
Why Train Neural Networks When One Can Perform Preset Programming?
Executive Summary
- There is an enormous amount of energy and resources being invested in neural networks and deep learning.
- This technique requires enormous training data sets. However, this should be compared against programming methods.

Introduction
Unless the problem to be solved by a neural network is very simple, the amount of data required to train it is considerable. This is because neural networks are brute force. This is currently accepted as a good method for answering questions and solving problems, but it is extremely wasteful. This waste is so high that it limits scalability and helps explain why AI companies seem to require unlimited computing resources while delivering small returns, both in terms of answer quality and the profitability of the AI companies themselves.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
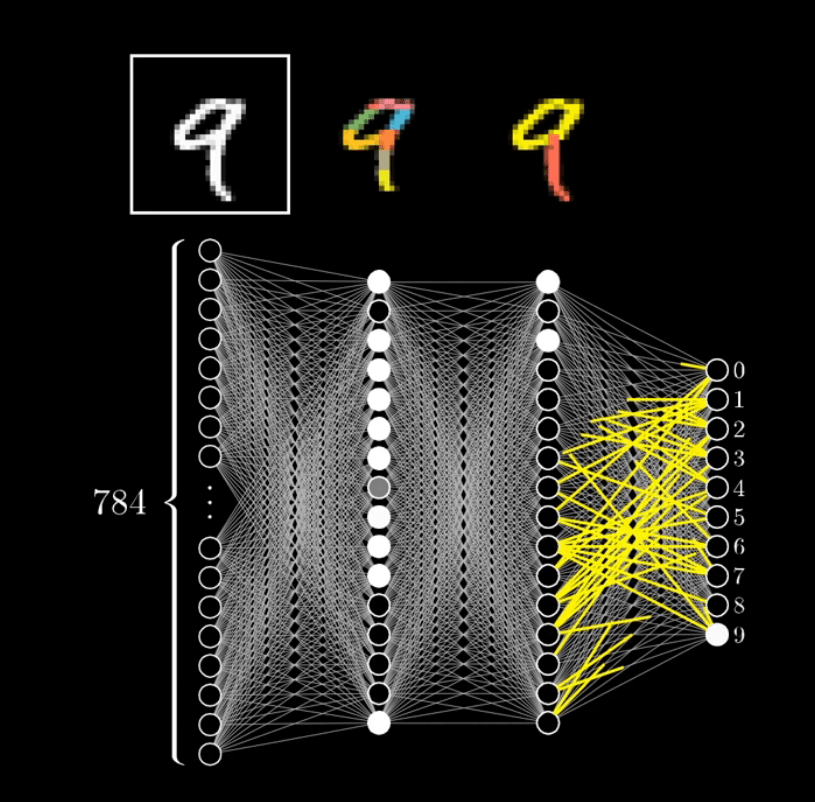
In this neural network, the video What is a Neural Network by 3Blue1Brown has 784 neurons or nodes. It requires this many nodes to identify or categorize random numbers into the ten numbers seen to the right.
Are Neural Networks….Neural?
Neural networks use the construct of a network of neurons, but neurons don’t function as neural networks do; neural networks are far simpler methods of “intelligence.” Neural networks were coined in 1944, when we knew very little about how neurons worked. The only real metaphor connecting the two is that both neurons and nodes are connected to other neurons and nodes. However, neurons don’t just transfer information to each other. There are complex chemical processes between neurons that are not captured in simply connecting a series of nodes representing weights.
How Neurons Work is Very Different from Neural Networks
This is explained in the following quotation.
Deep learning is, in fact, a new name for an approach to artificial intelligence called neural networks, which have been going in and out of fashion for more than 70 years. Neural networks were first proposed in 1944 by Warren McCullough and Walter Pitts, two University of Chicago researchers who moved to MIT in 1952 as founding members of what’s sometimes called the first cognitive science department. – MIT Technology Review
Neural networks are also very different from how human neurons work: they are narrow and perform only specific tasks. Human and animal brains have specialized regions that perform different functions, but the metaphor is not direct to neural networks.

Rise of the Giant Interconnected Tic Tac Toe Boards
A more accurate way to think of neural networks is that they are a gigantic tic-tac-toe board, but with many cells. The more difficult the problem and the more inputs that must be evaluated, the more necessary cells. The arrangement of, say, 750 cells on the tic-tac-toe board, one way identifies the number 9, and another way identifies 8. A most accurate depiction would be a series of tic-tac-toe boards that feed into each other, with more options or cells eliminated as the program progresses through various stages. The first tic-tac-toe board is called the input layer, and the last, after identification, is the output layer.
Deep Learning Versus Neural Network
The differentiator between deep learning and the term “neural network” is that deep learning uses many of these tic-tac-toe boards, whereas a neural network uses fewer.
However, deep learning is a subcategory of a neural network.
