
How Accurate Was John Appleby on HANA Versus DB2?
Executive Summary
- John Appleby made bold predictions on HANA.
- How accurate were his statements around HANA versus DB2?

Introduction
John Appleby’s article on the SAP HANA blog was titled SAP HANA, Oracle 12c in-memory, IBM DB2 BLU – a comparison, and was published July 21, 2014. This article makes enormous claims about HANA, which is what Appleyby’s company, Bluefin Solutions sold consulting services. We review his article for accuracy.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Notice of Lack of Financial Bias: We have no financial ties to SAP or any other entity mentioned in this article.
- This is published by a research entity, not some lowbrow entity that is part of the SAP ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on SAP is provided by SAP, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, SAP pays off all IT analysts -- who have the same concern for accuracy as SAP. Not one of these entities will disclose their pro-SAP financial bias to their readers.
The Quotations
Oracle Produces Propaganda?
“Oracle finally released their in-memory cache for the Oracle 12c database this week. With it, has already come a good quantity of anti-SAP HANA marketing, with the usual jousting that you would expect between enterprise software vendors. They released a comparison sheet between Oracle and SAP HANA, which is the usual mix of propaganda/marketing.
This is compounded because SAP has reseller agreements with Oracle and IBM, so they have to be very careful how they position SAP HANA’s capabilities. I don’t work for SAP, so I don’t have to be careful. Furthermore, I didn’t like the Oracle comparison because it’s very database-centric, and businesses are application and process-centric. Here’s an alternative view on the world.”
This is curious. Because we rank SAP’s marketing as less accurate than Oracle’s. Secondly, SAP has shown no sensitivity to making statements stating that neither IBM nor Oracle can compete with HANA regardless of any reseller agreement. SAP, after all, makes far more if they sell HANA than if they resell IBM or Oracle. Reselling means to markup other databases without adding any value.
The comparison is very database centric and odd, as HANA is a database, and the discussion here is about databases.
Also, it is unclear how much John Appleby did not work for SAP. John Appleby was serving as a proxy for SAP in his statements. Indeed, he does not have to be careful, but that is the point. John Appleby is posing as independent when, in fact, he has a long history of being puppeteered by SAP. And at this time, John Appleby was trying to sell HANA services.
“In the projects I’m working on, we find that the sheer number crunching capability of HANA means that we can solve problems we couldn’t solve in DB2 or Oracle. For instance, we put together a real-time management dashboard for one company; this was based on 34 separate complex questions that displayed in one dashboard. Using the HANA platform, we could get an end-end page load on an iPad in under 3 seconds based on real-time data. There’s no way that this could have been built on DB2 or Oracle – it took 30-40 seconds and that’s not an acceptable response time for a mobile app.”
HANA has no more number crunching capabilities than either DB2 or Oracle. Repeated observations from HANA customers support this conclusion. We covered this topic in the article What is the Actual HANA Performance? Therefore, it is unlikely that what John is saying here is true.
HANA is not a platform; it is a database. Secondly, there is no way that 34 complex questions would take 30 to 40 seconds to load.
First, are all 34 questions appearing on one page? If so, why? See our survey on HANA problems here. Notice how one question is loaded at a time? We have no idea what database is used, but it works great.
Even if 34 questions did take 30 to 40 seconds to load — they would load below the fold, and it would be immaterial to the user. Secondly, most of the load time would be attributed to the server technologies, the images on the web page, etc., not to the database.
The Internet primarily runs MySQL and is fully capable of meeting survey needs without even Oracle or DB2. Companies with a brain would never set this up with either HANA, Oracle, or DB2 today. There are too many better choices.
This is a list of databases by popularity.
