
John Appleby, Beaten by Chris Eaton in Debate and Required Saving by Hasso Plattner
Executive Summary
- John Appleby made bold predictions on HANA.
- We review how Chris Eaton severely beat him in a debate on HANA.

Introduction
John Appleby’s article on the SAP HANA blog was titled What In-Memory Database for SAP BW? A Comparison of the Major Vendors and was published on Nov 13, 2013. In this article’s comments section, let us see how Appleby fared against Chris Eaton of IBM in defending his claims.
Our References for This Article
If you want to see our references for this article and other related Brightwork articles, see this link.
Notice of Lack of Financial Bias: We have no financial ties to SAP or any other entity mentioned in this article.
- This is published by a research entity, not some lowbrow entity that is part of the SAP ecosystem.
- Second, no one paid for this article to be written, and it is not pretending to inform you while being rigged to sell you software or consulting services. Unlike nearly every other article you will find from Google on this topic, it has had no input from any company's marketing or sales department. As you are reading this article, consider how rare this is. The vast majority of information on the Internet on SAP is provided by SAP, which is filled with false claims and sleazy consulting companies and SAP consultants who will tell any lie for personal benefit. Furthermore, SAP pays off all IT analysts -- who have the same concern for accuracy as SAP. Not one of these entities will disclose their pro-SAP financial bias to their readers.
The Quotations
Comments by Chris Eaton of IBM
“You make a claim that there is a 1TB limit on BLU. That is not the case. Perhaps you are getting this from our beta program where in fact we asked clients to initially limit their testing to 10TB of data (not 1TB) but at the end of that program we tested with clients of 100TB and in the GA version there is no hard limit on BLU tables. In fact IBM has a sizing guide for clients that helps clients size their system. The guide actually has recommendations from the smallest systems up to 100TB and guidance for beyond that. One thing I find curious in your HANA column is that you list 500TB raw and 100TB compressed. Does that mean HANA only has 5x compression? Also on the Enterprise Readiness section there are solutions today with BLU for HA and DR that keep the column organized tables fully available after a failure of the primary server (without the need to rebuild anything). And as you have noted, IBM is not standing still and is improving this story even further as we speak. In fact if you look at enterprise readiness it is of course more than just HA and DR. It typically encompasses transparent encryption, separation of duties, workload management, minimizing downtime, rolling patches and much much more…that’s exactly why IBM put BLU in the already enterprise robust DB2.
Now on to perhaps conjecture rather than fact, I’m surprised that you list “Maintenance is reduced” under HANA but I guess you mean data movement because I’m shocked to be honest at the number of patches (which I call maintenance) and the number of outrages (Chris means “outages”) required to apply those patches compared to BLU which follows the regular IBM fixpack cycles for DB2.
On the availability you bring up a very good point. But you may not be aware that in fact the technical certification work is complete. In fact IBM did some work to optimize BLU for BW and shipped those optimizations in FP1. These optimizations were actually developed jointly between IBM and SAP engineers so that our joint clients could benefit from the combined value. In fact SAP has added capabilities in the DBA cockpit and in BW itself to exploit BLU. So all of the technical work is complete and passed with flying colours (as I understand it) and both sides know that the products work together because both sides worked together to make sure that was the case for our mutual clients (as our joint clients expect us both to continue to do). And yet for some reason the official OSS Note has not been published. I’m left wondering why SAP is arbitrarily withholding value from their clients (our mutual clients) who can drive their own business benefits from our joint technology. If I were a customer, I think I would be upset with a vendor withholding value that they have already paid for (and in fact are entitled to if they are under current support contracts). Hopefully, for our mutual clients benefit, this paperwork will be released shortly.”
On the last point, this is the problem with SAP, both approving of databases while having a database that it is pushing customers to use. Naturally, they can withhold information from customers to make the story look better for HANA.
Let us see how Appleby responds.
Appleby’s Response
“This is a blog around BW primarily, and BLU is definitely not ready for BW and won’t be supported until at least January now. Even when it is supported I have serious doubts to its viability for the current release of DB2.
So all the documentation I have seen for BLU limits it to 1TB and that support for larger systems would come in a future release. Could you clarify the following questions, in case I’m confused? Can we talk about physical RAM rather than the amount of CSVs you can load?