AI Learning as Fake/Simulated Learning
“Learning,” if that is the right word, is accomplished by adjusting the weights between the nodes. This essentially increases the weights of the input nodes that are most impactful in leading to the next layer or the tic-tac-toe board. And because of dependencies, not all nodes in the prior connected layer are connected to all the nodes in the following connected layer. In this way, they are very similar to human and animal neurons, and like neurons, they have stronger connections to some neurons to which they are connected. And human neurons have an impossibly large number of connections to other neurons, which is not effectively illustrated with graphical representations, as covered in the following quotation.
Estimates for the number of neurons and synapses in a human brain vary widely, but there are approximately 10^11 neurons in the human brain and between 10^14 and 10^15 synapses. – Brilliant
The Neurons of Worms
However, some elementary animals have very few neurons but can still perform impressive feats. The tiny nematode, or roundworm, has only 302 neurons.
Why Use Neural Networks?
The following expresses a core issue about neural networks.
But intellectually, there’s something unsatisfying about neural nets. Enough training may revise a network’s settings to the point that it can usefully classify data, but what do those settings mean?
What image features is an object recognizer looking at, and how does it piece them together into the distinctive visual signatures of cars, houses, and coffee cups? Looking at the weights of individual connections won’t answer that question.
This is core the fraudulent claims regarding large language models.
In recent years, computer scientists have begun to come up with ingenious methods for deducing the analytic strategies adopted by neural nets. But in the 1980s, the networks’ strategies were indecipherable. So around the turn of the century, neural networks were supplanted by support vector machines (see further on in this article for coverage of support vectors), an alternative approach to machine learning that’s based on some very clean and elegant mathematics. – MIT Technology Review
Why not just program what we know to be a nine versus an eight?
Many companies are using neural networks to create responsive programs; however, instead of feeding massive amounts of data to an NN. I already know, for instance, the difference between a cat and a dog.
Why not just put, say, this in instead?
If a Triangular Face, and if eyes are > 25% of face, and if whiskers stick out >.13 from the face, then “Cat,” If No, then “Dog.”
Let us review the Wikipedia description of neural networks.
For example, in image recognition, they might learn to identify images that contain cats by analyzing example images that have been manually labeled as “cat” or “no cat” and using the results to identify cats in other images. They do this without any prior knowledge of cats, for example, that they have fur, tails, whiskers and cat-like faces. Instead, they automatically generate identifying characteristics from the examples that they process.
So the first question that should arise is: why train a system with no prior knowledge of cats or dogs when we already have this knowledge?
The Work Involved in Training Neural Networks
The work involved with training neural networks is explained as follows.
Deep learning is greedy. In order to set all the connections in a neural net correctly, deep learning often requires a massive amount of data. AlphaGo required 30 million games to reach superhuman performance, far more games than any one human would ever play in a lifetime. With smaller amounts of data, deep learning often performs poorly. Its forte is working with millions or billions of data points, gradually landing on a set of neural network weights that will capture the relations between those examples.(emphasis added) I
f a deep learning system is given only a handful of examples, the results are rarely robust. And of course much of what we do as humans we learn in just a few moments; the first time you are handed a pair of 3-D glasses you can probably put them on and infer roughly what is going on without having to try them on a hundred thousand times. Deep learning simply isn’t built for this kind of rapid learning.” – Rebooting AI
The following is recent work described by Markian Jaworksy, an analyst using neural networks to train this data-driven approach.
I have spent the past 3 weeks, recreating my NN/DL code on a new laptop to detect electricity transformers on power poles from images downloaded from Google street view. So many conflicts in python versions, TensorFlow versions, Keras versions and ultimately the library I wanted to get working “innvestigate” to get more insight into the NN/DL. I had to downgrade from python 3.7 to 3.6 to get my Tensorflow code working again. NN/DL has two ways of making predictions, linear regression and logistic regression. Linear regression is a numerical prediction based on a linear relationship of numbers, logistic regression is what is used for facial/image recognition. You have a series of photos and label them. You let the NN/DL do the work, you don’t interfere with that type of logic. What is in your control is the size of the photos you use for your train set, and your test set. You then can manipulate the images in both to focus on objects in the foreground or background, top or bottom of the images (to reduce the number of pixels), and then you can choose how many pixels in each layer of the NN/DL and how many layers. You ultimately are limited by the capacity of your computer CPU and memory and have to choose accordingly. If you push too hard, your computer has a nasty crash. NN/DL retrospectively looks at its own predictions and determines how it must adjust its own network to best come up with the correct answers. The coder sets the parameters and provides the resources.
When I asked Markian about neural network training versus preset programming, he replied with the following quotation.
That’s the difference between machine learning and deep learning. Good examples of machine learning are support vectors, where you draw boundaries and make one time assessments on those boundaries. In fact, an ex-soviet professor was lured to the USA upon the collapse of the USSR to teach support vectors and create the first text (handwriting) to digital capture.
This video covers support vectors. Support vectors refine and reduce the search space by giving the ML algorithm restrictive rules.
However, this is different than specific programming, which I listed above.
The work involved in training neural networks leads to particular applications.
