
The Four Hidden Issues with SAP’s HANA Analytics Benchmark
Executive Summary
- SAP developed a new benchmark to make HANA look good.
- We cover the problems with creating a benchmark for BW.

Introduction
After SAP HANA was released in 2011, SAP created the BW-EML benchmark (renamed the BWAML) and the BWH benchmark. Both of these benchmarks were for SAP’s BW application. SAP published no HANA benchmarks for any other SAP application since 2011. The question one might want to ask is why. You will learn about the hidden issues with SAP’s HANA benchmarks, such as hidden benchmarks, how SAP is giving itself awards in its benchmarks, how SAP proposes no more OLAP structures will be used, and partial SAP benchmarks.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Notice of Lack of Financial Bias: We have no financial ties to SAP or any other entity mentioned in this article.
- This is published by a research entity, not some lowbrow entity that is part of the SAP ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on SAP is provided by SAP, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, SAP pays off all IT analysts -- who have the same concern for accuracy as SAP. Not one of these entities will disclose their pro-SAP financial bias to their readers.
The Setup of the BW Benchmark for HANA
SAP describes the BW-EML benchmark as follows.
“To ensure that the database can efficiently use both InfoCubes and DataStore Objects (DSOs) for reporting, the data model for the BW-EML benchmark consists of three InfoCubes and seven DSOs, each of which contain the data produced in one specific year. The three InfoCubes contain the same data (from the last three years) as the corresponding DSOs. Both object types include the same set of fields. The InfoCubes include a full set of 16 dimensions, which comprise 63 chHidden Issue #2: aracteristics, with cardinali-ties of up to 1 million values and one complex hierarchy. To simulate typical customer data models, the InfoCube is made up of 30 key figures, includ-ing those that require exception aggregation. In the data model of the DSOs, the high-cardinality characteristics are defined as key members, while other characteristics are modeled as part of the data members“
The first problem with this benchmark is what is unsaid. This is brought up by Oracle.
“SAP is now promoting HANA as the database of choice for their applications and clearly has a conflict of interest when it comes to certifying benchmark results that show better performance than HANA. Of the 28 SAP standard application benchmarks, SAP has chosen to only publish results for HANA on the BW-EML benchmark (emphasis added).”
Hidden Issue #1: How About the Missing Benchmarks?
SAP simply does not mention that there are missing benchmarks, and after all the exaggerations on HANA, SAP has chosen to publish just one benchmark.
Why?
The one benchmark they can get HANA to perform well. SAP has a policy of hiding any benchmark for HANA that it can’t perform well, which is why you don’t have the entity performing the benchmark with a horse in the benchmark race.
Hidden Issue #2: SAP Crowning HANA, i.e. Contestant + Judge = Unbiased Outcomes?
Yes, this should go without saying, but you cannot be both a contestant and be a judge.

What would happen if, say Miss Hawaii was also the only judge in a beauty pageant? Who, under those circumstances, would be most likely to win the show? Is there perhaps some reason we don’t allow competitors to also judge competitions? This requires much research with the best minds working on it.
Yet note that SAP has a different view.
“To help the market easily and quickly make these judgments, SAP offers standard application benchmarks. When used consistently, these benchmarks provide impartial, measurement-based ratings of standard SAP applications in different configurations with regard to operating system, database, or hardware, for example. Decision makers trust these benchmarks to provide unbiased information about product performance.”
A Problem With Translating the Word “Unbiased” into German?
Interesting. SAP might want to look up the term “unbiased” in the dictionary, as it is not translating correctly into German. Either that or SAP is saying something entirely inaccurate in this quote. But I looked up unbiased in Google translator to German and came up with the word.
“Unvoreingenommen”
I then found these synonyms in the German-English dictionary.
“dispassionately {adv} [impartially] impartial {adj}
candid {adj}
dispassionate {adj}
unprejudiced {adj}
detached {adj} [impartial] impartially {adv}
nonpartisan {adj}
unbiassed {adj} [spv., especially Br.] unjaundiced {adj}
fair-minded {adj}
open-minded {adj}
without bias {adj}”
So translation does not seem to be the problem.
This is just the first of the hidden issues with this benchmark.
But let us get to the second hidden issue, which is the inconsistency between InfoCubes or cubes and a column-oriented database.
Hidden Issue #3: Why Are InfoCubes Still Being Used for A Database with Column Oriented Capabilities?
I have been working on SAP DP projects for over a decade. DP uses the same data administration area as does BW. Except DP runs forecasting and has a forecasting front end on top of the data backend. HANA is supposed to eliminate cubes’ need, as cubes are aggregation devices used for performance based upon a row-oriented DB.
But in the BW-EML benchmark, cubes are still used, as we can see from the quote above.
Why?
