
The Problem with Machine Learning for Supply Chain Forecasting
Executive Summary
- Machine Learning is a significant area of interest currently, and proponents of machine learning are proposing pulling investments from univariate statistical forecasting.
- There is a competition among vendors to make silly statements around machine learning.

Introduction to Machine Learning
The term machine learning has been popular for some time now. Machine learning is a term used by many as sort of a catchall for intelligent improvement…..but the vast majority of people who use the term (at the prompting of vendors and consultants) don’t know what the term means. In this article, we will investigate the term to see if it applies to supply chain forecasting.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
What is Machine Learning?
Part of Wikipedia’s definition of Machine Learning is the following:
“Machine learning is a field of computer science that gives computers the ability to learn without being explicitly programmed.[1]
Arthur Samuel, an American pioneer in the field of computer gaming and artificial intelligence, coined the term “Machine Learning” in 1959 while at IBM[2]. Evolved from the study of pattern recognition and computational learning theory in artificial intelligence,[3] machine learning explores the study and construction of algorithms that can learn from and make predictions on data[4]”
We need to be concerned about the term machine learning because there is little to differentiate it from the term “artificial intelligence” (AI). And new terms for the same thing are typically invented when the initial movement behind the first term either did not work out or failed to meet expectations (observe the term Lean as a replacement for JIT). The normal course of action of people who get behind something which fails is not to issue written apologies but instead to rename the item or move on promoting something else.
And indeed, AI did not work out. AI had an enormous amount of hype around it, but the predictions of what AI would be able to do did not come true.
When Should Machine Learning be Used?
This observation about using machine learning is from the book Introduction to Time Series Forecasting in Python.
“We turn to machine learning methods when the classical methods fail. When we want more or better results. We cannot know how to best model unknown nonlinear relationships in time series data, and some methods may result in better performance when working with non-stationary observations or some mixture of stationary and non-stationary views of the problem.”
What is curious about this statement is that machine learning is often invoked as a primary method to improve statistical forecasting.
However, my observations from many clients at this point is that the classical methods of statistical forecasting do work for most of the product database of my clients (the portion for which they do not work being labeled as unforecastable), which I cover in the article How to Best Understand Forecastability.
**For those that say that machine learning will be useful for forecasting items that are unforecastable by classical forecasting techniques, the reader should be aware that a long history exists of software vendors proposing they could improve patternless items’ accuracy. And with the hindsight of history, those claims have not come out well in the wash. Crostons can improve such items’ forecast accuracy, but the forecast accuracy never becomes “good.”
The Underinvestment in Statistical Forecasting
Companies invest too little in the way of resources in improving forecast accuracy using these classical techniques.
A second issue is that companies often will listen to a Deloitte or Accenture that leads them into choosing the wrong software for them, which improves Deloitte or Accenture’s ability to bill hours at the expense of the client, as we cover in the article Why Companies Choose the Wrong Forecasting Software.
Firms like Deloitte and Accenture damage the ability of their clients to perform statistical forecasting in two dimensions.
- First, as noted, they pre-select the vendor based on their internal billing needs (the big consulting companies recommend none of the lower cost but highly effective applications in the forecasting market).
- Second, they gobble up so much money in the implementation that they have consumed as much as possible of the budget for forecast improvement when they leave the client. Companies that use these firms will never meet the promises made by these firms for the business improvement they will see because these firms perpetually exaggerate as a normal way of doing business.
What is Our Forecast Error Again?
The vast majority of companies that use supply chain forecasting don’t measure their forecast accuracy at the product location combination or the SKU-L.
My clients should generalize or skew “too optimistically” as they tend to be quite large and have many resources. Smaller companies have less to spend.
Companies track their forecasting accuracy at a level of aggregation higher than the SKU-L.
**Forecast error calculation at levels above the SKU-L — while useful for sales, marketing and finance are not helpful for the supply chain, as the supply plan consumes the forecast at the product location. It is not possible to create a purchase order for a “product family.” A purchase order must be created for a product, and it must be created for a specific date and a location. It is illogical to have a purchase order for a product to all locations.