– Does IBM DB2 BLU now support columnar tables in multiple nodes (scale-out)?
– If not, what is the maximum amount of RAM supported for p-Series/AIX and 4/Linux?
– Is there support for data across multiple p-Series books in e.g. p795?
On your patch point, I really don’t get why IBM keep going on about this. DB2 has two major patches a year. HANA has two major patches a year. In addition, HANA makes bi-weekly builds available to customers which allow faster innovation during development cycles. Then customers lock down your revision when you are ready to go live, and patch periodically. With HANA you get the best of both worlds: the latest innovations when you need it, and the choice not to patch if you don’t want to. With DB2, you have to choose a Fix Pack. When customers find bugs, IBM ships customers interim patches. This means as a customer, when you find bugs, you have to run a version of the database that potentially no-one else is running and hasn’t been properly regression tested.
Here is contradicts Eaton on BLU’s readiness for BW after Chris told him the updates to the FP1 release. Appleby ended up being wrong on this.
Appleby then contradicts Chris’s statement regarding the 1 TB limit, where Appleby was wrong again.
Appleby then lies about the number of patches that HANA has per year. HANA had two “official patches” per year but had many more unofficial patches per year. Particularly at this time, HANA was being patched continuously because HANA’s development was so shoddy. And the reason that IBM “keeps going on about this” is because HANA was incredibly unstable at this time and is still nowhere near DB2’s stability even in 2019.
Appleby continues…
On a related note, I think IBM has a serious problem that we won’t see until the next release of DB2. With HANA SP7, SAP HANA has a ton of new innovations that differentiate its ability to deliver apps. With DB2 10.5 FP2, there is no innovation and DB2 BLU is an impressive version 1 product but the HANA has 24 months of stability behind it, and the development team is moving that much faster. Let’s see what HANA SP08 and DB2 10.5 FP3 have to offer!
These items turned out not to be innovations. They were development. We covered this in the article Did SAP Just Invent the Wheel with HANA?
Secondly, HANA does not qualify as innovative, as we covered in How to Understand Fake Innovation in SAP HANA.
Your accusation is pretty damning – you are accusing SAP of deliberately withholding IBM innovations from their customers. This isn’t the SAP that I know, and they immediately certified DB2 10.5. As you say, the IBM DB2 team and SAP NetWeaver team have a close working relationship. Hopefully someone at SAP can chime in on this.
I suspect that this is not the case and that the reality is that the DB2/BW team missed the drop for the last SP Stacks of NetWeaver in Aug/Sept and therefore they will have to wait until the next releases in Jan/Feb (there’s a specific calendar week for each NetWeaver release). The NetWeaver team has a published schedule at https://service.sap.com/sp-stacks (login required) and unfortunately when a sub-team misses a deadline, that code does not make it out to customers.”
Appleby points out that HANA has 24 months of stability behind it, which we know at this point is untrue, as Chris’s earlier statement about HANA downtime is quite true. HANA, at this time, did not have a single month of stability behind it.
Appleby also does not credit DB2 with having many more months of stability and being an overall far more stable database back in 2013, as well as today when this article was written in 2019.
Appleby accuses Chris of making an “outlandish” claim of withholding information from customers to help IBM. Appleby does this knowing that Chris has to be careful how he presses this claim as Chris works for IBM. Allow us to make a claim. SAP withheld this information to benefit HANA versus DB2. SAP has furthermore been hiding HANA from any benchmark competition since its inception, as we covered in the article The Hidden Issue with the SD HANA Benchmark.
Now let us see what Christ Eaton in reply.
Chris Eaton’s Response
“Now I can say a bit more than I alluded to in my previous comments. As of today (not January/Feb as you claim) BLU Acceleration is supported by SAP NetWeaver BW 7.0 and above (as you have now partially updated). All a client needs is the support packages listed in SAP Note 1825340 and then apply the correction noted in SAP Note 1889656 released today to effectively “turn on” the ability to use BLU that is already in those support packages. Now the first 3 bullets in your comparison above are still factually inaccurate and somewhat misleading and the second 3 are subjective opinions (not based on facts). If you really want to be factual you should give DB2 a full circle and HANA a 3/4 circle in the availability category since BLU is actually available for BW 7.0 and higher where as HANA is only available on 7.3 and higher. Your descriptions no longer match your circles. Or perhaps you want to rewrite this blog to come up with another set of arbitrary comparison points.”