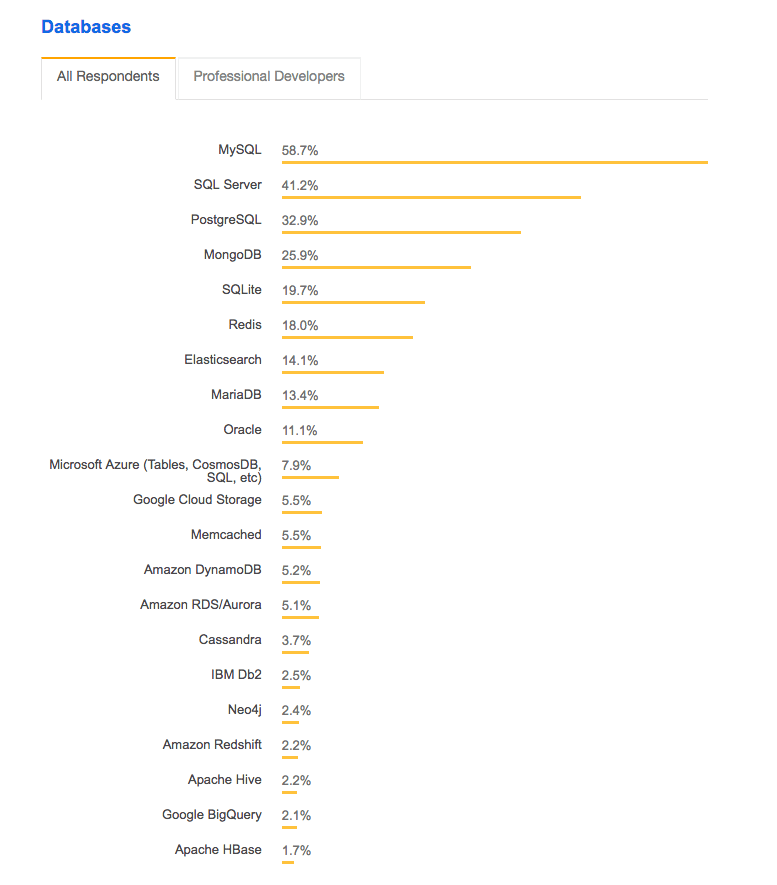
HANA is not even on the list. And secondly, this is not analytics processing. There is no reason for a column-oriented design for this application. Thirdly, SAP is dead in the mobile space.
Why is this company using SAP Mobility? Or are they?

We are barely into the article, and John Appleby already gets a Golden Pinocchio Award for this statement about a form requiring HANA.
Only HANA Can Do What SAP Needs?
“The other thing that is worth noting is SAP’s development direction. I recently spoke to a friend at SAP that put it nicely: “We spent the last 10 years optimizing our products for Oracle and IBM. Now we are spending some time optimizing for our database”. Some customers have commented to me that they feel that SAP is investing overly heavily in R&D for HANA, at the expense of other databases, but I don’t believe that is a fair assessment: HANA enables capabilities that other databases do not, and SAP is writing software to take advantage of these capabilities. If other databases could do the same things then SAP would enable them (and the software has in most cases been written to take this into account), but they can’t do the things that HANA can do.”
This is interesting because there is zero evidence that this is true.
In 2019, HANA still lagged in completing databases in performance. SAP has not published a single HANA benchmark for transaction processing, as we covered the Hidden Issue with the SD HANA Benchmark in the article. SAP will not publish any benchmark for its BW application for any database but HANA, as we covered in the article The Four Hidden Issues with SAP’s BW-EML Benchmark.
HANA is Enterprise Ready?
“Oracle attacks HANA specifically on the topic of enterprise-readiness, but that’s not what we see in the field. In fact HANA is so much easier to configure for High Availability that almost all of my customers use HA/DR scenarios. By contrast, I have almost never come across Oracle RAC, because it’s notoriously difficult to set up. And in a recent customer, we had zero issues during user testing on a complex deployment. Not just zero open issues at the end of testing – not a single issue during user testing.”
Oracle makes this same argument against every competitor, regardless of who they are. According to Oracle, AWS is still not enterprise ready.
But in this case, Oracle is a point. HANA is, even in 2019, highly unstable. In 2014 when this article was written, it was a disaster. We have rated HANA as our highest overhead RDBMS.
Oracle is complicated to set up. But once it is set up, it stays up and is robust. These are two different issues. One is the complexity, and the other is stability, and Oracle is quite stable. SAP, even in 2019, has nowhere close to the upper-end applications that Oracle has.
Appleby is completely misrepresenting the stability and maturity of HANA in these quotes. This is not true in 2019, much less back in 2014.
Oracle and DB2 Need to Catch Up?
“Some customers suggest that Oracle and IBM will catch up – but the reverse seems to be true so far. When I last looked at HANA and DB2 a year ago, SAP were around 2 years of development ahead of IBM, but that seems to have increased in the last year – HANA has become much more mature, and IBM haven’t made any changes since the release of DB2 10.5. We don’t see any SAP on BLU deployments at all or any live customer stories.”
This is only applicable in the addition of the column-oriented data store. In 2014 Oracle and DB2 were behind in this, not that it matters much because the entire goal of adding a column-oriented store to a row-oriented database does not mean much, as we covered in How Accurate with Bloor Research on Oracle In-Memory?
If companies need a pure analytics database, they can use Redis.
