How to Slim and Re-platforming the Data Warehouse with AWS Glue and Anthem
Executive Summary
- Data warehousing and data lakes are being re-platformed for the cloud.
- When re-platformed to the cloud, data warehousing and data lakes have additional capabilities.

Introduction
Cloud is causing major changes in the data warehouse and data lake spaces. Cloud is going to result in a significant reconfiguration of the data warehouse market. It is already leading to an increase in choice and a move away from monolithic data warehouses. And on AWS, one of the components that support this change is Amazon Athena and Amazon Glue.
Our References for This Article
If you want to see our references for this article and related Brightwork articles, see this link.
Amazon Athena and Glue
Amazon Athena is one of the most quizzical or unexpected serverless services. Athena works on files to be uploaded to an S3 bucket. The load is supported by AWS Glue, which is an ETL service that simplifies preparing and uploading data. Glue discovers data and the associated metadata, and once cataloged, the data is “immediately searchable, query-able, and available for ETL.” We will discuss Glue about Athena, but it also works with RDS, DynamoDB, Redshift, and S3 (which is how it integrates with Athena).
AWS describes glue as follows:
“AWS Glue is a fully managed ETL (extract, transform, and load) service that can categorize your data, clean it, enrich it, and move it reliably between various data stores. AWS Glue crawlers automatically infer database and table schema from your source data, storing the associated metadata in the AWS Glue Data Catalog. When you create a table in Athena, you can choose to create it using an AWS Glue crawler.”
The ability of AWS Glue to do this means it creates an AWS Glue “data catalog.” This reduces the time between data ingestion and use because AWS Glue can begin working with the new data with little processing, as illustrated with Athena.
Amazingly, Glue is not only compatible with multiple data sources, but it also works across different data sources.
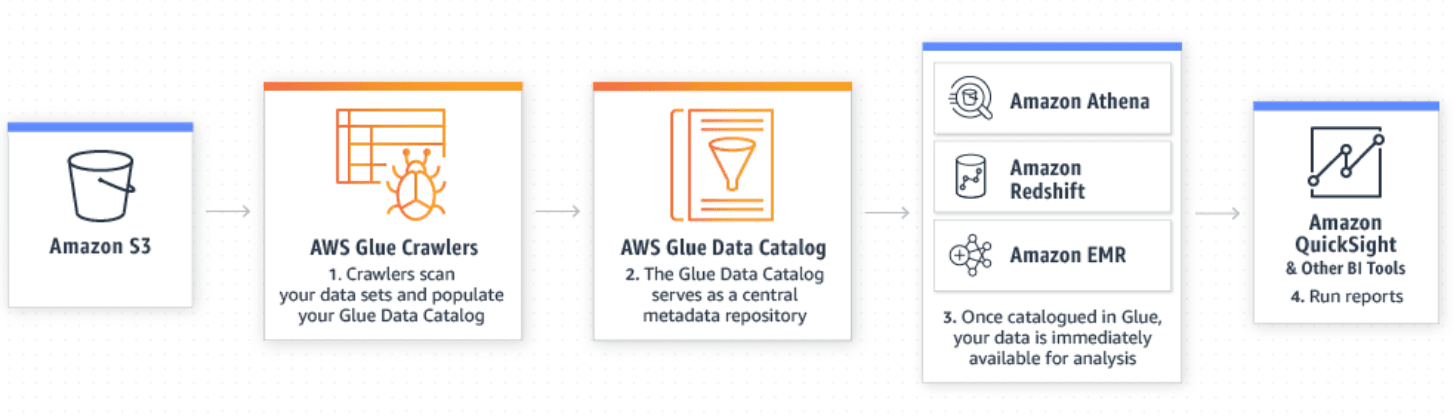
The AWS Glue Crawler will create a metadata repository called the AWS Glue Data Catalog that allows a virtual database.
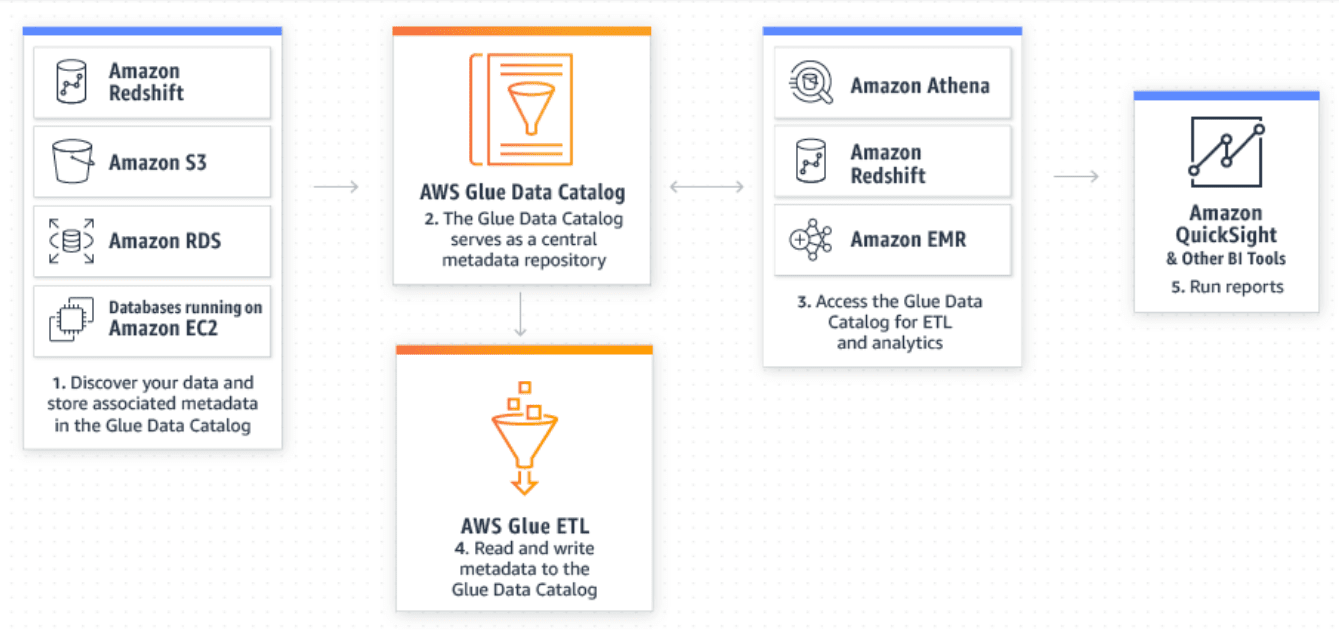
Notice the relationship between the AWS Glue Data Catalog and other components.
This topic is explained in the following quotation.
“The AWS Glue Data Catalog provides a unified metadata repository across a variety of data sources and data formats, integrating not only with Athena, but with Amazon S3, Amazon RDS, Amazon Redshift, Amazon Redshift Spectrum, Amazon EMR, and any application compatible with the Apache Hive metastore.”
