
How Accurate Was John Appleby on SAP BW-EML Benchmark?
Executive Summary
- John Appleby made bold predictions on HANA.
- We review how accurate he was in his article on BW-EWL Benchmark.

Video Introduction: How Accurate Was John Appleby on SAP BW-EML Benchmark?
Text Introduction (Skip if You Watched the Video)
John Appleby’s article on the SAP HANA blog was titled Behind the SAP BW EML Benchmark and was published on March 19, 2015. To some readers, this article may appear harsh in its judgment of John Appleby. However, by the time we evaluated this article, we have read probably 20 articles from John Appleby. We have noticed concerning patterns that are now very easy for us to pick up on. This is why we refer to previous articles from John Appleby, where he used very similar or identical tricks. You will read our analysis of the accuracy of what John Appleby said about the SAP BW EML benchmark.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Notice of Lack of Financial Bias: We have no financial ties to SAP or any other entity mentioned in this article.
- This is published by a research entity, not some lowbrow entity that is part of the SAP ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on SAP is provided by SAP, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, SAP pays off all IT analysts -- who have the same concern for accuracy as SAP. Not one of these entities will disclose their pro-SAP financial bias to their readers.
The Quotations
The Lenovo BW-EML Benchmark?
“Yesterday, Lenovo released a new record for the SAP BW-EML Benchmark and I thought that some might be interested in the purpose, history and details behind the benchmark.
The SAP HANA platform was designed to be a data platform on which to build the business applications of the future. One of the interesting impacts of this is that the benchmarks of the past (e.g. Sales/Distribution) were not the right metric by which to measure SAP HANA.
As a result, in 2012, SAP went ahead and created a new benchmark, the BW Enhanced Mixed Workload, or BW-EML for short.
Appleby stated something very odd about this benchmark in his comment in the article, which we covered in How Accurate Was Appleby on HANA Working Fast for OLTP?
Appleby stated the following in the comment section.
“I’ve not run the benchmark but I believe it’s because:
1) SD doesn’t run well on HANA
2) SD doesn’t accurately represent how customers actually use systems in 2014
3) HANA does run well for how customers really use systems in 2014
SAP are in the process of creating a new benchmark which I understand will include mixed-workload OLTAP queries.
The BW-EML benchmark was designed to take into account the changing direction of data warehouses – a move towards more real-time data, and ad-hoc reporting capabilities.”
This is why this new benchmark has been introduced. Because HANA cannot compete on the previous benchmark, there is also zero evidence that SD has changed. So this is a made up topic by Appleby.
This is what SAP previously stated about its benchmarking.
“Since then the SAP Standard Application Benchmarks have become some of the most important benchmarks in the industry. Especially the SAP SD standard application benchmark2 can be named as an example. The goal of the SAP Standard Application Benchmarks is to represent SAP business applications as realistic as possible. A close to real life workload is one of the key elements of SAP benchmarks. The performance of SAP components and business scenarios is assessed by the benchmarks and at the same time input for the sizing procedures is generated. Performance in SAP Standard Application Benchmarks is determined by throughput numbers and system response times. The throughput numbers are defined in business application terms. For the SAP SD benchmark, this would be for example fully processed order line items per hour. The unit for the measurement of CPU power is SAP Application Performance Standard (SAPS)3 . SAPS is a hardware independent measurement unit for the processing power of any system configuration. 100 SAPS is defined as 2,000 fully processed order lines items per hour which equals 2,000 postings or 2,400 SAP transactions.” – SAP, BW-EML SAP Standard Application Benchmark
So it seemed SAP was quite satisfied with its SD application benchmark2….that That is until they came up with HANA.
As we will see, SAP has yet to benchmark S/4HANA SD even up to 2019.
How Does the SAP BW-EML Benchmark Work?
“BW-EML is quite a straightforward benchmark, and quite elegant in some ways. It was designed to meet with the Data Warehousing requirements of customers in 2012, and there were two key goals:
1 – A focus on near-real-time reporting, with the capability to update data every 5 minutes in key reporting areas.
2 – Ad-hoc reporting requirements, with the ability to ask a question on any data slice without having the define aggregation levels in advance.
The SAP BW-EML Benchmark looked to achieve these goals with the following constructs:
1 – A scale-factor with the total number of rows (500m,1bn, 2bn or more). The 500m scale-factor is 600GB of generated flat files.
2 – A common data model is used with 7 years of DSO and 3 years of InfoCube, each representing 10% of the scale factor.