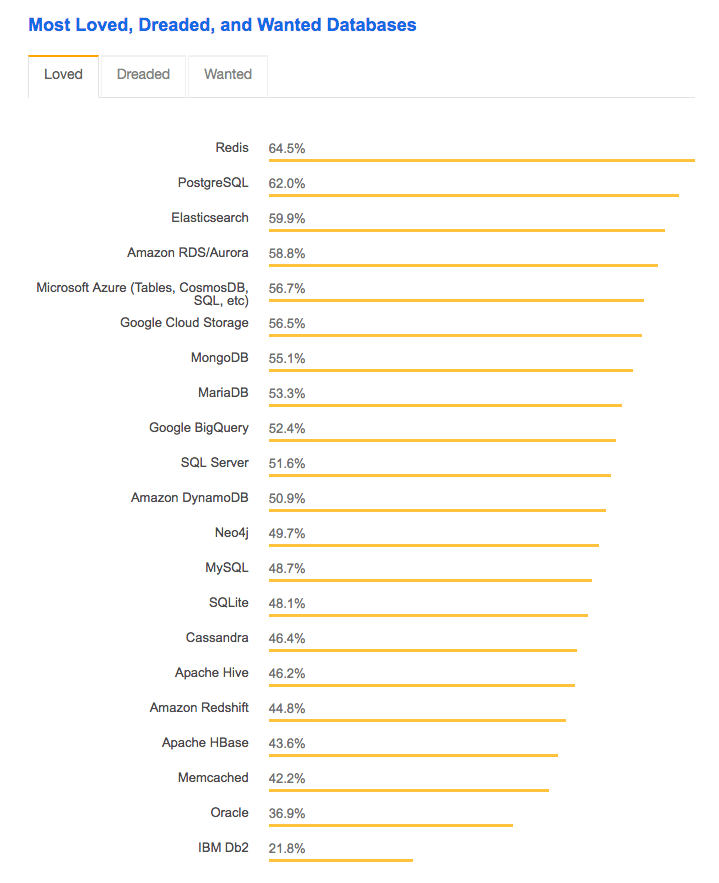
According to Stackflow, Redis is the most loved database. Notice Oracle and DB2, right at the bottom. HANA, once again, is not even listed.
But outside of the column oriented tables, HANA was and is still behind Oracle and DB2 on everything else. So the statement by John is quite misleading.
John Appleby is Not Biased in Favor of SAP?
“Disclosure: I don’t work for SAP and received no compensation for this piece, but I have consulted in the past with SAP on various areas of SAP HANA. Bluefin is a Microsoft, Oracle and SAP Services Partner.”
This is a ridiculous statement. Appleby may have received no compensation in terms of direct payments, but he received some benefit from repeatedly writing articles like this. Appleby was the primary outside of SAP shill at this time.
Can HANA be Made Reasonable in Price?
This comment from Appleby was in response to a comment about HANA being too expensive to use.
“You point out some interesting points, and I see four separate areas where HANA could be improved:
1) License costs. We see a difference between the various options (yours could be 15% of BPC application value) and what is offered initially. It can take a savvy buyer or good consulting partner to get to the right option which gives you the best value.
2) Hardware costs. I’m currently helping a customer negotiate a small hardware appliance (256GB). On the vendors website it should cost $30k for 256GB, but the hardware vendor would like to charge much more. Again, it needs a savvy buyer to get a good price.
3) IaaS costs. Dev+Prod with HANA IaaAs should be $40k per annum for 128GB but many IaaS partners, including HEC, can ask for much more. Again, negotiate.
4) Services costs. Good HANA people are expensive right now, and this can push the services costs up for good advice.
With most of the customers I work with, the numbers are quite big – both in cost, and benefit, and so a sensible conversation can be had all around. For customers looking to “get in” to HANA, this can be a tricky road to navigate. As you know, I hope we can help you navigate through this!”
John Appleby is skirting the issue here. HANA is far more expensive than other expensive options.
Appleby states that…
“Good HANA people are expensive right now, and this can push the price up for good advice.”
When Appleby says good advice, does this mean HANA resources that won’t lie to the account about HANA? Because we have yet to see this HANA resource regardless of the price.
Was the Article HANA Advertising?
A commenter notes that this article seems like advertising.
“This article is more of an advertising of SAP HANA rather than fair assessment of capabilities of all three platforms – SAP HANA, Oracle 12c, IBM DB2 BLU.
All the advantages mentioned here about SAP HANA platform are example of SAP HANA specific optimizations done for SAP applications which are not available for other two platforms.