Because companies don’t want to decompose the cubes they already built for the pre-column-oriented design? Quite possibly, yes, as companies will still be using the cubes they created for many years. Much of BW is made obsolete by putting it on top of a column-oriented design capable DB.
Nowhere in any of the BW-EML benchmark does it point out that a primary benefit of a column-oriented design the obsolescence of cubes.
Hidden Issue #4: The Problem with Benchmarking an Incompetent Application
How important is such benchmarking on BW in the first place? I ask because I perform forecast testing for full production data sets for clients on a laptop.
I have a best of breed forecasting application that handles hierarchies far better than DP. I can do things on the laptop with my inexpensive application that no customer I have ever seen can do in DP. Neither DP nor other forecasting applications do the type of forecast error measurement we want, so we created the Brightwork Explorer, which we cover in How to Access Monetary Forecast Error Calculation. We put this on AWS and can apply any number of resources to it, making benchmarking studies like the BW-EML of little relevance.
- The Brightwork “Hardware”: I have a decently powered laptop, and it is all that I need to run the forecasting application. We would have liked to have purchased a more powerful one, but we were under time pressure as we were performing testing, and an unfortunate Windows 10 install screwed up our previous laptop for a while. Therefore we went with a reasonably well-powered laptop that was available for purchase at a Costco across the street from our client at the time.
- Why A Laptop is Just Fine: While I certainly could, I don’t even worry about buying a desktop, and I perform repetitive testing with this setup. This means that I perform much more processing than a typical client because they usually do not perform testing but run the forecast weekly. However, I perform forecast simulation (that is, repeatedly performing forecasting jobs, but without passing them to a receiving system). This means that the load is far higher than the production server receives at my clients.