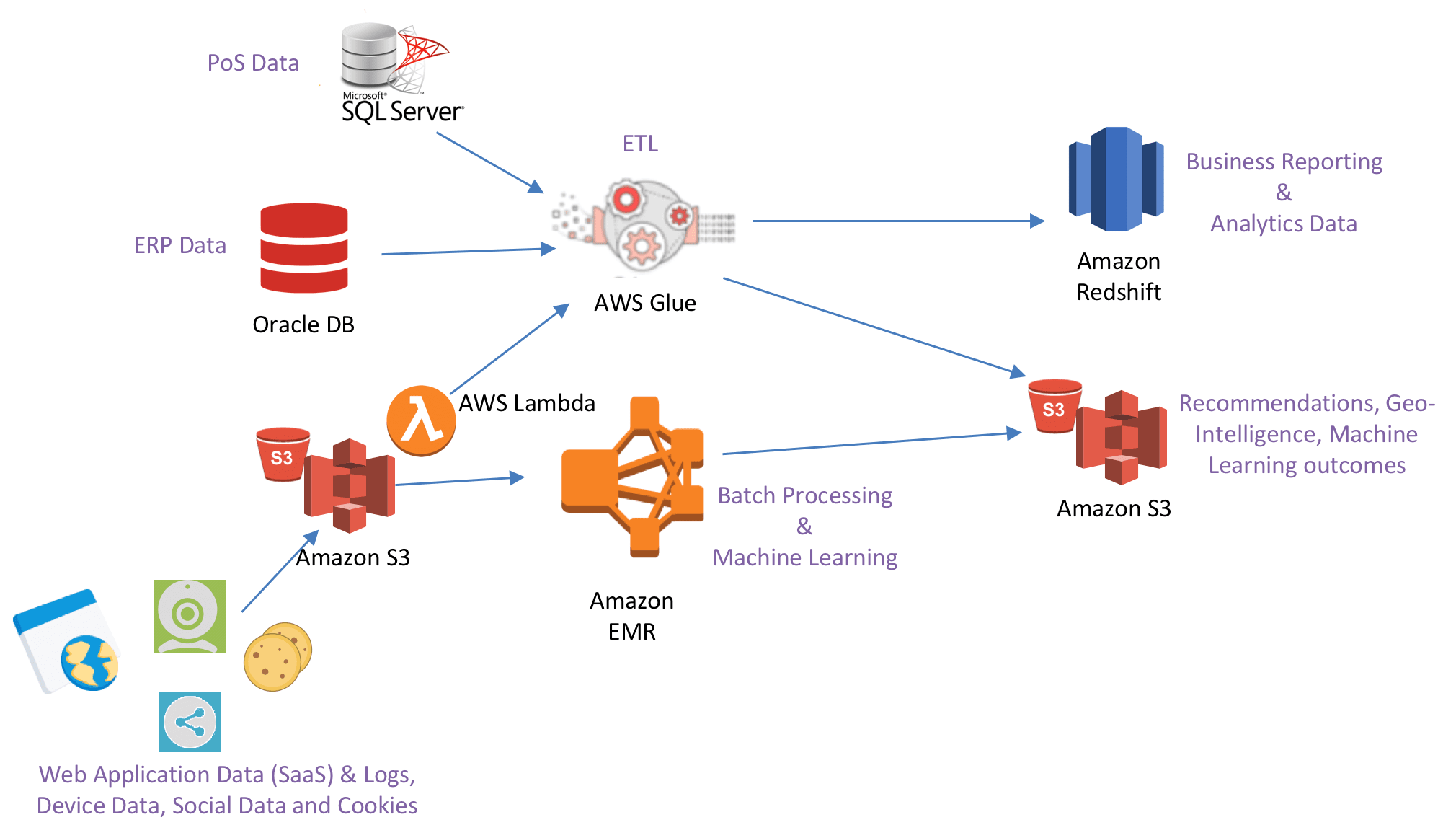
Observe how AWS Glue can tie together many different data sources. But also note that AWS Glue can also interact with Lambda.
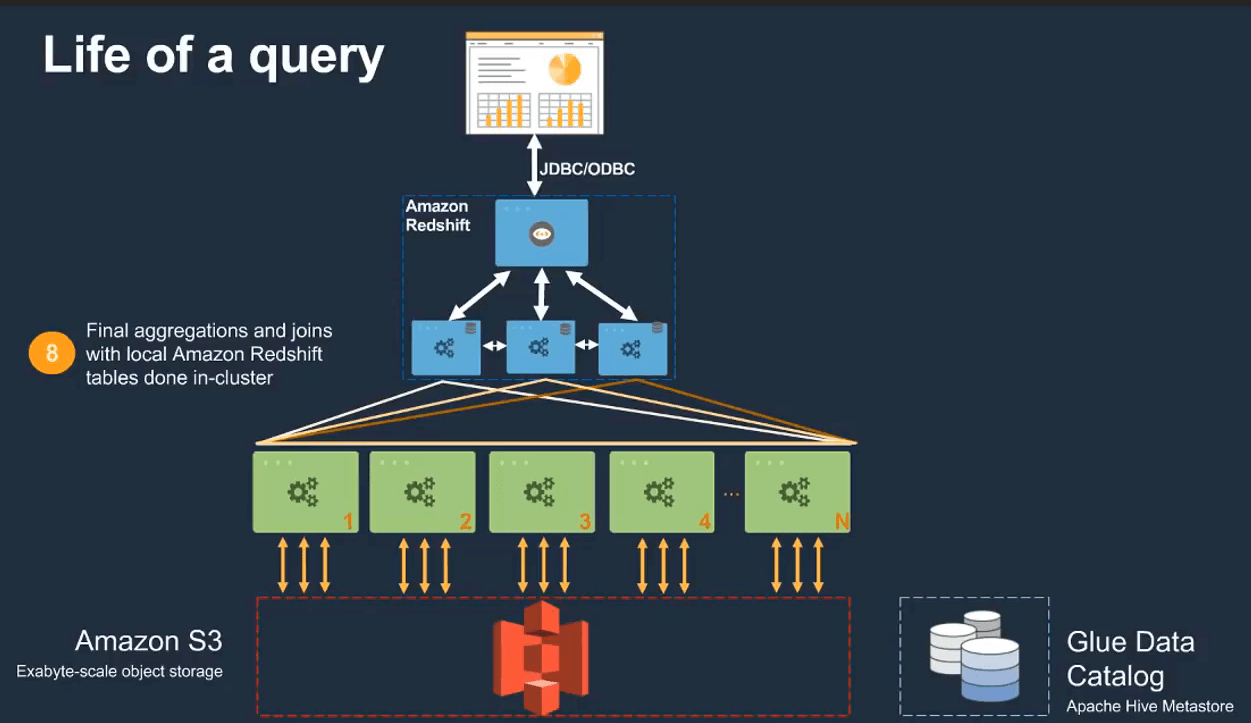
Notice the AWS Glue Data Catalog. It connects the various data sources through discovery. In this case, the queries are being run from Amazon Redshift, AWS’s data warehousing solution to S3, to data outside of Redshift.
