
How Accurate Was John Appleby on a Historical View on HANA?
Executive Summary
- John Appleby made bold predictions on HANA.
- We review how accurate he was in his article on a Historical View on HANA.

Introduction
John Appleby’s article on the SAP HANA blog was titled What is SAP HANA? A Look Through The History Of The Automobile and was published on Dec 27, 2013. We review this article for accuracy.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Notice of Lack of Financial Bias: We have no financial ties to SAP or any other entity mentioned in this article.
- This is published by a research entity, not some lowbrow entity that is part of the SAP ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on SAP is provided by SAP, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, SAP pays off all IT analysts -- who have the same concern for accuracy as SAP. Not one of these entities will disclose their pro-SAP financial bias to their readers.
The Quotations
HANA Is Not Getting All of the Growth it Deserves?
Quite often, I wonder why there aren’t more people using SAP HANA. Don’t get me wrong, it’s SAP’s fastest ever growing product, it has a run rate of $1bn, there are a ton of developers, partners and appliances, and products and customers. I’ve been asked to do a webinar on why SAP HANA is different and it got me thinking.
This is often repeated but is false. The fastest growing product in SAP’s history is R/3/ECC. It is the product that built SAP into the company it is today. Here is HANA’s growth according to DB Engines.
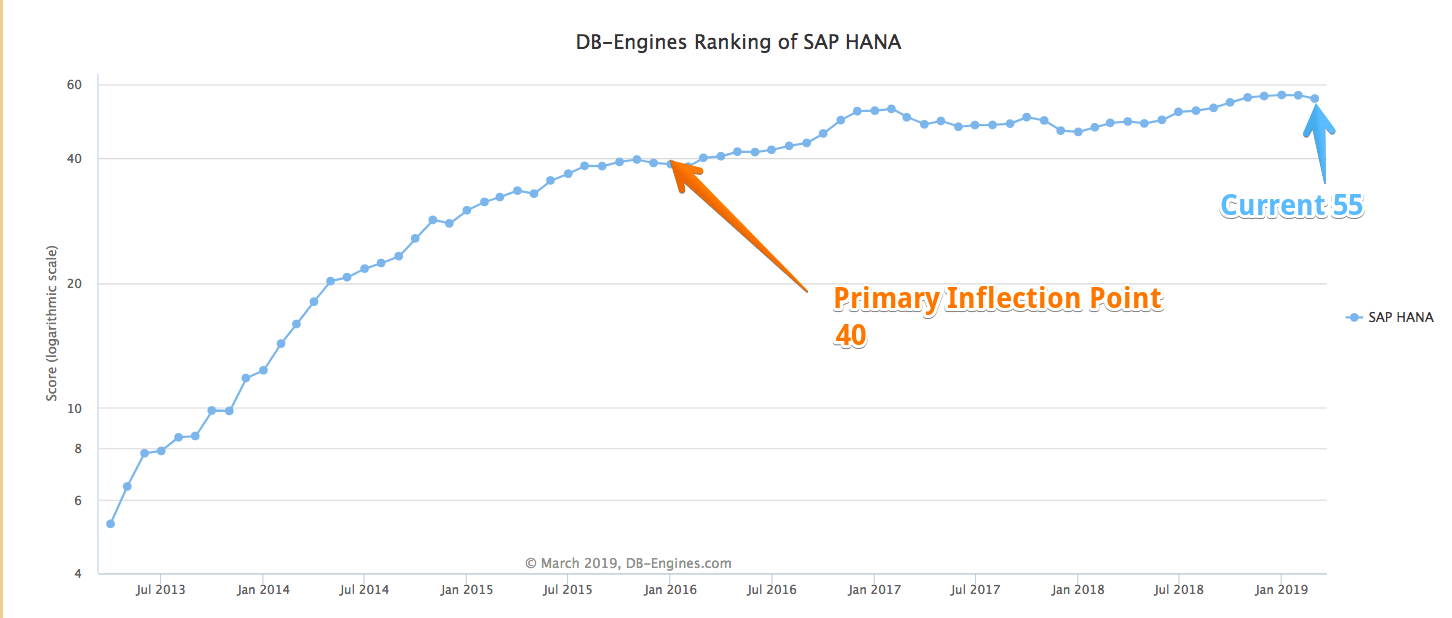
HANA is not only not the fastest product in SAP’s history. It is not even a particularly fast-growing product. HANA’s growth plateaued in 2015, as we covered in Why Did SAP Stop Reporting HANA Numbers After 2015?
