
How an SAP HANA Sidecar Becomes a High Overhead Item
Executive Summary
- SAP created a concept of an SAP HANA sidecar designed to get customers to implement uncompetitive or immature solutions.
- The benefit of the free SAP HANA sidecar is one example of this.

Introduction
The SAP HANA sidecar was presented as an essential step to using HANA very aggressively in 2013 and less so since that time. You will learn SAP’s logic behind a sidecar and whether the logic actually holds up.
Our References for This Article
If you want to see our references for this article and related Brightwork articles, see this link.
Notice of Lack of Financial Bias: We have no financial ties to SAP or any other entity mentioned in this article.
- This is published by a research entity, not some lowbrow entity that is part of the SAP ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on SAP is provided by SAP, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, SAP pays off all IT analysts -- who have the same concern for accuracy as SAP. Not one of these entities will disclose their pro-SAP financial bias to their readers.
What is an SAP HANA Sidecar?
An SAP HANA sidecar is where HANA is run as an offline system. The offline nature of the SAP HANA sidecar is critical to understanding the overall concept, as the idea is that HANA is first tested offline before being brought online.
Here, you can see a standard graphic that shows a HANA sidecar design.
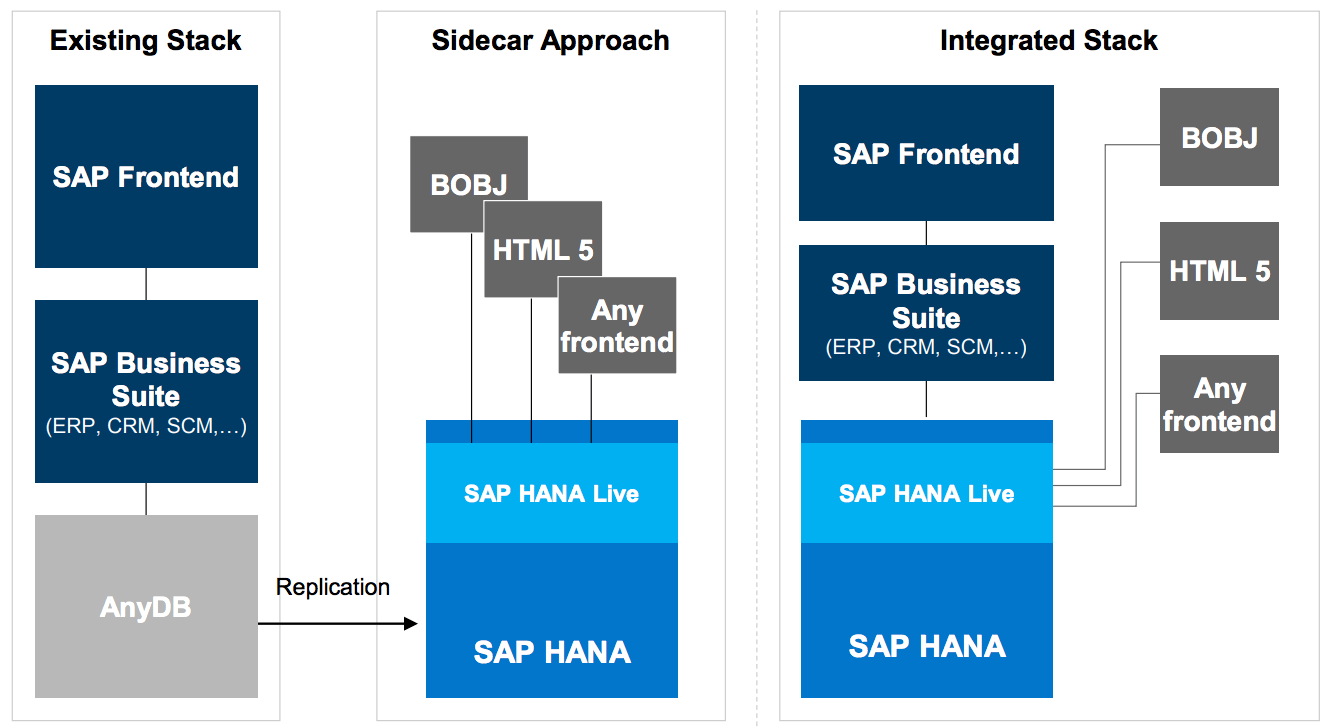
Using the “sidecar,” the data is replicated to HANA. This is a precursor to replacing the current database, called AnyDB, to reflect it being Oracle or IBM, etc.. with HANA.