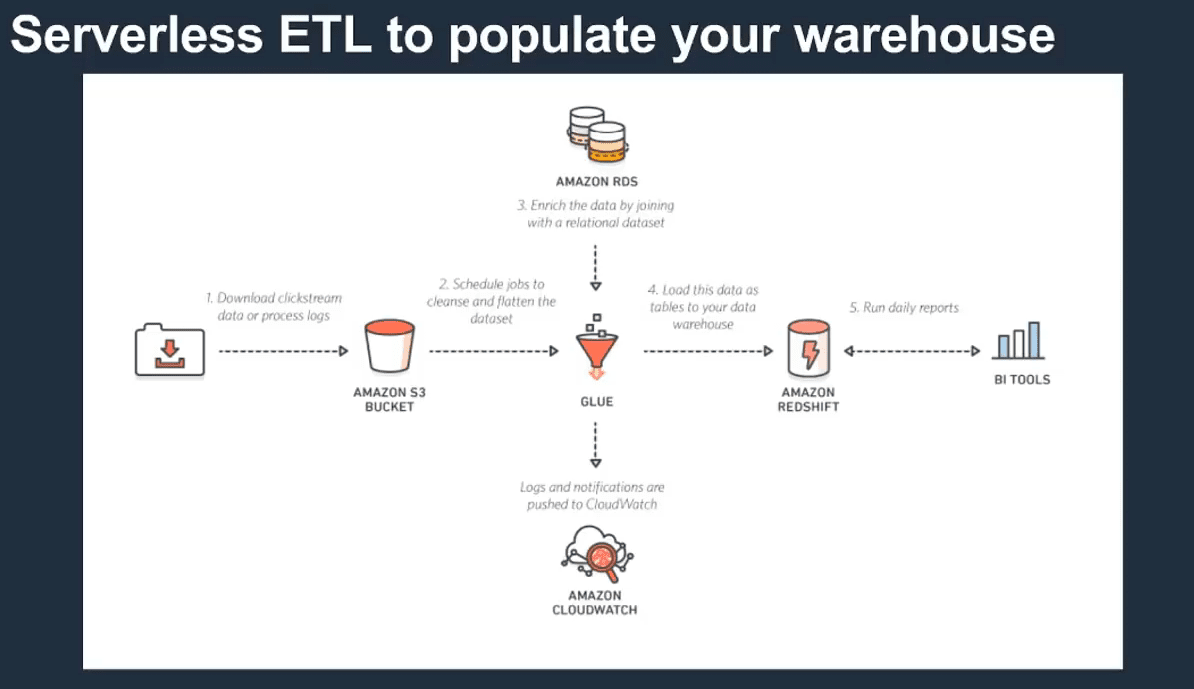
This is another view of how Glue fits into the data warehouse design.
AWS Glue also allows data to be moved between data stores. However, there is something quite appealing about when Athena is used with the only S3, which means one does not need to spend time structuring and organizing data before performing queries on data. Athena is a service that allows SQL queries and normally ad-hock or in-frequent queries to be run against a logical schema is flexibility and quickly applied to a text file or text files. The logical schema is superimposed on the files loaded into S3. AWS describes Athena this way.
“In Athena, tables and databases are containers for the metadata definitions that define a schema for underlying source data. For each dataset, a table needs to exist in Athena. The metadata in the table tells Athena where the data is located in Amazon S3, and specifies the structure of the data, for example, column names, data types, and the name of the table. Databases are a logical grouping of tables, and also hold only metadata and schema information for a dataset”
AWS Glue, Athena, and S3 begin to question the different distinctions or dividing lines between constructs like data warehouses and data lakes. Let us review the definition of these two terms.
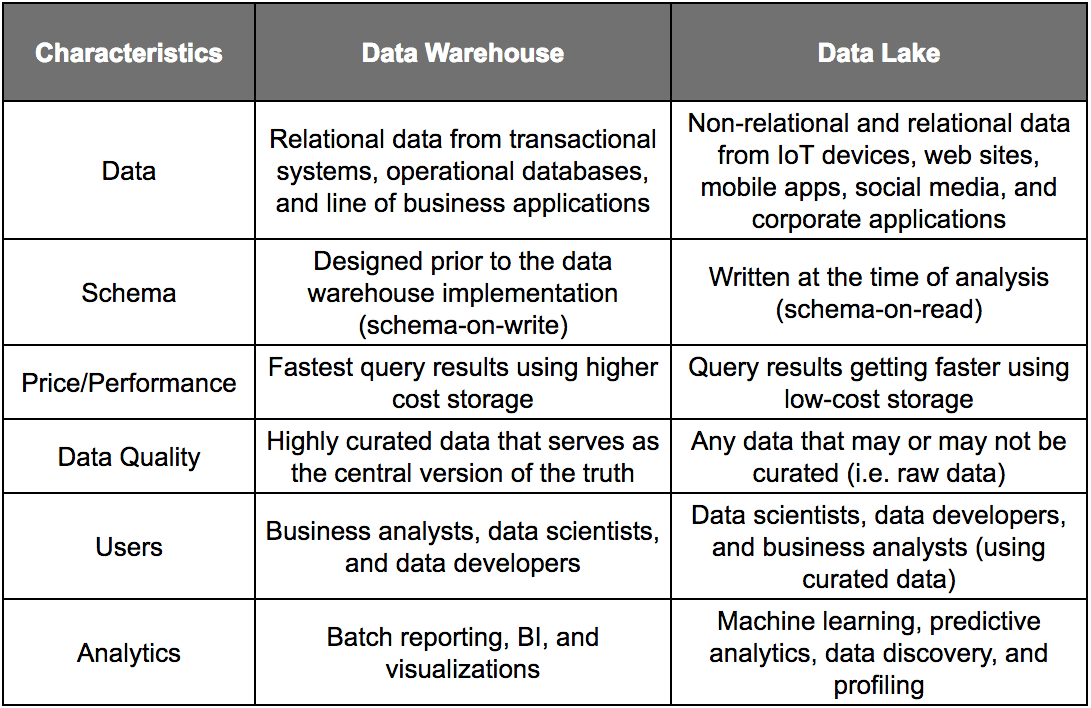
This table is from AWS only.
Notice the data warehouse is a structured data lake. Data warehouses have been with us for decades. However, the term data lake is relatively new. When comparing the two descriptions, the data warehouse described an end state to a process that never occurs. This is because new data is continuously being brought into the environment. Therefore it seems logical that one must have both a data warehouse and a data lake. It is not an “either/or” situation. Proposing that a data warehouse exists without a data lake would be like suggesting that all of the files on your computer are organized. Some of them are organized (the ones you use), but many of them are not organized, and others never will be. Not all of the data that comes in needs to be placed into a rigid schema or placed into an RDBMS. It is not worth the effort. Every IT department we have seen has far more data than they can ever reasonably manage, so perfectly manicured data sets are not on the table as an option. (or as we like to say, optimal has left the building).
Furthermore, many of the initiatives that are begun around data warehousing are not completed or not completed as advertised. This is covered in the following quotation from Snowflake.