If HANA were anywhere close to the fastest growing product in SAP’s history, HANA would have taken the database market by storm, and this question Appleby is asking here would not be asked.
Also, Bill McDermott can’t seem to figure out if S/4HANA or HANA is the fastest growing product in SAP’s history. Neither is, in fact, neither are even close to ECC/R/3’s growth in the 1990s.
Barriers to Mass Adoption?
Do you think that when Henry Ford created Tin Lizzie, he was thinking “great now people will be able to drop down to the Jersey Shore for the weekend”? I suspect that he may have been that forward thinking. He certainly understood the impact of his innovation:
“If I had asked people what they wanted, they would have said faster horses.”
And this is certainly the case with databases. Oracle asked their customers what they wanted, and they built a faster horse, with Exadata. SAP founder Hasso Plattner took a different approach, and built a car, with SAP HANA. This is the problem: there are many barriers to getting mass adoption of a transformational innovation.
The Model T was very quickly adopted.
“Although automobiles had already existed for decades, they were still mostly scarce, expensive, and unreliable at the Model T’s introduction in 1908. Positioned as reliable, easily maintained, mass-market transportation, it was a runaway success. In a matter of days after the release, 15,000 orders were placed.” – Wikipedia
The Model T is still one of the ten most popular automobiles ever sold, and this was in a time with a far smaller overall automotive market, showing the Model T’s dominance. The Model T entirely revolutionized the automotive industry.
Appleby states…
“there are many barriers to getting mass adoption of a transformational innovation.“
Yet, Ford faced no such problem with the Model T. He built a better mousetrap, and he introduced it at a good time. HANA is not a better mousetrap.
So the success of the Model T and what is a copycat database in HANA makes little sense.
However, the second proposal that SAP did much more with HANA than focus on speed is also odd because speed was always HANA’s primary selling point.
There is another major problem with comparing HANA to Model T. The Model T was priced to sell many units, as is explained in this video. Ford did not produce the first car. He produced the first affordable car that had the functionalities that the Model T possessed. This also allowed for mass production. For years, no car company could compete with Ford on price, and one reason they lacked Ford’s economies of scale was that the Model T was more platform than a distinct car.

Model T advertisement. From the collections of The Henry Ford and Ford Motor Company (04/22/08). This advertisement shows just a small number of options that the Model T could be purchased in.

The Model T had an enormous number of variations (truck, sedan, convertible, truck).

The Model T even filled the tractor market.

..and also the tanker truck market.
The Model T’s variants filled every major car category that we have today and more and did it from the Model T platform.
HANA is quite the opposite. It is a costly product, the most expensive database.
The Model T was also a simple design with built-in low maintenance. Once again, HANA is the opposite. HANA is a complicated design with high maintenance. The entities in the database space that match the Model T are the open source vendors, not HANA. Or AWS and GCP, which are focused on continual cost cutting and driving improved efficiencies. HANA is nothing like this; rather, it follows the Oracle model of extracting the most from the customer for the database.
Stables, Stableboys, Ironmongers, and Coachmen
There are entire industries that the car industry destroyed, whilst creating an entire new industry. The same is true with the database industry. There is a whole industry of disk storage, database administrators and performance experts, all keeping traditional RDBMS running. SAP HANA doesn’t need expensive high-end disks, DBAs or tuning.
It does however create industries of high-end RAM production and the build of a whole new collection of business applications, which has the capability stimulate a much bigger growth than the industries which will be cannibalized.
This is a nice try, but it does not fit with what we know about HANA. HANA’s administration overhead is higher than databases like Oracle and DB2 and far higher than a database like SQL Server. HANA resources also bill out at the top of the market, and it also has the most expensive hardware of any database. This entire explanation by Appleby is just false, and he certainly knows this is false.
How HANA helps create new applications is a mystery. First, companies should not be developing with SAP except to the degree they are mandated for customizations. Something else that should be mentioned is that development is not particularly tied to a database. Developers can typically develop an application to work with a variety of databases. That is, there is independence between the two areas that Appleby is meshing together.

Appleby receives a Golden Pinocchio Award for his statements around HANA’s development usage and capabilities.