3 – 8 Web Reports are used (4 on the DSO MultiProvider and 4 on the InfoCube MultiProvider), running queries that are randomized both by characteristic and filter value and drill-down.
4 – Data Loads are run every 5 minutes during the run, loading and additional 0.1% of the total data volume over 60 minutes (1m for the 1bn scale-factor, or 100k rows per object).
5 – A benchmark driver logs in a large number of users (typically ~100) and runs reports for a 60 minute interval called the “high load” period.
The benchmark result is the total number of query navigations run over 60 minutes. What’s nice about BW-EML is that whilst the queries are random, they are chosen with groups of cardinality, so the variance in runtime has been shown to be <1%.”
This is interesting.
Let us see what Oracle has to say about the BW-EML.
“Oracle in conjunction with our hardware partners has published over 250 SAP standard application benchmarks in the last 20+ years and has always been able to gain SAP certification in a very rapid and problem-free process.
SAP is now promoting HANA as the database of choice for their applications and clearly has a conflict of interest when it comes to certifying benchmark results that show better performance than HANA. Of the 28 SAP standard application benchmarks, SAP has chosen to only publish results for HANA on the BW-EML benchmark (emphasis added).
Curiously, they have only certified one non-SAP database result for BW-EML benchmark, which was an uncompetitive result published by IBM on DB2 for the I-series platform.
Unfortunately, SAP won’t allow such a head-to-head comparison to be made to HANA because SAP has not published a single benchmark result for any of its transaction processing applications running on HANA. Why not? Customers should ask SAP: What are you trying to hide?
SAP formulated a new benchmark, BW-EML, in 2012 to evaluate the performance of databases running its Business Warehouse (BW) analytics application. The benchmark is intended to measure typical demands made on the SAP Business Warehouse database from users generating real-time reports and ad hoc queries.
This is the only SAP standard application benchmark for which SAP publishes results with HANA. And the results of Oracle’s recent BW-EML benchmark demonstrate that Oracle Database 12c In-Memory runs this benchmark twice as fast as HANA does.”
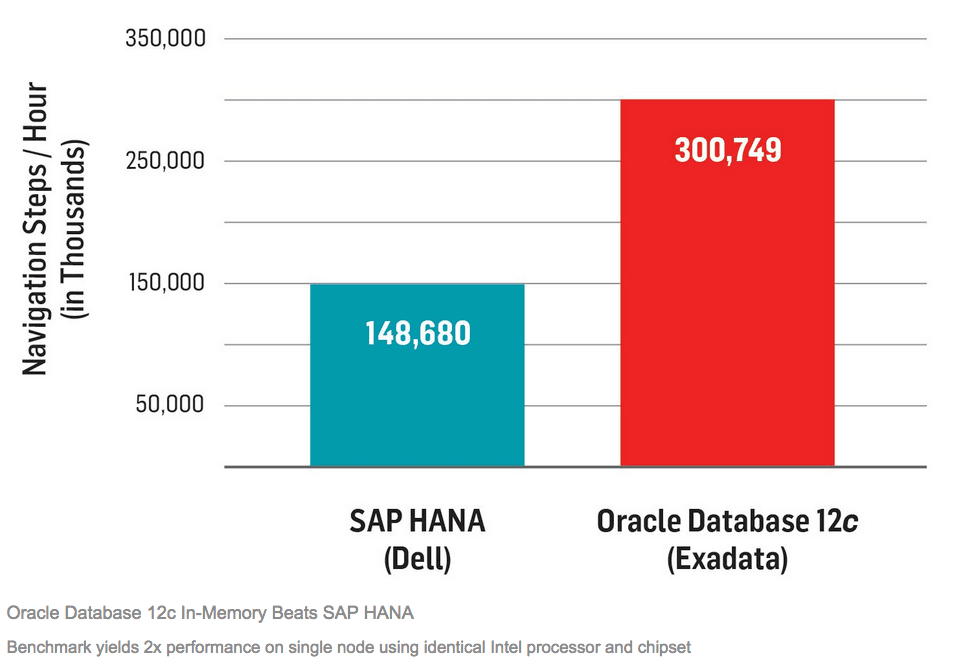
This graphic from Oracle is problematic for us. HANA is sitting on Dell, but Oracle is sitting on Exadata, a costly engineered system. And most Oracle databases do not use Exadata. Therefore the performance difference could be attributed in part to the hardware difference. There is no denying this; Oracle promotes Exadata as far more performant than any other Oracle hardware.