“Many organizations do not have an enterprise data warehouse or data lake. In some cases, they’ve been disappointed by their attempt to create one. Their data sits in multiple, on-premise systems: some used for OLTP, some used for OLAP and some data sits in file systems just waiting to be analyzed. Changing platforms is viewed as an ideal time to re-architect, or architect for the first time a fully functional data platform capable of scaling with the business.”
Secondly, with a service like AWS Glue, queries can be run not only on one data source but instead on multiple data sources (so-called federated queries). Some of those data sources could be Athena, and other sources could be RDBMSs. Alternatively, they might be a key-value database like DynamoDB or a column-oriented database like Redis, but with Elasticache in front of it.
It all depends.
That is, some of the queries will be local, and some will be cross-data source queries. Moreover, when this capability is enabled, it means a federated database or virtual database is created. Wikipedia calls this a virtual database is there is no integration between the database. Instead, queries are run across the federation.
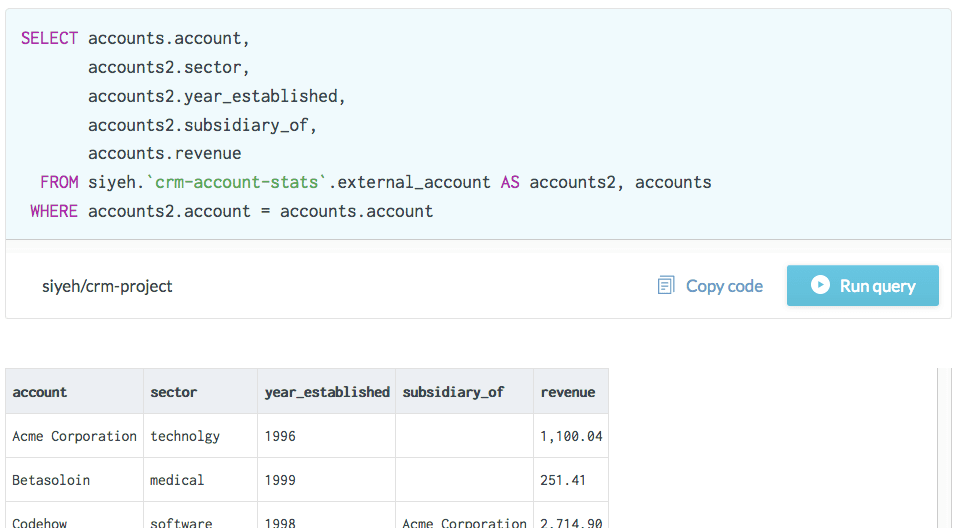
This is an example of a federated query. This runs a select statement for a table called accounts in one system versus a dataset outside of the system called crm-account-stats.
It is incredible to learn that the concept of federated databases goes back to the 1980s, but they are now only recently appearing in reality, and they are doing so because of the cloud.
When reviewing the lifecycle of data, it does not make sense to assume that all data eventually moves to the RDBMS. Some will, some won’t, and there is a triage process where the company should determine, “is it worth the effort to place this data into a rigid schema?” If it isn’t, then don’t. However, one way or another, a data warehouse is going to have a data lake attached.
Furthermore, there may be opportunities to bring new data or data set into the data lake, for example, to perform a correlation with already existing data that is only used intermittently. That is a perfect data set to keep in S3.
Let us review the last row of the table, which explains the difference between data warehouses and data lakes concerning analytics.

A natural question might be, why not perform both types of analysis on data in the data lake. That is batch reporting, BI and visualizations on data warehouse type data sources, machine learning, predictive analytics, data discovery, and profiling on data lake type data sources? After all, as the data sources are held together in AWS with AWS Glue that allows cross-source queries, why conceive a dividing line between the data warehouse and the data lake?
The SAP Business Warehouse (BW)
When we think of the new approach possible in data warehousing, it is instructive to compare it to the old way in SAP and Oracle. The most popular data warehouse in SAP is BW. SAP also purchased Business Objects, but BOBJ has been in a decline since SAP’s acquired them, with new development and support in a long-term continual decline.
SAP BW is an extremely difficult data warehouse to work with, and it has appalling productivity. We reviewed SAP BW in this article MUFI Rating and Risk SAP BW/BI. SAP BW followed a somewhat typical overweight and encapsulated data warehouses pattern in that the reports sit in a lengthy queue. When the report is received, it often does not meet the initial requirement or has taken so long to be developed to be no longer relevant to the business. SAP does provide an ad-hock front end for BW called the BEx Web Analyzer, but it is a weak offering.
SAP has had the most success with its HANA database commercially and in real terms by porting BW to HANA. This speeds BW, but it also undermines many of the reasons for BW as much of BW is a Data Workbench that allows structures to be created that speed queries when BW sits on a row-oriented data store. However, SAP follows the data warehouse concept where data is staged and not analyzed before being pushed through the process placed into a rigid schema. However, SAP does have an answer to how to connect to the data lake. For this, they propose connecting HANA to Hadoop.
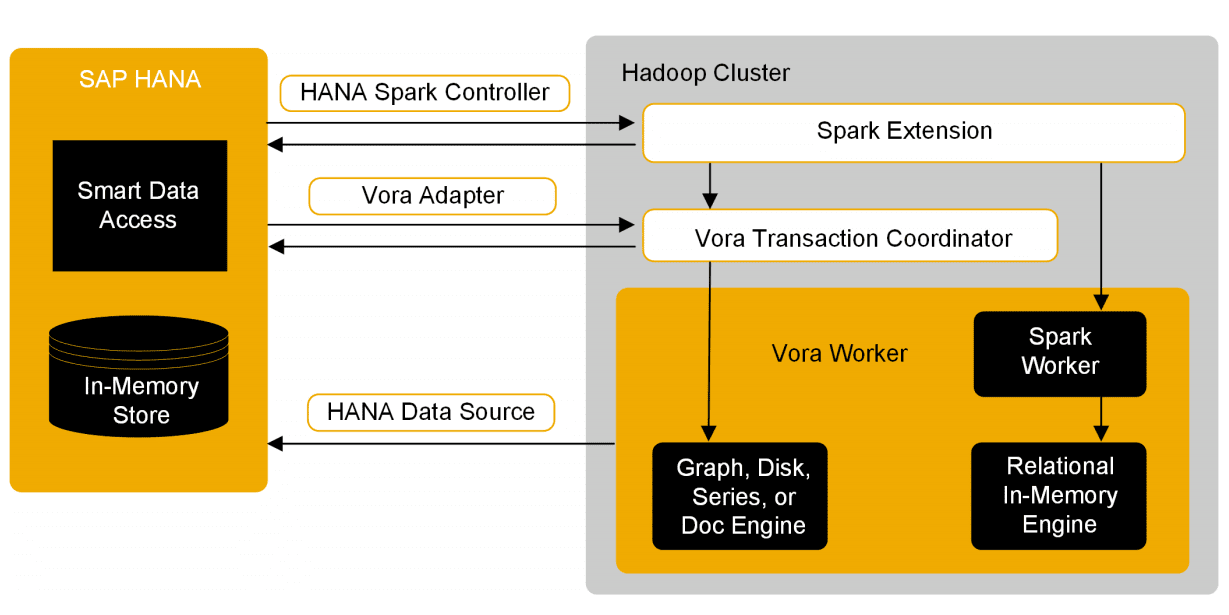
SAP likes publishing these types of diagrams. However, there is a significant problem with this. BW is SAP’s primary data warehouse, and it has been demonstrated to be inefficient. HANA speeds BW, but at great expense. Now SAP wants companies to connect Hadoop to their problematic combination of BW with HANA. Overall, SAP is trying to get companies to take an RDBMS-centric approach to data warehousing, but the difference being that the RDBMS is now connected to Hadoop.