Forecast Error Measurement as the First Step to Forecast Accuracy Improvement
Knowing the forecast error at the product location combination (and a weighted MAPE or wMAPE so that the high forecast error on the smaller volume items does not pollute the overall forecast error calculation is critical to making forecast improvement.
Are we to believe that companies that don’t or can’t track their forecast error at the product location, that underpay demand planners, and make some missteps regarding leveraging basic statistical forecasting are now ready for a much larger investment in machine learning?
Why?
And why are these more expensive methods being used if classical statistical forecasting methods are so far away from being adequately implemented?
Explaining the Emphasis on Machine Learning
This brings up the question that I think is quite important to ask.
If the classical statistical forecasting techniques are so underutilized in companies, why is there a focus by software vendors on discussing machine learning?
- Is it possible that there might be some puffery involved?
- Could it be some trickery with pulling one over on those that don’t focus on either statistical forecasting or machine learning?
- Is it even possible that software vendors and consulting companies, and software vendors that have no intention of using machine learning to improve their customers’ forecast accuracy are using the term to hypnotize their prospects?
None of these things could be the case…….
Understanding The Reality of How Machine Learning is Performed
While reading the book Machine Learning Mastery With Python, I kept noticing that we would run algorithms in the program in the exercises.
These algorithms have different names, like “Random Forrest,” “Extra Trees,” or “Stochastic Gradient Boosting.”
And then, these algorithms can be automated.
But I kept thinking..
“When is the machine learning coming?”
Then it dawned on me.
Machine learning is just setting up algorithms and scheduling them to allow them to churn on data sets. Maybe at the end of it, you have a sequence of algorithms that run such that it looks like the computer is running on its own.
But is that the machine doing the learning?
Not really.
Instead, I (a human and not a machine) am setting up the algorithm. The machine runs the procedure, and then I adjust the algorithm or test a new one and then review the results. Once I find an acceptable one, I can schedule it to run against a product location combination.
The machine is “learning” in the same way that God plants seeds in the soil. In that, if you want a harvest, you better go and plant the seeds yourself because God always seems somewhat distracted.
A Refresher on Statistical Forecasting in Supply Chain Environments
People that discuss machine learning for statistical forecasting don’t appear to understand how statistical forecasting works. (or they do know and are lying…you can choose from A or B, there is no C.)
First, computers are so powerful that they don’t churn away for hours on univariate (a single time series) data. And….virtually all supply chain forecasting is univariate, because..
- For one, companies normally don’t have multiple variables to work with and don’t put effort into finding new ones to add to their database.
- History is often a potent predictor of the future. Univariate forecasting is a bit of a godsend because its fundamental simplicity allows it to be mastered and controlled.
It is improbable that machine learning (that is, running a complex algorithm in a scheduled manner) will tease out more relationships from the worst part of the product database. Remember that with classical statistical forecasting, we already have (a type of machine learning) called best fit that searches for a match between the method (i.e., moving average, Winters, regression, etc..) and which alters the parameters of these models.
Machine learning requires more time series, referring back to Time Series Forecasting with Python.
“The goal of time series forecasting is to make accurate predictions about the future. The fast and powerful methods that we rely on in machine learning, such as using train-test splits and k-fold cross-validation, do not work in the case of time series data. This is because they ignore the temporal components inherent in the problem.”
Machine Learning Enabled Vendors?
And when the machine learning-enabled software vendors show up on the shores of their customers with their algorithms and find univariate data of sales history — what will they do then.
Let us hope all of these things are worked out honestly in the sales process.
So fairly sophisticated pattern recognition is already available in nearly all statistical forecasting applications — and best fit has been around for some time now.
Understanding the Forecasting Maturity Model
This brings a point around maturity. The following is, I think, a reasonable explanation of the maturity model of companies that perform supply chain forecasting.
