of the world’s best minds in AI, using some of the biggest clusters of computers in the world, had produced a special purpose gadget for making nothing but restaurant reservations.
Several years later, all of this still appears to be true– despite all the manifest progress in certain areas, such as speech recognition, language translation, and voice recognition. Deep learning still isn’t any kind of universal solvent. Nor does it have much to do with general intelligence, of the sort we need for open systems. – Rebooting AI
In the PBS Frontline documentary titled The Age of AI, describing the program, Alpha Go stated that the following.
“Deep learning mimics the neural networks of the human brain.”
That is incorrect, yet it is routinely repeated. There is a rough approximation between neural networks and deep learning and neurons and axons, but it is only a good metaphor as a rough outline.
The Short Term Orientation of Deep Learning
The following is a quote on the short-term orientation of Deep Learning.
“What the field really needs is a foundation of traditional computational operations, the kind of stuff that databases and classical AI are built out of: building a list and then excluding elements that belong on another list. But deep learning has been built around avoiding exactly those kinds of computations in the first place. Lists are basic and ubiquitous in computer programs and have been around for over five decades (the first major AI programming language, LISP, was literally built around lists) and yet they are not even part of the fabric of deep learning.
Classical AI techniques, of the sort that were common long before deep learning became popular, are much better at compositionality, and are a useful tool for building cognitive models, but thus far haven’t been nearly as good at deep learning from data, and language is too complex to encode everything you would need strictly by hand.
The truth is that for now the bestselling robot of all time isn’t a driverless car or some primitive version of C-CPO, its Roomba, that vaccum cleaning hockey puck of a modest ambition, with no hands, no feet and remarkably little brain..In 2006, Elon Musk announced plans to build a robotic butler, but so far as we can tell, there hasn’t been much progress toward that goal. Nothing currently available commercially feels like a breakthrough, with the possible exception of the aforementioned recreational drones, which are thrilling (and tremendously useful for film crews).
Deep learning is largely falling into the same trap, lending fresh mathematics (couched in language like “error terms” and “cost functions”) to a perspective on the world that is still largely about optimizing reward, without thinking about what else needs to go into a system to achieve what we have been calling deep understanding. But if the study of neuroscience has taught us anything, it’s that the brain is enormously complex, often described as the most complex system in the known universe, and rightfully so. The average human brain has roughly 86 billion neurons, of hundreds if not thousands of different types; trillions of synapses; and hundreds of distinct proteins within each individual synapse–vast complexity at every level. There are also more than 150 distinctly identifiable brain areas.
Too much of AI thus far has consisted of short term solutions, code that gets a system to work immediately, without a critical layer of engineering guarantees that are often taken for granted in other fields.” – Rebooting AI
The Hype of Deep Learning
People are attracted to the hype of deep learning and then find less to it than they anticipated. This is covered in the following interaction we found on Quora.
Should I quit machine learning? I used to find it exciting before it was cool, but now I find it unexciting and boring. Since deep learning is the future, should anyone with no interest in deep learning quit?
Answer #1
I sympathize heavily with this viewpoint.
Before I started to heavily use neural networks, I was in love with how creative and fascinating some ML algorithms can be. Bags of visual words, the concept of a ‘hyperplane’, edge histograms, Markov-chains, and tons of others. They felt so weird and unusual, but once you mastered the concept, you could truly understand how/why they worked.
But now?
Nearly all of the best-performing algorithms are covered in waves upon waves of nearly incomprehensible math. I heavily doubt that anybody without an extremely rigorous math background could even begin to understand the proofs/mathematical explanations behind the original LSTM paper.
Nobody actually understands why some ‘exotic’ architectures really work. I dare somebody to comment an intuitive explanation for why Inception Modules work well. Nearly every weird architecture is based on ridiculous amounts of trial-and-error that only barely, barely, make sense in retrospect.
Are these two necessarily bad things?
Of course not! Increasing exploration/rigor into material that goes behind human intuition is just the eventual side-effect of a fields expansion, and, if anything, marks the sign of even more exciting developments. Those who study math/physics understand this quite well.
But is ML as exciting anymore?
Personally, not for me. I loved being able to code the authors algorithm entirely from scratch without having to delve into online math lectures, and I loved being able to read a paper and knowing that, if I spent enough time, my feeble human brain would be able to comprehend it fully. Neither of those two things for me, at least for me, are reasonably possible.