SAP has had many years to demonstrate capabilities and cost-effectiveness with BW and has failed to do so. For this reason, SAP intends to convince customers that their offering is still relevant, given all the changes that are afoot, and one of the ways of doing this is in co-opting new items. For whatever reason, SAP has spent most of its marketing effort in co-opting Hadoop. SAP interpreted Hadoop as the most significant threat to their data warehouse revenues. SAP has spent time influencing customers that Hadoop will not replace the data warehouse. SAP does not say this because it is true, but because SAP sells a data warehouse.
Notice the quote from Timo Elliott from SAP on this exact topic.
“Does this mean that you’ll be able to do more with Hadoop in the future? Yes. Is it going to be easier to make applications? Yes. Is forty years of business process and data warehousing technology and expertise going be obsolete any time soon? No!”
Loosely translated, Timo Elliott would like to ensure that SAP customers keep playing licenses on SAP BW. SAP wants as little adjustment as possible to the current scenario with BW. This scenario does not serve customers, but it keeps money flowing to SAP.
However, the new options available to customers for data warehousing and the data lake is far more extensive than merely Hadoop. Moreover, to query Hadoop, it turned out that NoSQL turned into SQL, and running SQL on Hadoop structures meant putting energy into some degree of organization and increase the relations. As we just described, AWS Glue combined with S3 and Athena – along with other components, means that the RDBMS-centric approach to data warehousing/” data laking” makes less sense.
As with SAP, Oracle is also trying to promote the idea of an RDBMS-centered data warehouse. Recall that Oracle is only dominant in one database type, the RDBMS. Is this the best technical solution? No, but it is what Oracle has to offer. Therefore, for Oracle, every problem looks like a nail that an RDBMS will be “just perfect for.” Their marketing and sales are directed toward getting companies to see data warehousing as a perfect problem for the Oracle RDBMS. However, using data for analytical purposes means de-normalizing that data that is then aggregated. RDBMSs are optimized for highly normalized data (for transaction processing) that is not aggregated.
Thus why are RDBMSs the center of SAP and Oracle’s data warehousing strategy?
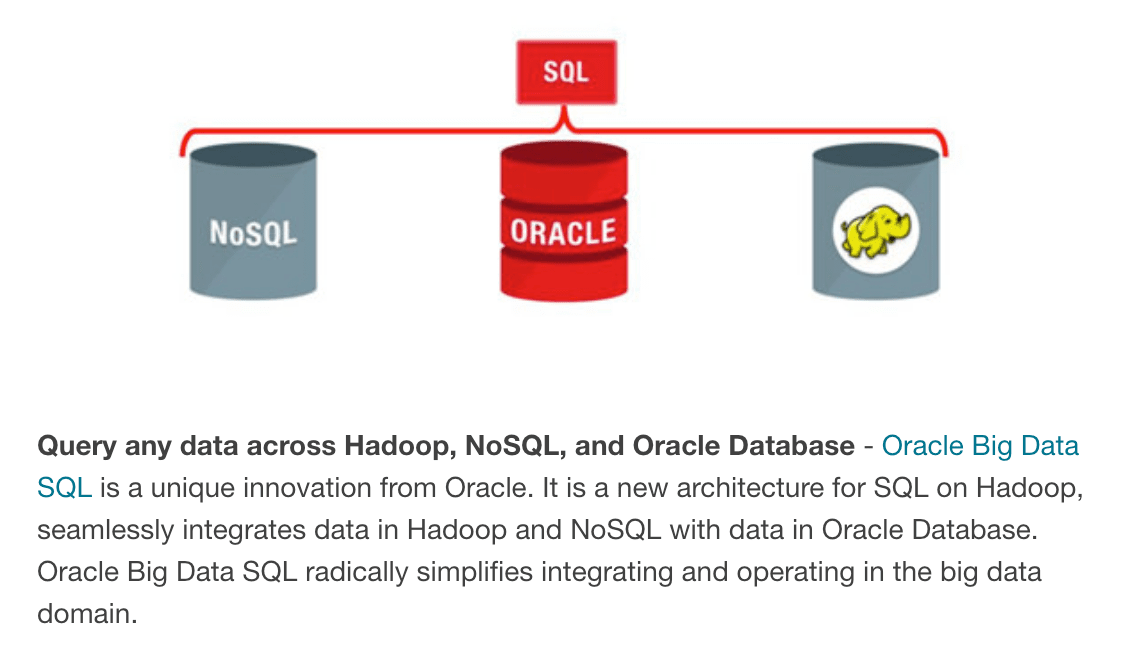
This is how Oracle likes customers to see it in the data warehousing/data lake. Oracle’s RDBMS is right in the center of it. However, the RDBMS was never designed for analytics, or that is for read performance. An RDBMS is not optimized for anything other than transactions that require commit/rollback. An RDBMS does as many writes and locks as reads, while a data warehouse only reads operations. So why is Oracle saying that it is?
The problem with what Oracle is proposing is covered in Dan Woods’s quotation (#2).
“The model of having just one data warehouse is a throwback to a simpler time. In any organization of significant size, there will be a need for multiple repositories. The CDW should participate in federated queries both as a query aggregation point and as a source for queries aggregated by other systems.”
Another concerning thing about Oracle is that they state analytics can be performed using the column-oriented store within their RDBMS. This is explained in Oracle’s documentation.
“Database In-Memory uses an In-Memory column store (IM column store), which is a new component of the Oracle Database System Global Area (SGA), called the In-Memory Area. Data in the IM column store does not reside in the traditional row format used by the Oracle Database; instead it uses a new columnar format. The IM column store does not replace the buffer cache, but acts as a supplement, so that data can now be stored in memory in both a row and a columnar format.
Oracle Database In-Memory accelerates both Data Warehouses and mixed workload OLTP databases and is easily deployed under any existing application that is compatible with Oracle Database. No application changes are required. Database In-Memory uses Oracle’s mature scale-up, scale-out, and storage-tiering technologies to cost effectively run any size workload. Oracle’s industry leading availability and security features all work transparently with Oracle Database In-Memory, making it the most robust offering on the market.”
That sounds good, but Oracle does not compare their offering to other offerings that are less complex and perform better because they are purpose-built for analytics rather than an adjustment to an application database (RDBMS) design. Oracle does not address the maintenance overhead of adding extra workload capability to an already complex Oracle database. For example, purpose-built and inexpensive in-memory databases like Redis or an in-memory data store Elasticache can be integrated into any RDBMS. These services can be easily tested as independent items without going through the overhead of maintaining those items in Oracle. As Elasticache can be flexibly assigned, it can be used in front of virtually anything that requires extra performance. Also, as those services are specialized, they will be better than Oracle’s in-memory addition to RDBMS.