Roads (i.e., Infrastructure)?
Can you imagine driving your 2013 Ford Focus on the roads of the early 1900s? It wouldn’t last long!
The parallel is true with SAP HANA: despite what some people say, SAP HANA is only OK at running existing applications. You can move your existing large-scale ERP onto SAP HANA, but it will only deliver modest benefits out the box. But just like when the roads started to improve in the 1920s and 1930s, you get massive improvements when you start to optimize your application for SAP HANA.
The roads were quite poor in the early 1900s, but the Model T was a part off-road vehicle and performed quite well in the snow. The Model T did not require a high-quality road network to be utilized. A Ford Focus is designed to drive at much higher speeds, but only on modern roads. Therefore, while the Model T did create the incentive to improve roads, it succeeded, particularly in the beginning, because it did not require entirely new infrastructure. But here, Appleby is essentially asking for a new application “infrastructure” to be created just for HANA.
In addition to Appleby’s comment about redesigned applications for HANA running much better not being true, this puts the application behind in a way, making it subordinate to the database.
Why should companies accept this dynamic? Today’s most important dynamic in application development is microservices, which use specialized databases, rather than one “Swiss Army Knife” database as proposed by SAP, Oracle, IBM, and Microsoft. Appleby is pushing HANA as the basis for new application infrastructure when HANA is a monolithic database.
HANA does make significant dislocations in the applications that work on top of it. But the problem is that it pays off very little even if the application were re-coded to work specifically with HANA.
Also, as HANA is primarily an analytics database, some applications, like BW, require very few adjustments to work with HANA.
SAP and the 100,000x Performance “Club”
SAP has a “100,000x” club, for customers who have improved process efficiency by at least 100,000x, which I’ve always felt was somewhat missing the point. Put in business terms: you can reduce stock-outs, improve predictions of customer demand, reduce the time to close the books and reduce debtor days. And that’s just the start.
The statement made by Bill McDermott that HANA works 100,000 times faster than any competing technology as we covered in the article How Accurate Was SAP About HANA Being 100,000x Faster Than Any Other Technology in the World?
This proposal is both wholly false and is something we routinely have lampooned Bill McDermott for saying. It also shows how untethered Bill McDermott is to any reality. Therefore it is amusing to see Appleby embrace this statement here and demonstrate that, like McDermott, Appleby is just a salesperson.
We are waiting for the evidence that HANA improves anything by 100,000x.
The Horse Itself
There are now around 100m horses in the world, with around 27m in Africa alone, which has far fewer cars per capita. There are now far fewer horses in the western world than there were a century ago, and this no doubt slowed the adoption of cars. A typical horse would last 10-12 years of working life, so why buy a car when you have a perfectly well working horse?
Once again the same applies to the database. There are hundreds of thousands of Oracle, IBM DB2 and Microsoft SQL systems out there, all doing their thing. Why would you want to replace them with SAP HANA, when they work – at least until the infrastructure they are on needs replacing.
The opportunity of new industries
We don’t think anything of going to the shopping mall, filling the car full of shopping, going to the movies and filling up with gas on the way home. All of these industries were created by the car, including motels, drive-thrus, Formula-1, and a hundred other industries.
And this is the tough thing – how do you imagine up a new industry? This is known as the second-order effects of technology, which most often happens by accident. Certainly this is true of my experience with SAP HANA – you have to drive the road and take a leap of faith, to see the value. For instance in Capital Markets, you can run an Order Management System which also provides real-time P&L and Risk Management, on SAP HANA. These are the new industries made possible by technology.
This seems to fall into incoherence.
The central premise that the non-HANA database is like a horse to HANA’s Model T is inaccurate because HANA underperforms all of the databases that it is compared to. And SAP is hiding HANA from competitive benchmarking that would demonstrate anything that Appleby claims is true, as we covered in the article The Four Hidden Issues with SAP’s BW-EML Benchmark.
Appleby shows a distinct lack of interest in supporting claims and an outsized interest in making statements based upon claims.
Why is SAP HANA the Car Rather than a Faster Horse?
This is the hardest question to answer, and it’s one that I feel technology leaders like and Vishal Sikka also struggle with. I know that I do, and it is extremely difficult to explain new paradigms in a clear and consistent way. I believe there are three important dimensions:
First, SAP HANA is an application platform and not a database. It contains a database, and a number of additional engines including text, sentiment and search, mathematics and predictives, spatial and graph, ETL and streaming, plus application and integration services. You can build everything in one place where other platforms would need 10-15 different components and systems.