As an answer to this question “Why not optimize for Oracle/IBM as well?”, what customer gets as answer is that things which HANA does are not possible on Oracle/IBM. Which again points to the interest of SAP that they are not focusing on Oracle/IBM (based on comment of SAP employee mentioned in article).
I think what would be fair assessment is — comparison of SAP HANA/Oracle 12c/IBM DB2 BLU optimized applications from all three SAP/Oracle/IBM.”
And Appleby’s Response
“Certainly, this is an SAP application-centric view of the capabilities of those databases. I think that’s pretty transparent, but there are a lot of customers running SAP applications. And yes, this is absolutely a story about how SAP has optimized their applications with the capabilities of the HANA database.
The key point that is often missed is that SAP spent 30 years optimizing for 3rd party databases (so to say that SAP hasn’t focussed on them makes no sense). Then they wrote a better database themselves and optimized their applications for this. Because HANA is a better database, these apps run far better on HANA.
If it looks like an advertisement, it’s because HANA provides capabilities which the other platforms do not, and perhaps, can not. These are being used to deliver applications that are differentiating on the HANA platform compared to a regular RDMBS.
What you say wouldn’t be a fair assessment, because that scenario doesn’t exist in the real world (in my opinion).”
Engaging, because once again, no field data point supports this. And Appleby makes it appear as if SAP’s only motivation was to improve database performance. It seems that the ability to use their control over applications at a customer to push into the database business and make more money and take more control over the account does not factor into any of Appleby’s comments.
HANA is a Slow OLTP Engine?
Another commenter stated the following.
“In truth HANA is a slow OLTP engine, and only faster for analytics sometimes i.e. when no expense is spared. It also requires extensive recoding that only SAP will bother to do. It has weak SQL support and weak optimization. Outside of SAP space, it is pretty much irrelevant. Inside SAP space it is disappearing fast into the cloud.”
This matches our observations that HANA is slower in transaction processing, which we covered in the article How Accurate Was SAP on HANA Being a Perfect Fit for ERP?
And then another comment.
“Sure, with equivalent hardware and unmodified code it’s much less efficient and slower for OLTP than a row store. The flip side is that analytics is much faster, and that the OLTP performance can be made good enough for most SAP systems by code rewrite and high specification hardware. The beauty of the IBM and Oracle approach however is that neither OLTP nor OLAP performance needs to be compromised, and code does not need to be rewritten.”
This is an excellent point. But HANA is not being marketed as an analytics database. Outside of BW or BPC, HANA was planned to replace most SAP applications using Oracle or DB2.
Appleby’s Response
“I’m really not a big fan of trolling forums with fake names and unspecific content. It would sure be appreciated if you would use your real name.
Honestly, what you describe isn’t what my customers tell me. One thing is for sure – poorly designed custom code does run worse on HANA than on a traditional row-based RDBMS. But what’s fascinating is that most things run much faster, so the poorly designed code stands out like a sore thumb.
I saw this at a customer last week, where to quote “We are delighted with the improvements, and we would like to understand why we don’t see them across the board”. We got into the detail, and found that a consultant had written some poorly-optimized custom SQL. A few clicks later and it improved the performance of that code by 30x.
And to answer the equivalent point, HANA, like other technology, is a series of trade-offs. You trade off “ok” row-level insert performance for outstanding range select performance due to the columnar design. With modern hardware, we tend to find “ok” is around 2x as fast as existing systems. That’s an acceptable trade-off for the ability to do ad-hoc reports that take 5m-5h on traditional row-based RDBMS, into 2-5 seconds on HANA.”
Appleby uses the term trolls frequently to describe people that disagree with him. Notice the exaggerations —
“a few clicks later and it improved the performance of that code by 30x.”
That is the type of statement a salesperson makes rather than an engineer.
Appleby seems to lose the plot by stating that HANA is a series of trade-offs. No. HANA is superior to every other database according to SAP, as we covered in How Accurate Was SAP About HANA Being 100,000x Faster Than Any Other Technology in the World?
Why are these trade-offs appearing all of a sudden? SAP stated that HANA has the best OLAP and OLTP performance combined in one. There are no trade-offs when they describe HANA to prospects.
And being called out by Appleby for being anonymous, the commenter replies.
“Well, I think it’s legitimate not to want to post my name when to do so might conceivably cause problems for me or my employer. Your reply basically agreed with my point anyway, so not sure why you get so pissy.