All of this illustrates the other problem with benchmarking. If the application is incompetently written and highly inefficient with managing resources like DP or BW, database benchmarking becomes a bit of a lost cause because BW and DP will consume so much of the hardware and database processing capacity while it flails about. With these bad applications, one of the primary answers is to apply giant resources to them simply.
We have not once heard this topic raised because neither SAP nor Oracle nor IBM is interested in critiquing the application. Why? Well, their job is to sell databases to support the SAP application. The quality of the SAP application’s code is irrelevant to what they want to bring across. Customers have already decided to buy an awful application; now, the only question is what database and hardware you want to power your awful application.
I am not aware of what tricks the developer of the application I have used to make everything run so quickly and smoothly to make such flexible hierarchies. All I was told was that they put special attention to how the star schema was created, which SAP did not, and which has been confirmed by conversations by other developers familiar with BW and DP.
Oh….this application I use was developed by a single developer. That had probably changed by now as the company had grown over time from when I first used it, but just one developer developed the application I used. And he ran circles around SAP’s large team of developers.
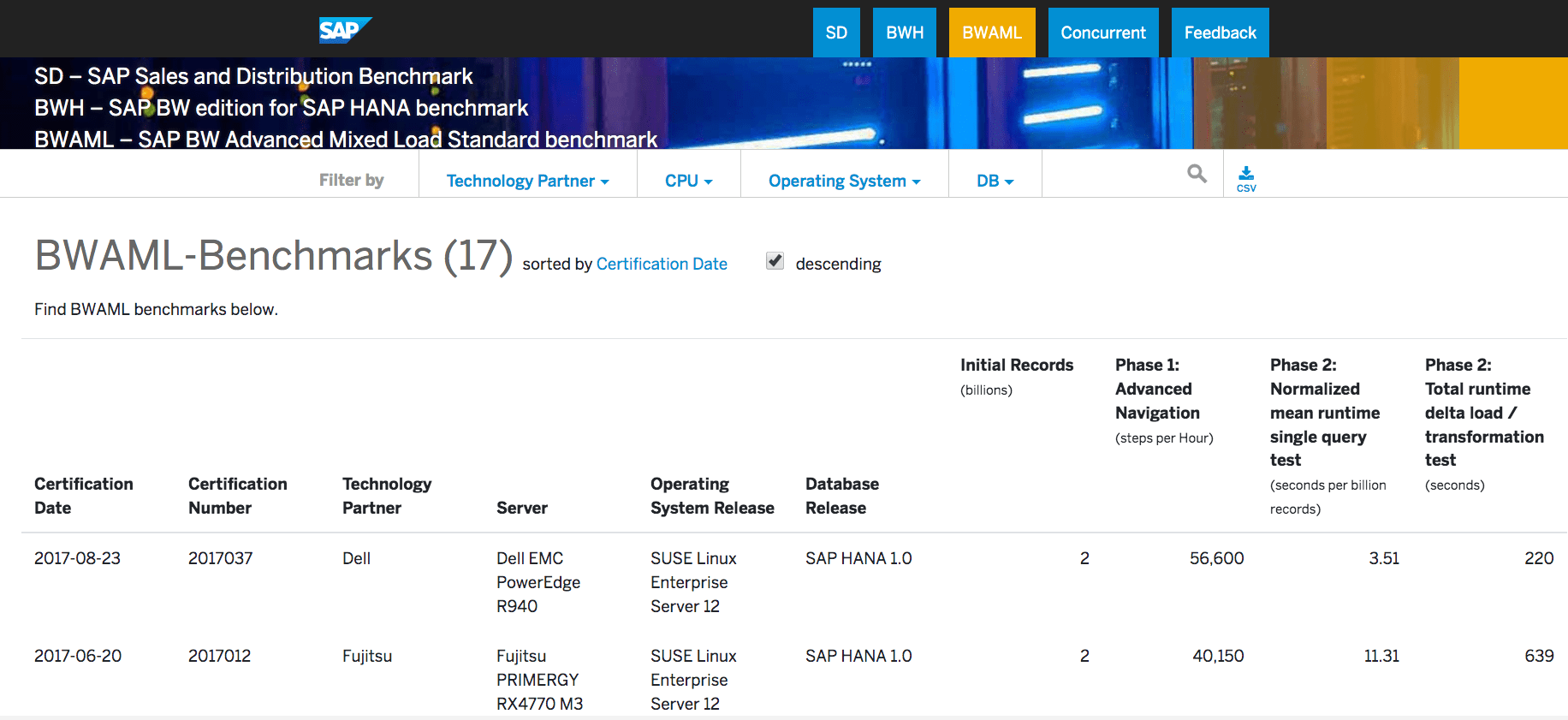
The BW-EML benchmark has since been renamed to the BWAML. There are 17 benchmarks here, and the only database that is benchmarked is HANA.
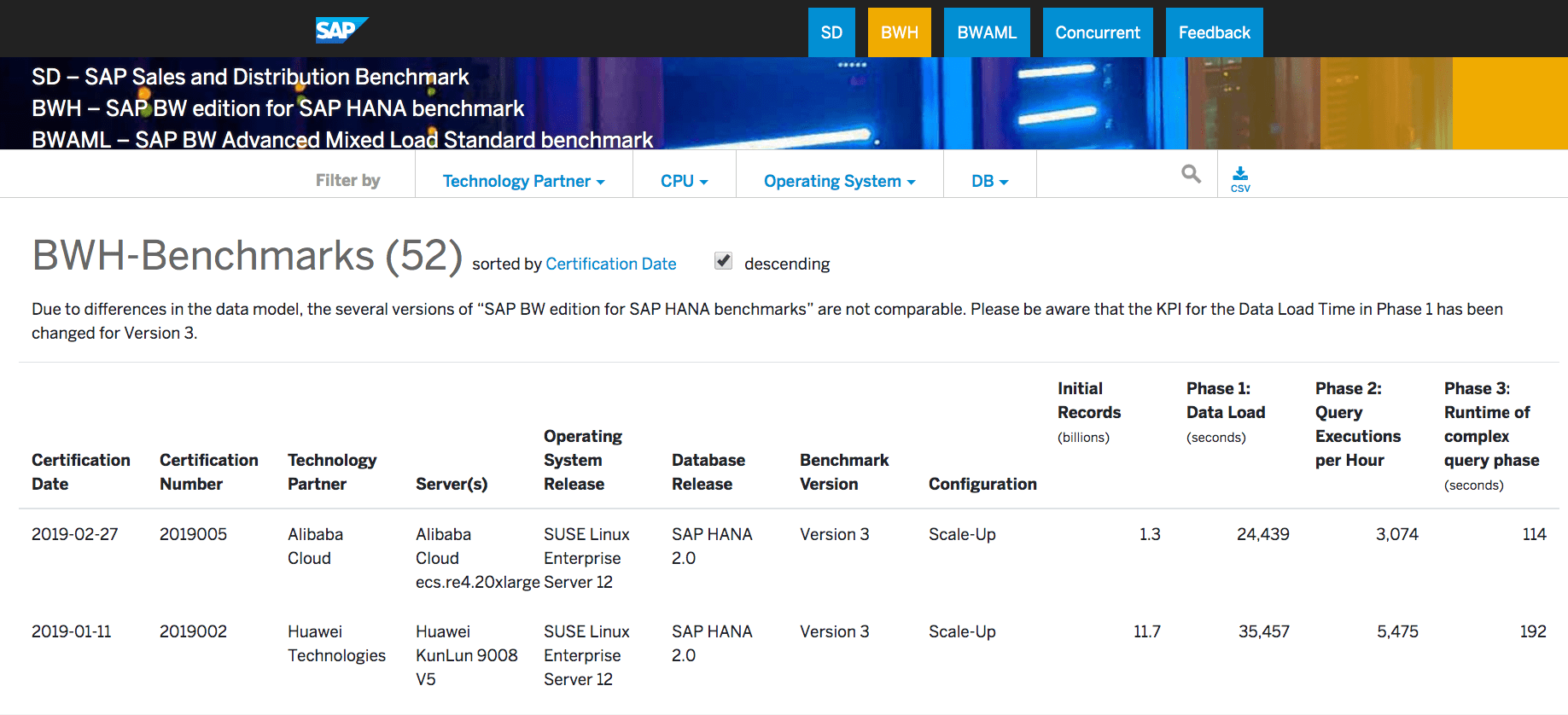
The second BW benchmark is called the BWH. There are 52 of these published at SAP’s benchmark site. The same issue applies. The only database that is benchmarked is HANA. The other database vendors have been excluded from this benchmark.