Second, SAP HANA is very fast, and this means you only need to store information once and then you can present it in any format or aggregation on demand. Because of this, you can use all of the functions above, on the same data set. This causes a dramatic simplification.
Third, because SAP HANA is a very fast platform with a lot of functionality, you build business applications that you couldn’t imagine. As a retailer you can predict product demand based on social sentiment, and automate distribution to reduce stock-outs, based on what is selling right this second and weather data. This is the second-order effect of technology.
Each of these proposals is false. HANA is a database, not a platform. HANA is slower than competing databases and has much less stability than the competing databases. HANA does not enable development more than any other database, and secondly, development and databases are separate from one another. Any developer should be able to develop code for different databases.
Comment by Hasso Plattner
“The ideas for what later became HANA were developed with an application perspective. how would a new enterprise software suite look like, if we only had a database with zero response time, was the research topic. quickly we came to the assumption that all redundant data structures like aggregates, duplicate tables with different sorting sequences, secondary indices for faster access to sets could be replaced by expressions using sql with extensions for analytics and other reusable functions. the first test programs showed a dramatic reduction in complexity. with views on top of other views and the introduction of data structures for hierarchies nearly all known reporting replaced. other mathematical concepts as predictive analytics, cluster analysis, planning functions were added. the closest thing to a database with near to zero response time was an in memory database. the main reason for dividing databases into ones for OLTP and others for OLAP – write versus read performance – disappeared on the drawing board.”
HANA is not any faster than any of the competing databases and does not have zero response time or anywhere near to it.
Removal of aggregates, duplicates, or secondary indices does not speed HANA or reduce complexity. Did we cover the complexity topic in the article How Much Has HANA Really Been Simplified? The rest of the quote is nonsense, as Hasso essentially demonstrates how little he knows about databases.
“We were lucky and got two prototypes from sap: P*time for row store and Terex for columnar store. we ask SAP to implement dynamic parallelism for the columnar store and as a result experienced unprecedented performance for complex queries.”
This is false. Both P*time and TREX were purchased around a year before Hasso stated that work began on HANA. These are never mentioned as acquisitions, and their history is explained in the article Did Hasso Plattner and His Ph.D. Students Invent HANA?
After his portion of the quote is more Hasso Plattner nonsense. And then he finishes with this.
“Yes, the performance is impressive, the reduction of the data footprint valuable but the most important achievement is the reduction in program complexity.”
The data footprint of databases is not relevant to companies, except to those that pay per GB for their databases, as HANA is priced. A reduced data footprint also has little to do with program complexity. Hasso Plattner lacks a sufficient understanding of either databases or programming to be in this discussion.
And these types of statements illustrated how little Hasso knows. Hasso’s comments in this area are quite robotic. Without an authentic understanding of the subject, he routinely falls back into making the same illogical claims.
Appleby’s Response
“Hi Hasso,
I couldn’t agree more. I recently did some research to look at the effects of trying to build apps on several traditional RDBMS, that encompass transactions, analytics and higher-order functionality like predictive and spatial. What we found was both interesting and shocking: even in 2013 it is impossible to build a DBMS app which combines both transactions and analytics, let alone higher order functionality. To get good analytic performance, you have to create indexes and aggregates, and these destroy insert performance and create massive load and duplication.”
Hasso made nonsensical assertions, and of course, Appleby agrees. As we pointed out, Appleby was still a shill for SAP, presents at SAP conferences, and most likely jointly coordinated his posts and sent them for approval to SAP before publishing them.
Let us review the definition of a shill.
“In marketing, shills are often employed to assume the air of satisfied customers and give testimonials to the merits of a given product. This type of shilling is illegal in some jurisdictions, but almost impossible to detect. It may be considered a form of unjust enrichment or unfair competition, as in California’s Business & Professions Code § 17200, which prohibits any “unfair or fraudulent business act or practice and unfair, deceptive, untrue or misleading advertising“.[7]In marketing, shills are often employed to assume the air of satisfied customers and give testimonials to the merits of a given product. This type of shilling is illegal in some jurisdictions, but almost impossible to detect. It may be considered a form of unjust enrichment or unfair competition, as in California’s Business & Professions Code § 17200, which prohibits any “unfair or fraudulent business act or practice and unfair, deceptive, untrue or misleading advertising“.[7] ” – Wikipedia
Yes, this is entirely accurate.