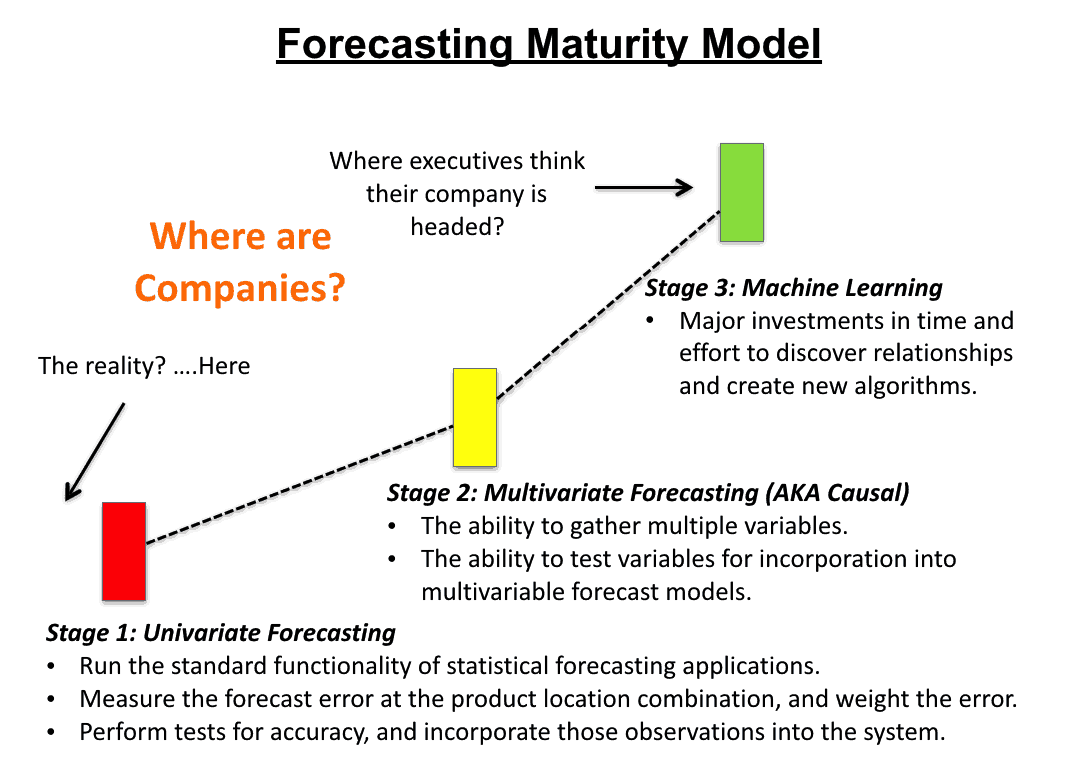
As you can see, most companies are not even onboard at Stage 1. Stage 1 is the easiest and takes the least investment. Every supply chain forecasting application on the market can perform statistical forecasting, and the methods used are extremely well tested with oodles of academic papers on them.
Differentiating Offerings
But instead of getting customers on board at Stage 1, some vendors and consulting companies are trying to differentiate their offering by promising their prospects and current customers in Stage 3.
Why?
Is this a strategy built around improving the condition of their prospect and customer’s forecast accuracy, or is this about making sales using sexy terminology?
Now I showed this article to a person with ToolsGroup experience, and they stated the following.
“On ML needing more sophistication than casual, just means their ML solution is not packaged, but a custom tool. For the RS components example (like all other TG implementations of ML) there literally is only a single page with a handful of options to set. The rest is getting the data.”
So in some cases, the ML can be “canned.” In that case, its ability to be effectively deployed is higher.
The Other Problem with the Term Machine Learning
Machine learning describes a process by which some algorithm is run in a scheduled way (use the term automated if it feels better) on a data set. But it merely means there is less human intervention.