Furthermore, as Oracle continues to add more items to their monolith, the more overhead their RBBMS develops. This evaluation concerning Oracle applies equally to SAP’s HANA and IBM’s DB2. In the past, it would have been far more difficult for customers to test services like Redis or Elasticache, but now they can be brought up in minutes and thoroughly tested. This is reducing the power of the commercial database vendors, hence the need for misleading propaganda. This is to get customers to do things that are against their interests but good for the monopoly vendors.
Oracle is asking customers to invest more into their monolithic database and not follow a microservices approach to database selection based upon database specialization. No doubt, Oracle would be fine with microservices, as long as the Oracle database is used and everything is kept Oracle-centric.
“The ability to easily perform real-time data analysis together with real-time transaction processing on all existing database workloads makes Oracle Database In-Memory ideally suited for the Cloud and on-premises because it requires no additional changes to the application.”
The issue here is that that is not true. Oracle is not as suited for the cloud as Aurora or DynamoDB, or Spanner. These databases have been specifically designed for the cloud. Furthermore, the Oracle RDBMS was not even designed for data warehousing!
A mixed type database such as an RDBMS with a column store (like Oracle RDBMS and SAP HANA) will never perform as well. It will come with extra complexity over a pure column-oriented database like Redis for analytics. If even more speed is required, then ElasticCache can be placed in front of Redis, and it can be added quite inexpensively. The weakness of Oracle’s inability to leverage the multi-base approach shows itself in its designs to customers. This is also a problem when analyzing Oracle’s pronouncements about their RDBMS’s performance or its complexity. The question should always be “to what end.” The RDBMS has a limited window where it beats other database types, and it is particularly suitable as an application database. However, Oracle pushes its RDBMS into places where it is not competitive.
Moreover, Oracle has done this for decades. When there were fewer alternatives and because they were more difficult to access (pre-IaaS), Oracle was very successful with this strategy. But now, with a cornucopia of databases so quickly brought up on IaaS providers, Oracle’s presentation of the universality of their RDBMS is increasingly being challenged.
With Athena, Amazon Quickview can be used as the analytics frontend. QuickSight is an analytics service on AWS.
QuickSight runs on AWS and can easily connect to any AWS data source.
The data comes in extremely easily. It uses either direct query mode or SPICE, which stands for Super-fast, Parallel, In-memory, Calculation Engine is how the data is stored into the SPICE memory store.
QuickSight is quite impressive. It allows analytics to be performed right on the data sources at AWS. Coming from SAP projects seems like a different world regarding productivity, beginning at the data and following the string to the analytics layer.
Right now, on SAP and Oracle projects, there are massive queues of reports that are waiting to be processed. Moreover, there is one self-evident reason for this. SAP and Oracle’s data warehousing solutions are significantly behind the cloud. For example, SAP Cloud Analytics (supposedly supplanting the visualization application and “Tableau killer” Lumira) is still barely operational, which does not count the data supply chain.
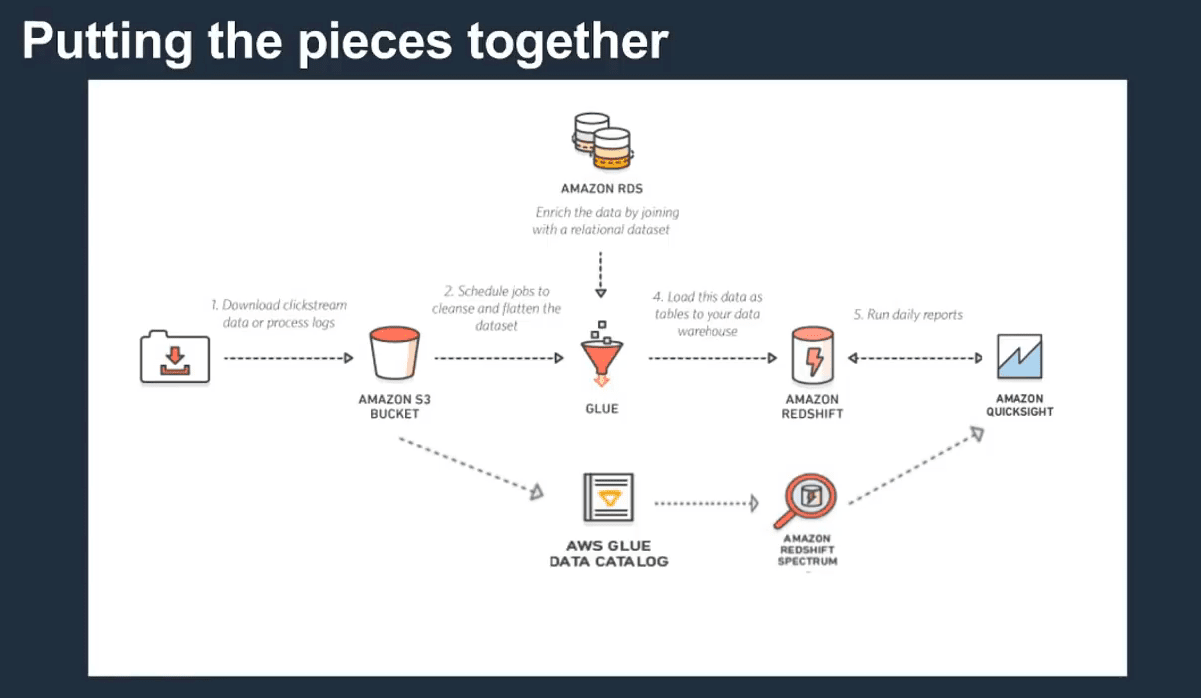
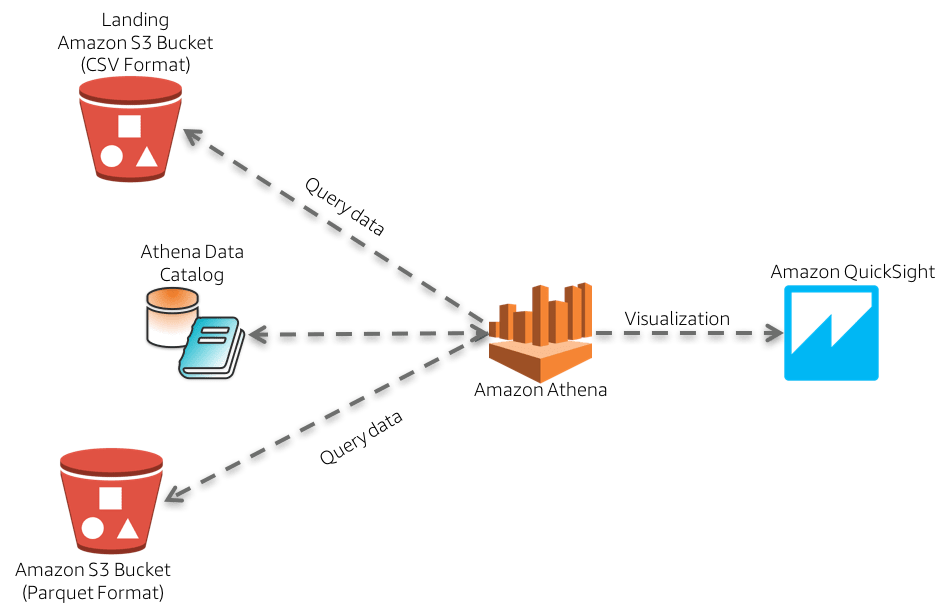
One potential data supply chain for Amazon QuickSight.