The question we have is, why didn’t Oracle place Oracle on the same Dell hardware that HANA used during the benchmark?
This question is brought up by SAP.
“FUD factor #3: An Oracle Exadata Database machine is much more expensive than a commodity Dell or Lenovo server that databases often run on.”
And Oracle’s answer is the following.
““Sure, it is,” Colgan says. But for many enterprise workloads, the performance advantages provided by Oracle Exadata machines—optimized hardware-software systems preconfigured with compute, storage, and networking hardware—more than make up for the difference.”
This answer appears to be a pivot. It does not seem to address the core issue: Exadata machines are undoubtedly responsible for part of the performance difference between HANA and Oracle. The intent of the benchmark should be to keep hardware independent from the software.
SAP further elaborates on a topic which we agree with SAP.
“Oracle’s claims are based on nonequivalent systems. From a hardware perspective, the SAP HANA platform runs on well-priced hardware from 12 partners, including Dell and Lenovo. The Oracle product runs on expensive proprietary servers that make customers dependent on Oracle. On the software side, Oracle compares the speed of a one-node setup on a current Exadata server against a one-node Dell server benchmarked in October 2014. A fair comparison would be one in which the Dell server ran the same newer SAP software that was used on the Oracle Exadata machine. We do not want to speculate on the potential performance improvement if the Dell benchmark ran on the same version of the SAP NetWeaver technology platform as the Oracle benchmark. Yet the Exadata machine costs 20 to 30 times more than the Dell server and yields just 2 times the performance. Does it make sense to pay that kind of premium for little improvement in database performance?”
We cannot verify SAP’s statement about the cost differential between Exadata and Dell. It is most likely exaggerated, but Exadata is undoubtedly significantly more expensive. The primary point is that Exadata is higher performing hardware than the Dell hardware used for HANA.
- The essential point is that Oracle did not isolate the effect of the hardware from the software’s effect, which is the most elementary rule around testing.
- Oracle used Exadata to get the highest possible score rather than trying to produce a comparable test.
- HANA uses extremely wasteful hardware setups and has a problem addressing the memory in their hardware configurations. We covered in the article How HANA Takes 30 to 40 Times the Memory of Other Databases. Therefore the Dell server would have been quite expensive. The idea that the price goes up from there for Exadata is quite mind-boggling.
SAP’s Missing Benchmarks
Where are the rest of the benchmarks, the other 28?
Where did they go?
Are they now all obsolete because HANA performs so poorly on them? Appleby makes it appear as if publishing the BW-EML benchmark is a great accomplishment. But as is typical with Appleby, he deceives readers by leaving out all the information that provides the full picture. As the Oracle database has similar “in memory” functionality, it is quite odd that SAP’s won’t compete against a database that it repeatedly calls out as “legacy.”
According to SAP, HANA should easily beat Oracle in an open competition, yet it dodges any competition. Why would SAP do this unless everything that SAP says about HANA’s performance is false?
What is a Permissible in the Benchmark?
Now we go back to Appleby for another quote.
“Anything which a customer might do is permissible, which includes any supported configuration and platform. This includes indexes, aggregates, and any other performance constructs. Anything that a customer can do is fair game.
There are pros and cons to this, but it drives a behavior of irrational optimization in many benchmarks. CPU manufacturers have been known to tune microprocessors to run SPEC benchmarks faster. Database vendors create parameters to turn off important functionality, to gain a few extra points in TPC-C.
One thing that surprised me on the SAP HANA database is that the configuration used by published results is basically the stock installation. What’s more, there are no performance constructs like additional indexes or aggregates in use.
From a benchmarking perspective that’s insignificant (benchmarkers routinely spend months tuning a database), but it is hugely significant from a customer DBA and TCO perspective.”
That is extremely odd because, in real life implementations, HANA is a very high overhead database.
Appleby is proposing an out of the box scenario, which is very commonly how salespeople speak. We have participated in several SAP sales initiatives where the term “out of the box” some similar oversimplifying term was used. And we can’t recall a single time where this ends up being true when the time to implement came, as we covered in the article The Myth of ERP Being 90% Out of the Box.
BW-EML Scale Factor
“Getting back to the benchmark, the Scale Factor is an important point of note. BW-EML is like TPC-H, and runs at a factor. The minimum factor is 500m (50m per object), and this grows to 1bn (100m per object), 2bn (200m per object) and beyond.