But is it worth leaving the field? Nah. ML is rapidly changing, and what you used to love about the field may suddenly come back into fashion. – Abhishaike Mahajan
Answer #2
The deep learning hype is misleading, in that people tend to believe that deep learning is the be-all and end-all of machine learning. Deep learning is solving some important problems, and because deep learning methods just came back into limelight, people are trying to attack all the low-hanging fruit with it, which is giving these methods a lot of attention. But this does not mean that the other ML algorithms have fallen out of favor. Let me draw a comparison between SVM and neural networks.
Now, there are some obvious limitations of NNs compared to SVMs:
Data-hungry: To train NNs, you need massive amounts of data. What do you do when you have very little data? Here is a standard set of benchmark datasets: UCI Machine Learning Repository: Data Sets. Pick any dataset from this set with fewer than 1000 training examples, and try training a NN that beats SVM on that data by a large margin. This is by far the most important point in my opinion.
Huge computational resource requirement: You can’t do much with NNs unless you have GPUs. On the other hand, you can train SVMs on personal machines without GPUs.
CNNs require spatial property: Convolution operation performs an operation on a set of pixels or a sequence of words/audio signals that are close-by. Shuffling the pixels/words/audio signals will change the output of the CNN completely. That is, the order of the features is important, or in other words, convolution is a “spatial” operation. SVMs are unaffected by shuffling of features. So problems which do not have the spatial property will not benefit from CNNs.
Non-trivial parameter optimization: I have already discussed this issue in detail in another answer. For SVMs, you just need to tune 2–3 parameters.
Less interpretable: Many a times, you have little idea about what is going on inside the network, particularly, at layers closer to the output. This again makes them harder to improve, since you don’t know much about what’s going wrong. SVMs may not be completely interpretable either, but they are more interpretable than NNs.
Longer to set-up: Unless you are doing something very similar to ImageNet, you will not find a pretrained model on the web. So you will have to write a significant amount of code to train and evaluate a reasonable NN model, even when you build upon the standard deep learning frameworks. With SVMs, you just download LibSVM, and can start training your models in a few minutes. – Prasoon Goyal
Answer #3
“Deep learning” isn’t a thing. It’s just a buzzword, for people for whom “neural net” would be confusing.
Neural nets were all the rage years ago, but with more limited computing resources, it was hard for them to reach their potential. Now that’s changed, but neural nets are not general relativity, where our understanding of the world has fundamentally altered.
There’s going to be a place for older (not older) unsupervised and supervised learning methods forever, in the same way that people still use t-tests. So long as you don’t treat your shiny new hammer (“deep learning”) as a tool to cut plywood (“machine learning” — actually my metaphor is breaking down), you’ll be wise. – Jim Abraham
The Diminishing Gains from Deep Learning/Neural Networks
New deep learning/neural networks have used more powerful modern computers, combined with the more massive data sets, to bring brute force to important gains in identification-based applications. This is what is less understood from the outside, that deep learning is a brute force approach to identification. Programming is a more efficient approach, but it is human-directed, and therefore not “learning.”
This important distinction between programming and AI is not generally understood. Nearly all of the benefits of computing comes from programming, not AI.
The general explanation for AI is that the techniques are advancing rapidly.
Robotaxis were eminent…..until they weren’t. And most people forgot about his enormous claim and moved on to the next Elon Musk claim.
Elon Musk stated that AI improvements are not linear but exponential (a term is thrown around far too often, as is excellently covered in the article Stop Saying Exponential.
And when did Elon Musk say this?
When he was trying to raise $2.3 billion using his now-defunct (or at least substantially delayed) robotaxi idea, Tesla would either stop selling cars to customers or receive a percentage of the Tesla robotaxis. This fleet of robotaxis would work 24/7, making money for Tesla owners and Tesla day and night. It is curious how AI’s exaggeration seems to coincide with funding rounds or sales presentations to buyers.

With this man’s long-term record of inaccuracy, why is anyone still listening to Elon Musk?
The Reality in the Neural Network and Deep Learning Space
However, what tends to be hidden is that it is increasingly recognized in the research space that the gains from increased investments in deep learning/neural networks are slowing. This is expressed in the following quotation.
Almost everything you hear about artificial intelligence today is thanks to deep learning. This category of algorithms works by using statistics to find patterns in data, and it has proved immensely powerful in mimicking human skills such as our ability to see and hear.
To a very narrow extent, it can even emulate our ability to reason. These capabilities power Google’s search, Facebook’s news feed, and Netflix’s recommendation engine—and are transforming industries like health care and education.
The biggest shift we found was a transition away from knowledge-based systems by the early 2000s. These computer programs are based on the idea that you can use rules to encode all human knowledge. In their place, researchers turned to machine learning—the parent category of algorithms that includes deep learning.
