
How to Understand Serverless and AWS Fargate
Executive Summary
- Serverless or autoconfigured servers provide for effortless scaling.
- Serverless has enormous opportunities for reducing the overhead of infrastructure.

Effortless Scaling with Serverless
“Serverless” allows effortless scaling. This is possible because AWS and Google Cloud have, in effect, no capacity limitation, and they have developed the capabilities to adjust resource consumption based upon the load. “Serverless” is having the impact of taking over some of the services selection from the developer. When a non-“serverless” service is used, the customer can set autoscaling and selects the supporting items (which database, which memory, etc.). However, with “serverless,” the customer leaves that to AWS or Google Cloud.
Our References for This Article
If you want to see our references for this article and related Brightwork articles, see this link.
“Serverless” can also be thought of as the following:
“Cloud computing, which started with Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and Software-as-a-Service (SaaS), is fast moving into a Function-as-a-Service (FaaS) model where users don’t have to think about servers. Serverless applications don’t require the provisioning, scaling, or management of servers, as everything required to run and scale the applications with high availability is provided by the platform itself. This allows users to focus on building their core products, instead of worrying about the runtime infrastructure demands; and to pay only for the actual compute time and resources consumed, instead of the total uptime
Another remarkable feature of serverless functions is their near-infinite scalability — the ability to scale from virtually nothing to literally tens of thousands of concurrent instances — which makes them perfect candidates for handling highly variant and highly unpredictable loads, such as traffic for a real-time sports score app..”
All non-“serverless” services are sometimes referred to as “server full.”
According to AWS, for a service to qualify as “serverless,” it must offer the following capabilities:
- No Server Management
- Flexible Scaling
- High Availability by Default
- No Idle Capacity
AWS states that the following services can support “serverless.”
- AWS Lambda
- Amazon Athena
- Amazon API Gateway
- Amazon Simple Storage Service
- Amazon DynamoDB
- Amazon Simple Notification Service
- Amazon Simple Queue Service
- AWS Step Functions
- Amazon CloudWatch Event

Some people think that “serverless” creates mass unemployment among servers. But it’s not true! There is still plenty of work available for servers.
Function as a service is part of “serverless” computing essentially skips over containers and functions against a “serverless” service or self-configured services like AWS Lambda (the “serverless” function is called a “lambda”). Lynn Langit describes serverless as the following:
“A service that abstracts away the management of containers.”
Google Cloud’s “serverless” service is called Google Functions. Google Cloud calls Google Functions the “simplest way to run code in the cloud.” Moreover, while the effort involved in configuring servers comes way down, so does the amount of code written, which is typically considered a small fraction of the code required for the traditional approach. Therefore, while the category focuses on the configuration reduction as the named benefits, that is only a part of the benefits offered by “serverless.”
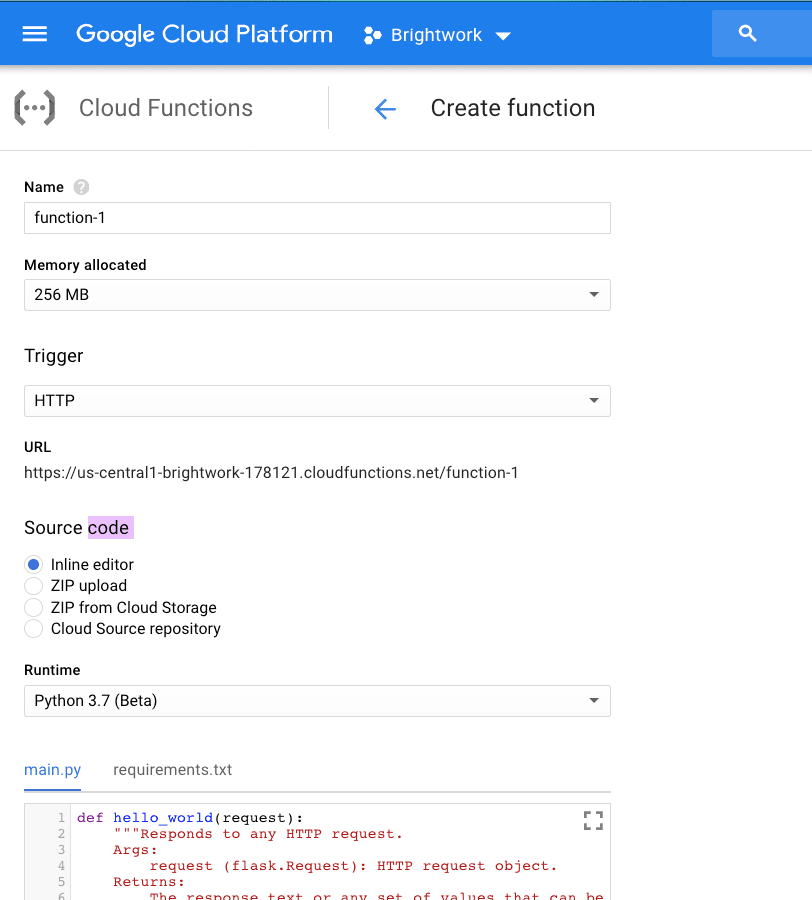
Once set up, functions can be easily copied.
AWS Fargate
A second “serverless” variation on the EC2 service is AWS Fargate. Fargate is used for long-run processes that you don’t intend to be running permanently (so test environments) instead of which Lambda tends to work better for shorter-term processes. Legacy or monolithic applications are more challenging to migrate to “serverless”/auto-configured server services. Fargate does not isolate functions, while Lambda does. This makes Lambda scale better.