In the end, deep learning just isn’t that deep. It is important to recognize that, in the term deep learning, the word “deep” refers to the number of layers in a neural network and nothing more. “Deep” in that context, doesn’t mean that the system has learned anything particularly conceptually rich about the data that it has seen. At best, deep learning is a kind of idiot savant, with miraculous perceptual abilities, but with very little overall comprehension. It’s easy to find effective deep learning systems for labelling pictures–Google, Microsoft, Amazon, and IBM among others, all offer commercial systems that do this, and Google’s neural network software library TensorFlow allows any computer science student the chance to do it for free. It’s also easy to find effective deep learning systems for speech recognition, again more of less a commodity at this point. But speech recognition and object recognition aren’t’ intelligence, they are just slices of intelligence. For real intelligence, you also need reasoning, language and analogy, none of which is nearly so well handled by current technology.
We don’t yet, for example, have AI systems that can reliably understand legal contracts, because pattern classification on its own isn’t good enough. To understand a legal contract you need to be able to reason about what is and isn’t said, how various clauses relate to previously established law, and so forth; deep learning doesn’t do any of that. Even reliably summarizing plots of old movies for Netflix would be too much to ask.” – Rebooting AI
Machine Identification
Clearly, one advantage of not programming the identification routine is that it can continue to adjust the weights of the connections between the nodes. However, in the case of dogs and cats, there is no reason to do this because they are not changing. Neural networks can be adaptive to new conditions.
This advantage is explained in the following example.
Once the model was trained, the researchers tested it on the Broad Institute’s Drug Repurposing Hub, a library of about 6,000 compounds. The model picked out one molecule that was predicted to have strong antibacterial activity and had a chemical structure different from any existing antibiotics. Using a different machine-learning model, the researchers also showed that this molecule would likely have low toxicity to human cells.
In this case, the researchers designed their model to look for chemical features that make molecules effective at killing E. coli. To do so, they trained the model on about 2,500 molecules, including about 1,700 FDA-approved drugs and a set of 800 natural products with diverse structures and a wide range of bioactivities.
“We’re facing a growing crisis around antibiotic resistance, and this situation is being generated by both an increasing number of pathogens becoming resistant to existing antibiotics, and an anemic pipeline in the biotech and pharmaceutical industries for new antibiotics,” Collins says. – MIT Technology Review
Well, this is not really an AI problem; it’s a human intelligence problem of overusing antibiotics. Will our expectation of future AI be to solve problems we should have figured out many decades before they became critical?
A second advantage is that the neural network can gain insights that the designers do not know in advance. However, if this isn’t what is being done and the insights are known beforehand, it’s not easy to see how neural networks are the best path to a solution.
Secondly, the neural network weights never tell the designer “why” a relationship was found — it can’t. It can only find a relationship. And it also cannot tell spurious relationships from real relationships.
To see the full screen, select the lower right-hand corner and expand. Trust us, expanding makes the experience a whole lot more fun
The Overextension of AI
One can check and validate the exaggeration of a new technology’s benefits when one begins to notice regressions to earlier methods that existed before the new technology was developed and proposed. The following quote can be found in the article Premium: The Hater’s Guide To The SaaSpocalypse.
A good example is Salesforce’s Agentforce chatbot. While Salesforce layers on agonizing levels of intrigue, Agentforce is really a series of chatbots connected to knowledge depositories with triggers that tell it to do stuff in certain situations, such as if a customer wants a refund. After claiming that the AI wave would be “bigger than anyone has ever seen” in 2023 and declaring a “hard pivot to autonomous agents” in September 2024, The Information reported in December 2025 that Salesforce would pivot away from using Large Language Models because Agentforce works better when they don’t use them:
More recently, though, Salesforce executives have delivered a different message to customers: Agentforce sometimes works better when it doesn’t rely so much on LLMs, otherwise known as generative AI. Salesforce has been using rudimentary, “deterministic” forms of automation in Agentforce to improve the software’s reliability, said Sanjna Parulekar, senior vice president of product marketing. This means it makes decisions based on predefined instructions as opposed to the reasoning and interpretation AI models use.
That is right. Because in the vast majority of cases, a completely original solution or idea is not necessary. In the overwhelming majority of cases, the requirement is to apply the correct pre-known option or solution to a problem. That is, to apply existing knowledge flexibly to the problem at hand. In this case, the problem-to-solution assignment is a far more efficient and lower-error method of solving the problem.
Conclusion
Neural networks/deep learning are being invested in more heavily and used more widely every year.
This article raises the question of whether they are being overused when the parameters are already known — and all that the training data sets do is bring the neural network up to what we already know.
And further, we question whether it makes more sense to program rules into the software to accomplish the same task rather than use neural networks.
Yet, if you want to raise money or otherwise secure funding for a project, you can get support far more easily if you say you will train a neural network to accomplish a task, rather than if you state that you will program software to accomplish the same task.
This places the method used on a higher plane than the objective when evaluating funding. That inherently does not make any sense.