Oracle and SAP data warehousing projects have the feel of extreme hierarchy. The users are asked to “wait outside.” While the “priests” or the data mungers and data structure builders do their work inside, dropping a visualization tool onto the environment does not help the overall scenario very much. We have seen many customers with both SAP and Tableau, and the most popular analytics tool is Excel.

The eternal question for users on SAP projects after they pass away.
The Importance of Access to Compute
Companies focused on data warehousing that is not focused on the cloud will face increasing difficulty maintaining the illusion that their approaches are desirable. This is explained in the following quotation from Dan Woods (#2).
“The cloud is the land of cheap storage and on-demand compute. The CDW should radically separate storing data from the engine that does the computation. This will allow as much data as possible to be stored and as many different type of engines as needed to process it to be created. This separation significantly changes the economics of the data warehouse because you don’t have to build a large system to handle your peak storage needs inside an on-premise system.
The of the complexity of a data warehouse is decreased by the cloud’s ability to start up as many different computing engines as needed to handle your workloads. Some of these engines will wake up and stay running, handling on-demand requests or waiting for batch jobs. Others will wake up and process just one workload and then disappear. The point is that each of these engines is created on a separate infrastructure that doesn’t compete with the others. This simplifies the implementation.”
How All of This Applies to Google Cloud
This chapter has discussed AWS; however, this applies similarly to Google Cloud. We showed this table earlier, but Google Cloud has similar data warehouse/data lake ready services.
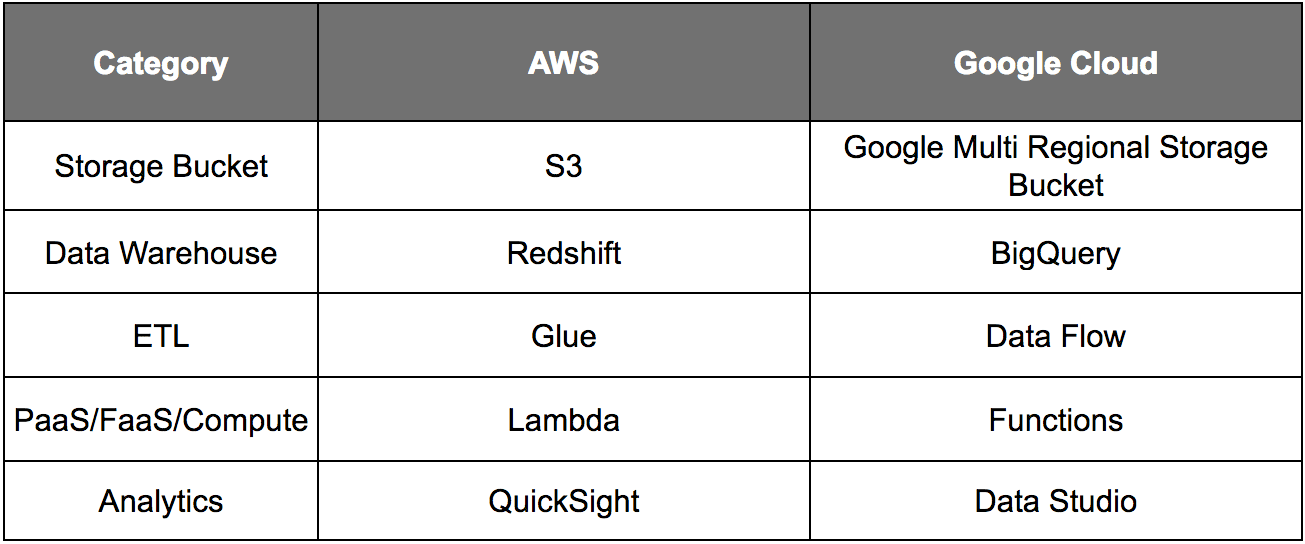
As with AWS, Google Cloud allows a conglomerated approach that flexibly combines a data lake with a data warehouse and can allow for federated queries across a virtual database.
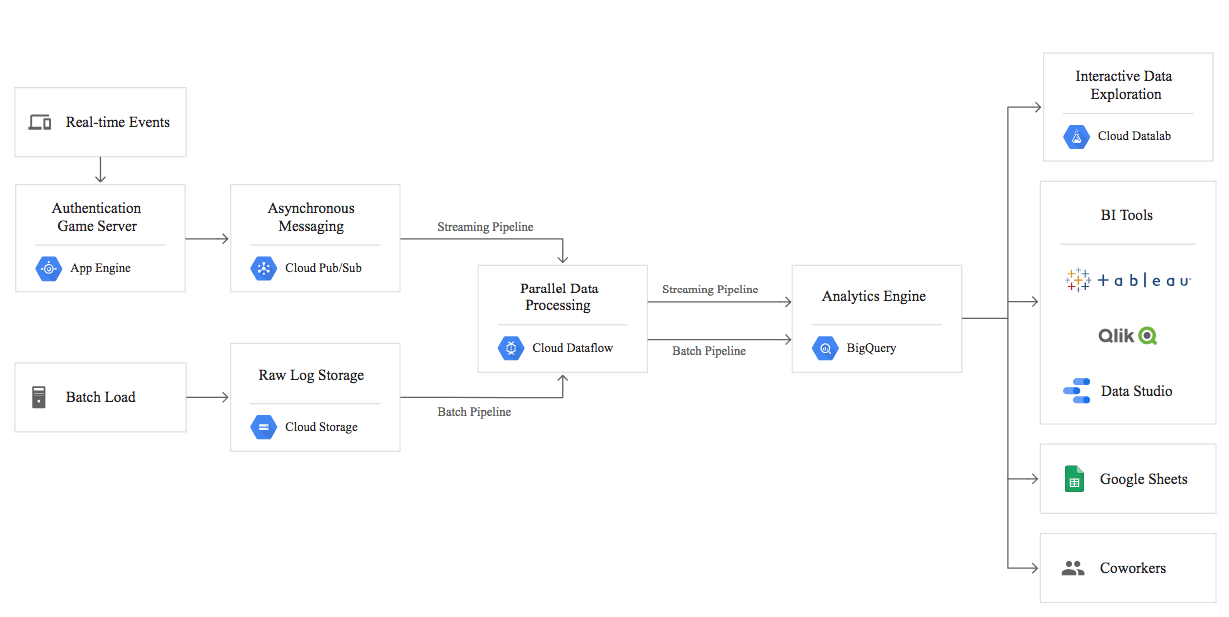
Google Cloud does not have an analytics application that we consider as good as QuickSight, but there are many options.