So the term is extremely unspecific. It is like telling someone you are going on vacation. And when they ask where, you tell them, “Europe.” It’s not wrong, but it does not tell them very much about where you are going.
Therefore, software vendors that use the term that they are going to “use machine learning” need to be asked what they are (specifically) going to do. Otherwise, it just becomes a prestigious word.
Neither machine learning nor Europe is acceptably specific answers. If one is going to do machine learning, then what will be done needs to be explained.
Furthermore, why the generality concerning the term machine learning? If you ask a person where they are going on vacation and say Europe, the two are not very close. That person does not want you to know where they are going. It does not seem like there is much trust in the relationship.
A Competition to Make Silly Statements About Machine Learning
The current articles on machine learning in supply chain forecasting are easy targets.
The first is from Arnaud Hedoux of Dynasys.
“The adoption of machine learning is the key driver in the ‘arms-race’ between software vendors to achieve differentiation.”
It isn’t easy here to see if Arnaud is speaking of the actual differentiation of marketing differentiation. But his title is “Director of Marketing.” So it is safe to say he does not know what machine learning is.
The second is from Adeel Najmi from One Network Enterprises. He has a P.h.D, so let’s see his take.
“Learning occurs when a machine takes the output, observes the accuracy of the output, and updates its own model so that better outputs will occur. Any machine that does this is using machine learning. It doesn’t matter if data science methods are used or not. It does not matter if neural networks or some other supervised or unsupervised learning technique is being used. It’s important not to get bogged down on the specific technique. What matter is if the machine is itself capable of learning and improving with experience.”
That statement is true. But it does not necessarily hold that this occurs in supply chain forecasting.
Do I Have a Fusion Reactor?
The sun produces light through a process of fusion. But that does not mean I have a fusion reactor in my basement or that I am presently using it to power my house (I might want to, but that is the difference between the potential future and the present).
The following is from Steve Banker writing for Forbes.
“Over time, many more data inputs have been introduced into the demand planning process, and many companies are doing far more forecasts.”
Really? That is the opposite of what I have seen. Again, even multivariate forecasting in a supply chain is exceedingly rare.
“For example, instead of just doing a monthly forecast in the eastern half of the country, some companies are doing forecasts at the product/store level at daily, weekly, monthly and longer time frames.”
No company does a forecast for just “the eastern half of the country.” Companies have to forecast at the product location. If not, what goes into supply planning…..a forecast for the eastern half of the country?
How would that work exactly?
As for daily forecasting, daily forecasting is the hobgoblin of the mind of people who do not understand statistical forecasting. Even weekly forecasting often reduces forecast accuracy, as we cover in the article Test Results: Monthly Versus Weekly Forecasting Buckets.
A Planning Horizon?
A time frame referred to by Steve Banker sounds like a planning horizon. If so, the author might be switching between the planning bucket and the planning horizon.
But if we interpret it to mean the planning bucket, few companies forecast a planning bucket larger than a month. Still, it can be beneficial, as we cover in the article Test Results: Quarterly Versus Monthly Forecasting Buckets.
“For a product being forecast daily at the store level, it may be that algorithms applied to the POS data stream have the most predictive power. Forecasting that same product at the warehouse level on a monthly basis, an algorithm applied to warehouse shipment history and warehouse ordering patterns has more predictive power.”
It is improbable that the forecast at the store level based on POS data will beat the warehouse’s forecast.
- For one, the warehouse has the law of large numbers on its side.
- Secondly, why are you forecasting at the store level? The stocking location is the warehouse, not the store.
I have had clients repeatedly ask that I produce forecasts at the store level, primarily because of people who write articles like this.
“A forecasting engine with machine learning just keeps looking to see which combinations of algorithms and data streams have the most predictive power for the different forecasting hierarchies. When if finds it can improve the forecast, it either changes the model or suggests to the planner that the model should be changed in a specific way.”
Really, in a completely automated fashion?