Caution: benchmark results with different Scale Factors cannot be compared! From a SAP HANA perspective, they can be compared, because HANA performs linearly with respect to data volumes. Therefore you can safely assume that if you get 200k navigational steps with 1bn scale factor, you will get ~100k steps with the 2bn scale factor.
But you cannot apply this logic with other databases, because you cannot assume linearity of performance. For instance there is an IBM i-Series result at 500m scale factor, and a SAP HANA result at 1bn scale factor. These results are not directly comparable – who knows whether i-Series will be linear.”
Again appears to be more filler designed to impress the reader.
Lenovo World Record
“Today, Lenovo released a world record in BW-EML with > 1.5m navigational steps per hour for the 1bn scale factor. That’s an incredible 417 sustained queries/second benchmarked over an hour.
Even more impressive is that it beats the previous highest single-node result by >10x, despite only having 7x the hardware. The remainder of the improvement comes from innovations in BW 7.4 SPS09 and SAP HANA SPS09, which is equally impressive.
It’s worth noting that the larger scale-factors have not yet been run for BW-EML. For instance, many of my customers have typical DSOs of 1bn+ rows each, which means a scale-factor of 10bn would provide very interesting results. The capability to do 150k navigation steps per hour on a large-scale data warehouse would be deeply impressive.”
And how does this compare to other databases?
Appleby seems to be content describing how HANA performs for the BW-EML benchmark without considering any other database. This seems to change the definition of what a “benchmark” is.
Hardware Cost
“Some benchmarks (e.g. TPC-H) require the hardware cost to be listed as part of the benchmark submission. That’s a pretty important metric, but not one which BW-EML requires.
A rule of thumb for BW on HANA hardware is $100k/TB is a good target price. For other databases, the hardware price will no doubt vary significantly.”
This is not helpful in any way that we can see. This describes the price of HANA hardware, which the only important factor is that comparable hardware was used…..but again, not if the benchmark is rigged in the first place.
Benchmarks Continually Fall Out of Date?
“The fascinating thing about benchmarking is that they become out of date as technology and business needs change.”
There is no evidence presented for this. It is certainly possible, but then why is SAP still using the same SD benchmarks for other databases? Again, Appleby and SAP are looking for a cover or excuse to change the benchmarks.
If SAP were operating in good faith, they would release the previous benchmarks and any new benchmark. If HANA is as world-beating as SAP says that it is, SAP should have no problem beating any database on any benchmark – old or new. Let us recall that is the claim — every other database is legacy compared to the amazing feats capable with HANA.
There is a Clear Move Towards OLTAP Databases?
“In the market right now there is a clear move towards hybrid-workload or OLTAP systems in the Enterprise, which combine transactional processing and analytic processing. This represents a challenge though because SAP’s strategy for this is HANA-only, and there are two orthogonal goals to benchmarking.
The first is to size systems. Given that the future of SAP Business Applications is on S/4HANA, I expect that there will be a S/4HANA S4-2tier benchmark, like the SD-2tier that came before it. This will allow customers to use the SAP QuickSizer to estimate the size of SAP HANA required. Let’s call it a unit of S4PS, which will relate to on-premise deployments and cloud deployments. In all likelihood it will be mixed-workload with analytics and core transactions, driven by the SAP Gateway API layer.”
This is not a “clear move to combined transactional and analytic processing.” SAP, followed by IBM, Oracle, and Microsoft (following SAP’s lead), added column-oriented/”in-memory” capabilities to their databases, but there is no evidence that this type’s processing increased. This is because the applications above them stayed roughly similar. ERP systems are still primarily processing transactions. Companies have not removed their data warehouses and increased reporting off of the ERP system. S/4HANA, even in 2019, is barely live anywhere, with most of the implementation go lives falsified or covered up as we covered in the article S/4HANA Implementation Study. Therefore extremely few customers anywhere are even using S/4HANA on HANA.
Appleby wants his proposal to be true because his income comes from promoting combined transactional and analytic processing. But he presents no evidence that it is true, and of course, he has a massive financial bias to misrepresent reality.
We also question whether the future of SAP is HANA. In 2019 it is apparent that SAP has been nowhere near as successful as SAP intended and that it is very likely that SAP will have to reverse course and certify S/4HANA on Oracle and IBM as we covered in the article, Why SAP Will Have to Backtrack on S/4HANA on HANA.
SD Benchmarks
SAP has produced benchmarks for HANA on transaction processing — but not for S/4HANA.
Notice these SD benchmarks.