BW is the only application that SAP has benchmarked HANA for. Both the BWAML and the BWH are BW benchmarks. SAP has refused to benchmark ECC on HANA or S/4HANA on HANA, which we cover in the article The Hidden Issue with the SD HANA Benchmarks.
Conclusion
Benchmarking can’t be interpreted in a vacuum, but it usually is. The issues specific to the BW-BML benchmark that we pointed out in this article are the following:
- BW and DP are exceptionally poorly designed data warehouses (DP’s backend is BW) that consume large amounts of computing resources.
- Many decision-makers may read this benchmark without because BW and DP are both inefficient resource consumers. If a more efficient data application were used, the database and hardware would not have to be overpowered.
- In testing against far less expensive applications, BW and DP lose, even when given far more resources to work with. Again, my comparisons have been using a consumer grade but a reasonably powerful laptop and beating a server that my clients were told by SAP that they needed to buy. The Brightwork “hardware” for forecast testing fits in a bag.
- SAP serves as both a contestant and a judge in its benchmarks, where HANA is set up as the winner before the competition begins.
- None of the database vendors competing have any interest in the performance of the application versus other applications. They are there to sell databases.
- It is improbable that we could get SAP to certify our benchmarking, showing how inefficient BW and DP are versus other similar applications. SAP customers we have had as clients cannot be told that BW and DP are bad applications, so we are required to tiptoe around the issue not to make them feel bad about their poor investments. The primary benchmark in any IT environment is how good the IT department can be made to look. All other benchmarks are secondary to this primary benchmark.
The Broader Issues with Application and Database Benchmarking
There is no independent benchmarking entity for applications or for databases that exist in the enterprise software space. (Some might point to the TCP, but they are a benchmark specification setting entity, not a benchmarking entity).
- Each participant runs and publishes benchmarks only to increase sales of their items.
- Every entity that runs a benchmark ends up, in a rather peculiar way, winning that benchmark. (surprise surprise)
- Independent benchmarks are also dissuaded. Oracle demanded that an independent benchmarker be fired for publishing a benchmark that showed Oracle performing poorly. (The case of DeWitt — see footnote)
- The commercial database vendors have clauses in their licenses that prevent independent companies from publishing benchmarks.
- Open source databases do not have these clauses.
Overall, there are multiple dimensions to presenting the BW-EML/BWAML benchmark by SAP that hide information from the reader. Such as the fact that SAP did not release the benchmarks in which HANA could not perform well. HANA was supposed to perform 100,000 times faster than any competing database (McDermott), as we covered in How Accurate Was SAP About HANA Being 100,000x Faster Than Any Other Database. It was supposed to reduce the workday to (roughly six seconds) (Lucas) How Accurate Was SAP About HANA Enabling People to Work 10 to 10,000 Times. Yet when it came to proving these claims, SAP has had to rig its benchmarks to keep HANA from being compared to any other database. SAP often uses the term “AnyDB.” But perhaps the right explanation of SAP’s behavior is that SAP fears any objective comparison to “AnyDB,” or should just say the comparison to any DB.
“Coming Up with Solutions……Not Just Problems”
After publishing an article like this, readers sometimes ask that we come up with solutions rather than merely analyzing unpublished issues elsewhere.
Here the lesson should be straightforward enough.
IT departments should not take the word of SAP or SAP’s consulting ecosystem on the performance or other characteristics of HANA or any other item without evidence. The lesson for any business users that read this article is that IT departments that purchased and implemented HANA never looked for any evidence that HANA could meet the claims made by HANA. SAP conveniently skirted the issue and rigged their benchmarks to prevent HANA from being compared to any other database specifically. No IT media or IT analyst ever called them out for this deception. No company that purchased HANA ever bothered to check, preferring to base their purchase on the claims of SAP and their compliant consulting ecosystem. If these companies had done their research, it is unlikely they would have gone forward with HANA’s purchase. We say this repeatedly to clients that we advise on SAP. Whatever the SAP sales rep says is only a starting point. Everything stated by SAP must be fact-checked. And there is no reason to assume that something SAP says is true.