A Hypothetical Forecasting Application
Is this a hypothetical forecasting application for the supply chain, or does this exist? You see, you can’t tell how it is written. A spaceship that can travel at the speed of light can reach the galaxy Alpha Centauri in 4.36 years. That sentence is true. But that does not mean such a spaceship exists.
It appears there is some exaggeration going on here. Forecasting applications exist that test all of the dimensions that could improve forecast accuracy. However, I have not seen this in any forecasting application to date.
Ph.D.s to the Rescue!
“In short, SCP companies, with their cadre of operations research Ph.Ds who have been modeling complex problems for decades may be better poised to solve many complex business problems than the hot new Silicon Valley firms.”
We had a lot of Ph.D.s at i2 Technologies. It did not save us. At that time, the “hot” thing was supply chain optimization. After we repeatedly bombed on optimization projects, that took the temperature down quite a bit. And who are the hot new “Silicon Valley firms?” Are they focusing on supply chain forecasting? If so, this is great news. I can’t wait for all of this hot Silicon Valley action to show up on my forecast improvement projects.
Conclusion
As is normally the case, there is a lot of smoke being blown around with a new hot trendy term. But given the problem that is being solved with supply chain forecasting, companies’ willingness to invest in forecasting (even the biggest of most of my clients is quite large). The continued shortcomings in mastering a far less complex forecasting category portents poor machine learning outcomes in supply chain forecasting. Some software vendors are misleading customers and prospects about how machine learning works, making it seem like yet another in a long line of easy buttons. Easy buttons have a long history of not working in statistical forecasting, but the search for easy buttons continues unabated.
Can machine learning, or should I say adaptive algorithms set up and controlled by humans, be used to improve forecast accuracy. Certainly. But is this something that applies to a small segment of companies with the funding and patience, and budgets to invest in these improvements? But, vendors’ explanations of machine learning do not draw this distinction, implying that ML is for “everybody.”

Right after we found out from software vendors that machine learning was for everyone, we started writing our new book called Quantum Physics for Everyone. This book will soon be decorating automobile body shops and hair salons around the country to be published by Brightwork Press! The book requires no previous exposure to physics yet will push into the most advanced areas of physics.
The Problem Laid Out in Machine Learning for Forecasting
The problem laid out in machine learning is that the object appears to be based upon unrealistic goals. Secondly, some of this puffery is designed to appeal to venture capital firms. Venture capital firms want to hear about the latest buzzwords. If any of them had to work on an actual statistical forecasting project, they would probably come away very depressed.
But in all of this, the reality of what will improve supply chain forecasting is a secondary concern. The real focus is to exaggerate expectations, then get and cash stock options. After you have retirement or play money, how accurate you were in what you said would disappear into the background.
The Undiscussed Issue Around Machine Learning for Forecasting
The problem with machine learning, as presented for forecasting, is that the current error measurement within companies is undiscussed. Many projects, including forecast improvement projects, are sold without any consideration for the outcome. The intent is to make exaggerated claims and then stall the project’s measurement of outcomes to accumulate the maximum number of billing hours. This is currently a massive problem with AI/machine learning projects.
This video was removed from YouTube by SAP.
Vendors and consulting firm websites are filled with false claims around AI and machine learning for forecasting. These claims make it clear that the concern in most cases is selling the project, not actually being able to deliver upon what is sold.
When visiting SAP accounts, none of the things described in this video are apparent. SAP has migrated its claims around “predictive analytics” to “machine learning” now that machine learning is hot and predictive analytics are not. In a few years, these same claims that are now being used to sell machine learning software and projects will be migrated to whatever is the new term at that time.

If your forecast improvement project is sold based on pretenses, you do not want the forecast value to be measured. For this reason, IBM postpones forecast error measurement on their projects as long as possible, preferring to talk about how great the INPUTS are and the great future potential for forecast improvement.
IBM has been obvious that they measure success by the number of projects sold, not the forecast value add as we cover in the article How Many AI and Machine Learning Projects Will Fail Due to a Lack of Data?