One of the most interesting data warehousing use cases is not something we would ordinarily consider a data warehousing application as it is such a short time lag use case. This is published on Google Cloud’s website and is a real-time inventory management system. In most cases, inventory management is handled by the ERP system. However, there is nothing to say that an ERP system has to be used for this purpose. ERP systems usually are costly implementations and impose considerable inflexibility upon a company. As we cover in the case studies, ERP systems typically have poor supply chain planning capabilities. An ERP system could be used or not be used with this use case, which is shown in the graphic below.
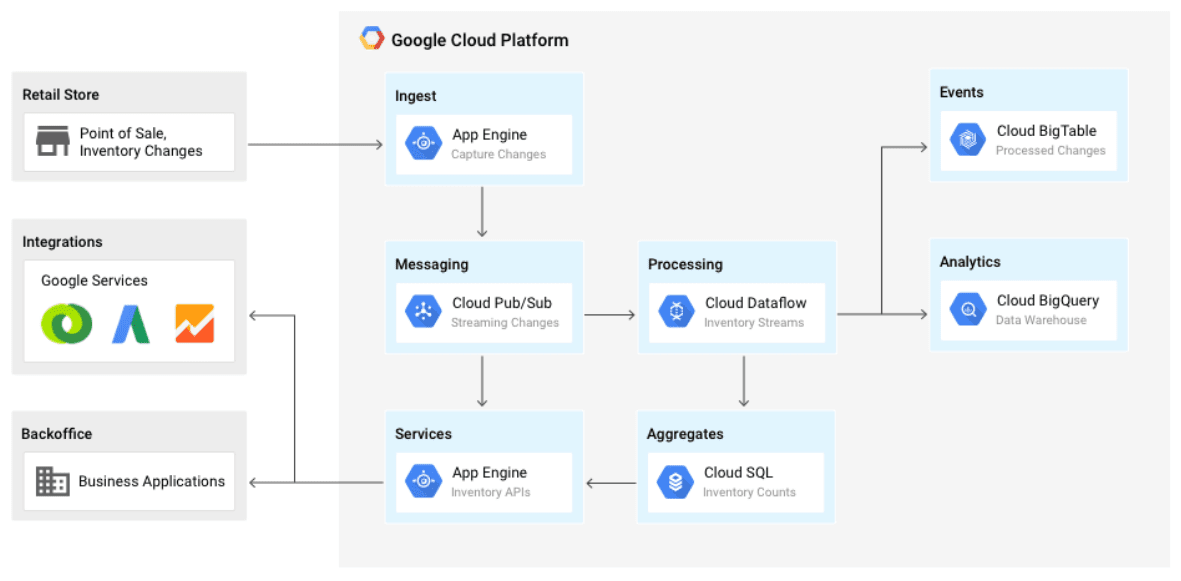
Here the point of sale information comes from retail stores. The current inventory position is held in the back-office applications (which may contain an ERP system). The various Google Cloud components are used to combine retail store point of sale data with back-office applications.
Conclusion
Data warehousing projects are known to be engines of scope creep in companies and deliver far less output than expected at the beginning of the project. This is yet another monolithic approach where an enormous number of data sources are brought together in a single place. SAP and Oracle’s entire concept of a data warehouse is dated. It locks customers into a high overhead and inflexible design that already has ample evidence not to come close to meeting the expectations set for data warehousing. The future of data warehousing is leading away from the approaches and heavy lock-in promoted by SAP and Oracle.
Data warehousing vendors and consulting companies have become accustomed to long-running projects. Again, the final result is not verifiable until a lengthy period has passed and a lot of money has been spent. Once purchased, they prove incredibly sticky, and the vendor sets the agenda in what has been a monolithic design where they stipulate the tools. Everything ends up being around what the vendor decides will be used. However, cloud data warehousing/data laking can be brought up much more quickly. The more savvy customers will leverage this rather than continue to take what the data warehousing industry has been serving up.
AWS and Google Cloud offer the opposite of the traditional data warehousing industry with their high lock-in and long-running projects.

Snowflake obtained a peculiarly high score on Gartner’s ODMS Magic Quadrant. For a vendor that is rated at 119th in overall popularity, it seemed odd. That is until we found how much capital Snowflake had raised (and therefore, it is budget for promotion). Yet if you look at the items it lists on its webpage (Instant Elasticity, Secure Data Sharing, Per Second Pricing, and Multiple Clouds), those are all capabilities already inherent to both AWS and Google Cloud. The market will determine if there is enough value add with Snowflake over the inherent data warehousing capabilities in AWS, Google Cloud, and Azure.
Snowflake was able to raise $450 million in the capital in 2018 alone. And the investors in Snowflake are making a bet that the data warehouse market is ready for an all-cloud provider.
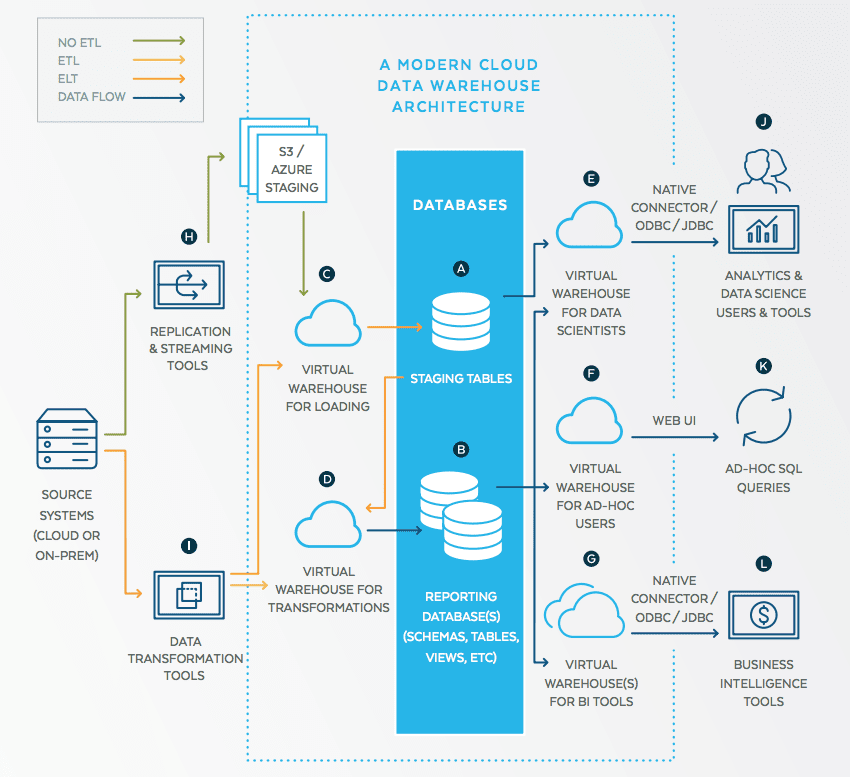
This is Snowflake’s vision of the multicloud data warehouse.