Hasso Plattner is directing Appleby, so if Hasso stated the moon was made of cheese, Appleby would also agree.
This quotation from Appleby is extremely odd — Appleby again sets up a comparison that HANA is entirely different from the databases it competes against.
Let us review the timeline.

Notice that Oracle added column store functionality in July of 2013 (6 months before this article is written), but in memory did not arrive until July 2104, or 6 months after this article is written. Therefore if the requirement is for the database to have both column store and “in memory,” then Appleby is correct. However, even in 2019, there is still little benefit to having a dual mode database. Nearly all of the HANA implementations that added any value at companies were implemented for BW, which does not require a dual mode database, and works just as well with a pure OLAP database.
Even if we push the date to July 1, 2014, for full in combined OLAP/OLTP for Oracle, Appleby, and SAP are asking for companies to decommission their current Oracle and DB2 databases, that were superior to HANA in every way but the “in memory” functionality to gain six months for Oracle and one year for DB2?
Secondly, we are quite confident that Appleby did not perform this testing because, in every other article of Appleby’s that publishes a test, the test is incomplete, a false comparison, or in some way inaccurate. We covered this in the article How Accurate Was John Appleby on HANA Not Working Fast for OLTP? Appleby lacks the ability or interest in testing anything because he simply wants to prove that HANA is the best at whatever the topic of interest is. Secondly, he has a massive undeclared financial bias to promote SAP.
If anything that Appleby said was true, HANA would not lose in performance to the competing databases.
“To do this, even with the latest traditional RDMBS and hardware, you must create layers of complexity to work around this, like separating out transactions, analytics, predictive and spatial analysis into separate databases.
With HANA, we found we could easily build a single system, storing atomic information and using it on demand for transactional, analytic, predictive and spatial. We spent no time massaging database performance or building artifacts to try to improve performance (but which actually destroy performance).”
That is not at all the model of the monolithic database vendors like Oracle, IBM, and Microsoft. We recommend that we cover the approach in the article How to Understand the AWS Multibase Versus HANA.
Like SAP, Oracle, IBM, and Microsoft tell companies they can meet all of their needs from a single database type. HANA loses performance testing against other monolithic databases and aggressively loses both in cost terms and performance terms against specialized databases. These specialized databases like Redis or DynamoDB combined with another open source, row-oriented databases like MariaDB or PostgreSQL not only handily beat HANA in performance, but the costs are meager.
“What surprises me is that the traditional RDBMS vendors have not (in my opinion) understand a word of what you have been saying for the last three years, and are instead building faster horses with saddlebags, coaches and bigger whips. SAP should be very thankful for this, although those vendors do have formidable sales and marketing teams that have stables continuing to sell their “new, faster horses” all over the world and trying to convince customers that the car is a fad.”
Appleby spent the past three years before this article, and years after this, primarily lying about what HANA can do. Secondly, both SAP and Appleby know far less about databases than the “traditional” database vendors. Therefore there is very little reason for any database vendor to listen to Appleby. Secondly, this comparison of databases like Oracle and DB2 as faster horses to HANA as a car is entirely false.

Appleby receives a second Golden Pinocchio Award for comparing other better databases to faster horses and HANA to a car.
“I write these essays to improve my own communication style and to create a clearer message. It’s by writing that I clear my mind, clarify thoughts, and get feedback. Your simplicity point is important though, and one thing I learnt from Steve Lucas this year is that most people can only consume information in “threes or fives”.”
Appleby writes, for one reason, to increase sales of HANA services for Bluefin Solutions. His articles never become more clear because his articles are virtually entirely based upon false statements. And if you are learning something from Steve Lucas, who we have recorded as having some of the least informed comments from any executive who ever worked as SAP, then we would suggest that you find someone of substance from which to take pointers. But this shows the necessity of Appleby to show deference to SAP executives.
Conclusion
This article receives a 0 out of 10 for accuracy. It is not only it is littered with typical Appleby inaccuracies, but the comparison of HANA to the Model T is not only wrong, but HANA is also actually the opposite of the Model T in nearly every dimension. It is difficult to see how Appleby could have found a more ironic point of comparison for HANA.