This database is being replaced in the first place is an exciting question as Oracle, HANA, and MS are continually updating their databases. And SAP has no evidence that HANA outperforms other databases, even in analytics. As we cover in the article What is HANA’s Actual Performance and Articles that Exaggerate HANA’s Benefits. However, SAP continues to use false compatibility claims to push customers to HANA. They do this even when there is no evidence for HANA outperforming the database it is replacing.
Here is a typical quotation from SAP on this topic that tries to ease companies into moving toward HANA without evidence that moving to HANA makes sense.
“Customers can add new analytics capabilities immediately without disruption to their existing landscape. Any investment today will be valid for SAP Business Suite powered by SAP HANA.”
The logic often presented by SAP is that if SAP offers an item, it naturally should move to.
Benefits of the SAP HANA Sidecar?
And here is another promoting the benefits of this design.
“The way the current SAP systems work is, the data is transferred from database to application layer and calculations are performed in application layer. Here you have significant latency between disk to memory transfer and then calculations in application layer. HANA database on the other hand is optimized for mass parallel processing and performs calculations in the database layer and only submits a result set to the application.” – HANA Discussion Thread
There are several essential questions to ask regarding this comment.
- Is This True?: This idea of using a stored procedure for processing has been proposed for quite some time. However, SAP promotes this concept to reduce their applications’ compatibility with other database vendors, which are databases other than HANA.
- Superior Performance?: As explained in the article, What is the Actual Performance of HANA?, there is no evidence that HANA outperforms other comparable databases. The evidence appears to point in the opposite direction. And these comparable databases can achieve this performance without stored procedures.
What is the Overhead of the SAP HANA Sidecar?
One of the greatly underemphasized points is that this data replication between the active system and the sidecar is quite a bit of overhead. This is, of course, minimized by those who propose using the SAP HANA sidecar. To explain this overhead, we will review the requirements of the sidecar.
Here are a few requirements to achieve data replication for a HANA sidecar.
- “Data must be loaded from the current database to the HANA database using any existing replication scenarios (DXC, Data Services, SLT) or ABAP custom code.
- If you require real-time loading into the HANA sidecar, you will still need SLT or have custom code that loads to HANA via a secondary database connection every time a change is triggered.
- Custom ABAP programs are needed to connect to the HANA database and retrieve/insert/update data.
- To fully optimize the performance of HANA as a sidecar, all custom ABAP code must be optimized to run SQL SCRIPT to fully utilize the HANA calculation (refer to part_2 blog for more details)
- HANA only runs on SUSE LINUX SP11, so if your current hardware/os does not include SUSE LINUX, you will need to get hardware specifically for HANA” – HANA Discussion Thread
The Project Duration of HANA as a Sidecar
A typical HANA implementation will finally take one year and 1.5 years to migrate. This means the customer must run the sidecar during this period and absorb the cost. This is a longer duration than is pitched by SAP account executives, which is one reason why HANA’s TCO is so high.
Conclusion
SAP sidecars can be viewed as a sales strategy to push immature applications into prospects and customers by taking the solution “offline.” The idea being presented by SAP is that the sidecar allows the customer to incorporate “innovation” into companies. However, the overall presentation is a problem. One major reason is that the buyer begins investing from when they buy the sidecar software, which can easily lead to “sunk cost” decision-making where the customer continues to invest in a solution. That is, the sidecar can very easily become “project quicksand.” And this is, of course, the objective of those that present sidecars.