A customer that I know has implemented HANA on Suite. To date they have observed no speed up in transactional performance. They do hope and expect to see better reporting performance of course, especially once volumes grow enough to show a difference. However I’m not sure that mandating terabytes of RAM and SSD for log files, just to get similar performance to a much cheaper database running on far cheaper hardware, is “OK” for most SAP customers.”
First, this is the problem with commenting. If one works in SAP, one is allowed to agree with SAP. If one disagrees, one must comment anonymously. Appleby knows this, and he is taking advantage of this, but calling out the anonymous commenter, but pretending that he does not know it. If the commenter were to reveal himself, he would likely have to enter comments that are far less confrontational. Appleby does not want to be confronted.
Furthermore, this is precisely what our data points show. And this comment also highlights an SAP strategy, which is to reply to criticisms about HANA’s performance.
HANA Was Not Designed to Substantially Improve Transactional Performance?
Now Appleby responds.
“HANA wasn’t designed to substantially improve transactional performance (we see roughly 2x on average, so that customer should get someone to take a look at what’s going on). 2x is already pretty significant in terms of cost saving in many customers, especially for complex processes.
Instead what you get (out the box) is the ability to run range select queries on the transactional-system. That has huge benefits for operational reporting and batch schedules, and any other queries which hit a large volume of data. I have customers with queries that take 6 hours to run on anyDB that run in a few seconds on HANA.
Also watch out for the changes in HANA in 2014. Most vendors no longer use SSD, they use a pool of regular disks instead. SAP Certified Appliance Hardware for SAP HANA
In terms of memory usage, I put a MSSQL system onto HANA this year, which used a 1TB database server. It now uses 1TB of HANA DB and 1TB of IQ for NLS. With Dynamic Tiering this will go down further and HANA will use less RAM than they had defined for MSSQL.”
Once again, Appleby is back peddling on the SAP claims.
This video has been removed from YouTube by SAP.
In this video, Hasso states that the problem of OLTP and OLAP combined has been solved. Hasso also says that HANA has zero latency. Zero-latency (because everything is stored in memory as we covered in How to Understand the In-Memory Myth) If there is zero latency, performance is infinite, and everything is instantaneous.

SAP’s website alters Hasso’s claims — modifying them to “near zero latency.” Which is it? Zero latency or near zero latency.
Plattner Weighs In
“In sERP the transactional posting of aggregates is removed. any period results can be cached and e.g. reused for comparisons. If someone wants to control that the database is not losing data, a total per g/l account and period, stored in a separate table, will allow the comparison with the line items. The footprint reduction of sERP is currently 75% and will soon be over 85%. in sFIN alone it is already 90-95%.
the partitioning into actual and historical (no changes allowed anymore) will split the data set by 1:4 . the historic data can be placed on different hardware and partitioned in a way that smaller nodes can be used. the historical partitions don’t need a back up more than e.g. once a month.
the great advantage is that the aggregation rules can change any time or multiple different ones can exist in parallel.
all optimizations in the applications for an in-memory database using columnar store should not only work for
HANA but the other hybrid databases (row store + columnar store) as well. The stored procedures have to be translated. there are a few SQL extensions like handling of global positioning data or views on views which are currently not available in all databases. HANA’s unique position is that data is stored only once, either in row store OR in columnar store. that reduces the footprint dramatically and needs only half the number of inserts and updates in comparison to a hybrid store. the first production systems show that the size of the memory for the actual data will the same or less than the in-memory caches in traditional row store databases. the hybrid databases are per definition more complex, need more DRAM and disk store and will consume more CPU capacity.
Most of the biggest performance improvements or first enablement of completely new applications with HANA happened outside of standard sap applications. the HANA website is reporting those achievements. some of these applications were transitions from traditional databases to HANA some new developments.”
Hasso is babbling here. This is a constant problem with Hasso, who makes statements that make it appear that he does not grasp the subject matter’s technical aspects.
What is the Compression Level?
The following commenter questions the compression level of HANA.
“”The footprint reduction of sERP is currently 75% and will soon be over 85%. in sFIN alone it is already 90-95%. The partitioning into actual and historical (no changes allowed anymore) will split the data set by 1:4 . The historical data can be placed on different hardware and partitioned in a way that smaller nodes can be used. the historical partitions don’t need a back up more than e.g. once a month.”
I hope SAP does sufficient efforts to educate the community how all this is done on an operational level once it’s available The big question for me is still, when will everything come together and make the sizing requirements drop significantly as an effect.”
We covered this is in the article The Problems with the Strange Lenovo HANA Benchmark.
Conclusion
This article scores a 2.5 out of 10 for accuracy.