These benchmarks are for ECC SD on HANA for different hardware, not a single S/4HANA SD benchmark. Why? S/4HANA is supposed to be what SAP is pushing customers towards — so how is this objective served by publishing benchmarks for S/4HANA?
Well, as pointed out in the earlier comment from Appleby, S/4HANA SD does likely not perform well in this benchmark, so of course, SAP excludes it.
But why would S/4HANA SD perform worse than ECC SD? Well, S/4HANA is far less mature than ECC.
This is circumstantial evidence that supports the issues of immaturity with S/4HANA. This is the primary reason S/4HANA has had such a high failure rate, almost a complete failure rate actually, a subject that we have covered in detail in previous articles such as How Accurate Was SAP on S/4HANA Being Complete?
Why is BW-EML is the Last Cross-Database Benchmark?
“The second is to perform cross-vendor bake-offs, either for hardware or for the database layer. Customers really want to benchmark HANA against other databases, or even to know what HANA appliance is faster. It seems likely that given the future of SAP applications is HANA-only, that the BW-EML benchmark will be the last cross-vendor benchmark.”
Appleby should say “the first, and the last,” or perhaps the term “only” might apply.
SAP thinks so little of its customers that it is hiding its benchmarks from them, unable to prove HANA is superior to any of the competing databases. This is a bit like a gunfighter claiming to be the fastest gun in the West, who refuses to leave his room for the next three weeks.
Notice SAP’s declaration around its benchmarks.
“To help the market easily and quickly make these judgments, SAP offers standard application benchmarks. When used consistently, these benchmarks provide impartial, measurement-based ratings of standard SAP applications in different configurations with regard to operating system, database, or hardware, for example. Decision makers trust these benchmarks to provide unbiased information about product performance.”
It is impossible to read this, having analyzed the rest of the material thus far, and not be amused. How exactly is SAP impartial with benchmarking if they benefit from rigging the benchmark against all other database vendors?
If decision makers trust these benchmarks to “provide unbiased information,” those decision makers are fools.
Final Words
“The BW-EML benchmark isn’t perfect. It doesn’t have enough a result submissions, especially at scale (I hope the incredible Lenovo result will cause other vendors to submit). It’s also really quite hard to run and requires both benchmarking and SAP BW expertise.
There are also not any certified BW-EML benchmark results by Oracle, IBM DB2 BLU or Microsoft SQL Server. One might assume this is because they can’t get good results, but that is conjecture.
Hopefully in the future those vendors will make submissions so customers can understand both the relative performance of those systems against SAP HANA, but because the SAP Benchmark Council have a full disclosure policy on all benchmark methodology, also the amount of tuning effort required to get good performance.”
Isn’t perfect is a distinct understatement. The BW-EML is an entirely rigged affair.
SAP will disallow any database vendor that produces a superior benchmark in the BW-EML to HANA by asking for this technical feature to be disabled until the desired outcome is obtained. SAP has put itself in the position to lie about any benchmark because it has made such exaggerated claims around HANA. Appleby finishes off the quotation in the most disingenuous fashion, pretending that SAP wants to help its database competitors to improve “customer understanding.”
Interesting, if beaten in benchmarks, is SAP willing to apologize for years of false statements about HANA?
Let’s assume the answer is no.
Secondly, Appleby entirely misleads readers by hiding the fact that a large number of benchmarks that SAP has historically required other vendors like Oracle and IBM to perform for certification have not been performed or at least published for HANA. If SAP followed the same rules that it makes other database vendors follow, then HANA could not be certified!
This point is parallel to a statement from Kuen Sang Lam of Oracle in his article on benchmarking from 2016.
“You will be able to find SD benchmarks for ALL the different databases supported by SAP including Oracle, DB2, MS SQL, MaxDB, SAP(Sybase) ASE, and even Informix. The only database which did not have any published SAP SD benchmark was SAP HANA. It was very strange for the owner of the application to not to have its own designed benchmark published using their own In-memory database.”
Conclusion
The primary point was for Appleby to distract the reader from the fact that the BW-EML benchmark has been rigged to make HANA look far more effective than it is. And Appleby entirely misleads his readers, leaving out critical information so he can engineer his desired conclusion. Appleby fills the article with paragraphs that don’t have to do with the benchmark, and the overall article has the distinct feel of someone tap dancing around the real issue.
This article receives an accuracy of 0 out of 10. It is intended to mislead readers as to a new rigged benchmark by SAP.