Fargate is less known than we think it should be for a few reasons, but it is not its own service but a modality or a configuration of the EC2 service. So it requires an EC2 instance to use, but it takes care of all the EC2 setup automatically.
Called “containers on-demand” by AWS, also known as “Lambda, but for your containers,” Fargate interacts with containers. At Mark Dalton’s AutoDeploy, they ported all of their JDE migration product to it. AutoDeploy finds auto-scaling to provide awe-inspiring results. The overall service is a high-end value add.
How Fargate is brought up is explained in the following quotation.
“AWS ECS supports two launch types, EC2 and Fargate. With the EC2 launch type, EC2 instances are started to run Docker containers. The Fargate launch type, which was introduced recently (November 2017), hosts tasks that encapsulate Docker containers. The tasks are directly made accessible to the user via an Elastic Network Interface. The EC2 instance on which Fargate is provisioned are not accessible to the user and are not directly accessible.”
Therefore with the Fargate launch type, the infrastructure is entirely managed by Fargate. The ideal is to get to only the functional unit of code. The intent is to get as much as possible into a container.
Is FaaS Really Much Different Than PaaS?
What will most likely happen with “serverless” or self-configured servers is that current PaaS providers like Heroku and Cloud Foundry become the tool for “serverless” and therefore address functions (through Google Functions, AWS Lambda).
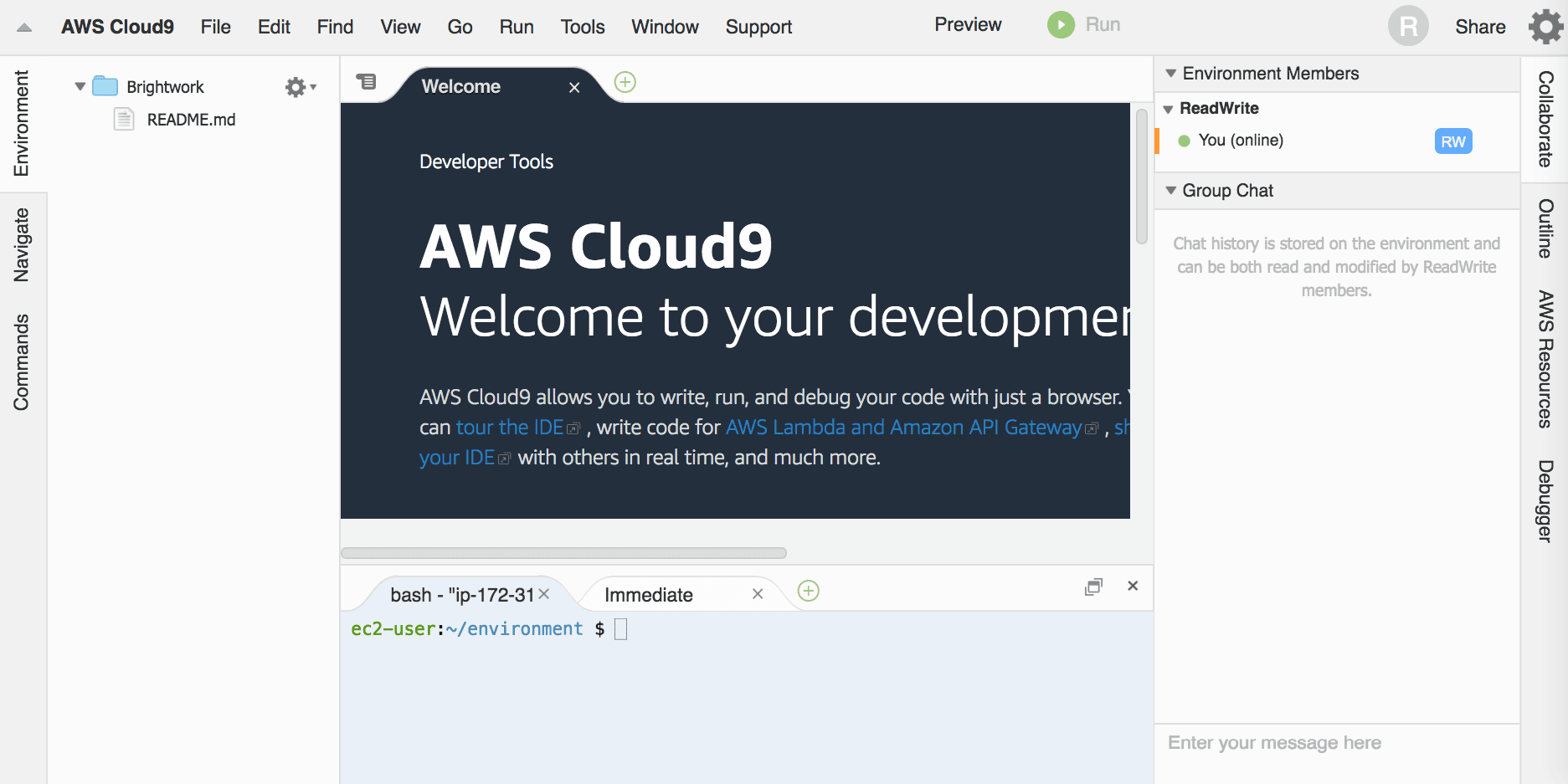
If we look at Cloud 9, which was an IDE acquired by AWS, it is now promoted as a “serverless” or function framework. Cloud 9 has some collaborative features but appears to be more of an online IDE than a PaaS.