Among the top 100 words mentioned, those related to knowledge-based systems—like “logic,” “constraint,” and “rule”—saw the greatest decline. Those related to machine learning—like “data,” “network,” and “performance”—saw the highest growth.
The reason for this sea change is rather simple. In the ’80s, knowledge-based systems amassed a popular following thanks to the excitement surrounding ambitious projects that were attempting to re-create common sense within machines. But as those projects unfolded, researchers hit a major problem: there were simply too many rules that needed to be encoded for a system to do anything useful. This jacked up costs and significantly slowed ongoing efforts.
Machine learning became an answer to that problem. Instead of requiring people to manually encode hundreds of thousands of rules, this approach programs machines to extract those rules automatically from a pile of data. Just like that, the field abandoned knowledge-based systems and turned to refining machine learning. – MIT Technology Review
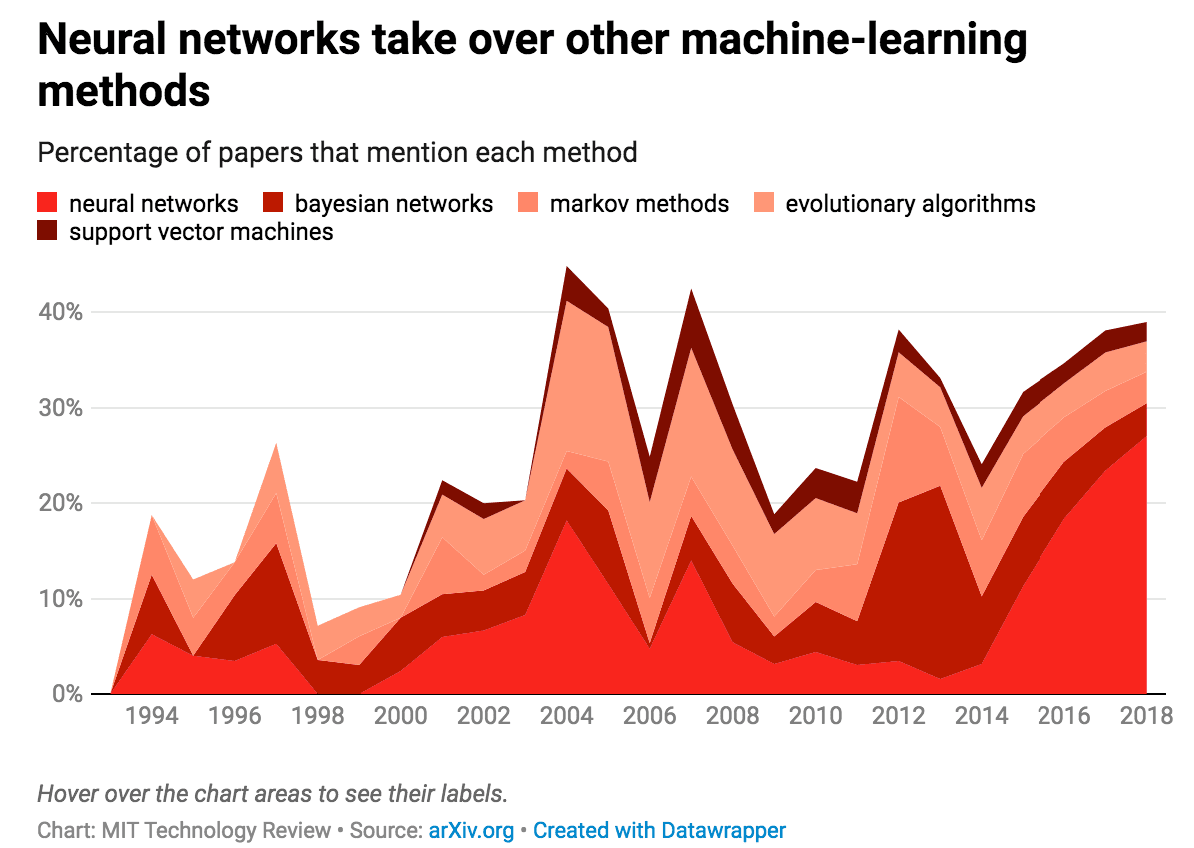
Neural Networks Takeover MIT
Technology Review’s graphic shows the rise of deep learning/neural networks within the rise of machine learning.
Conclusion
Neural networks and deep learning are overestimated in terms of what they can do. They have been handy for natural language processing. However, they see a diminishing marginal utility of the enormous investment made in them as the primary AI technique of the third bubble in AI.