Yes, as is typically the case in every comparison we have reviewed from Appleby, the comparison is rigged in favor of HANA. Here Chris Eaton is calling him out on it, and Chris Eaton is correct.
Let us see what Appleby says in reply.
Appleby’s Reply
“I’ve already updated the blog with information taken from publicly available information issued by IBM and SAP. If you have specific factual inaccuracies, then please send me an email and I will make corrections. No need to air your dirty laundry in public.”
As Chris Eaton called out the inaccurate comparison chart, that is curious, and that chart was not changed. It remains unchanged to this day in 2019. Chris Eaton just told Appleby what his specific factual inaccuracies were, and now Appleby is responding by gaslighting him.
At this point, it appears that Appleby is growing uncomfortable with Chris Eaton’s commentary. Appleby moves to take the discussion offline. The framing is precise. Appleby can make any claim he wants no matter how false, but if Chris Eaton contradicts Appleby in a public forum, then Chris Eaton is breaking the rules and airing his “dirty laundry.”
Let us see Chris Eaton’s Response
Chris Eaton’s Reply
“Not sure how factual errors in your blog are considered “my dirty laundry”. In any case here are some of the factual errors and misleading statements about DB2 in the blog posting (even after you have changed it).
1) Availability – you give DB2 a 1/4 circle and HANA a full circle and yet even you wrote that DB2 10.5 is available on more versions of BW than HANA is.
2) Scalability – In the HANA column you quote database sizes yet in the DB2 column you quote memory sizes and then claim a difference. Misleading at best.
3) Enterprise Readiness – You compare the capability (high availability and disaster recovery) with a feature which in DB2 we call HADR. Yet as I mentioned in other postings, today’s DB2 10.5 support both HA and DR. In fact, we can do this today with the same RPO and RTO as HANA without the use of our HADR feature. You say in the paragraph about DB2 that there is no “HA or DR” and that is incorrect. Again misleading to give HANA a full circle and BLU a quarter circle.”
Chris Eaton clearly knows DB2. And again calls out Appleby on the incorrect information included in his article that has, unlike Appleby just claimed, not been removed from the article.
Let us see Appleby’s Response.
Appleby’s Response
“Chris – please take this offline, I’m happy to respond to your emails and make any corrections, but this comment thread is getting pretty tiresome.
1) It’s my opinion that whilst BLU is supported, that support is very limited due to all the restrictions and the maturity of the BW on BLU code-line. And whilst BW can be run on BLU with BW 7.0, I don’t think that is a useful benefit. There are specific reasons why SAP only brought support for BW 7.3.x+ and this is largely because of the OLAP Compiler: BW 7.0.x was specifically tuned for BWA and running BW on HANA for BW 7.0.x would provide limited benefits over BWA.
2) They are both RAM – HANA supports an unlimited number of nodes with Tailored Datacenter Integration. Both DB2 and HANA require significant query processing memory for in-memory analytics so you cannot use all RAM for your active data.
3) HA/DR is not supported with BW on DB2 BLU. This is a hard requirement according to the joint IBM and SAP team. Please see the following, from SAP Note 1825340: “Your database server does not use HADR”. If you think this is incorrect, then please take it up with your team.”
Yes, it is quite tiresome to get fact-checked. Also, how likely is it really that Appleby will make corrections if Chris Eaton “takes it offline.”
Chris Eaton’s Response
“Hi John, since you work for a 3rd party (not IBM or SAP) and I’m assuming you are not just making stuff up, then I’m left with wondering if someone from one of our two companies is feeding you inaccurate information. I’m sure you have contacts within SAP, but it would appear that maybe those folks may not be aware of all the facts here either. I’d be glad to talk with you directly about the reality here (you already have my contact information as in a previous post I told you that if you want to check facts you can reach out to me anytime) or you could ask to speak with someone at SAP that has actually worked on the DB2 optimizations inside of BW. I’m pretty well connected here as I work in the same office as the DB2 BLU development team. This also happens to be the same office where much of the technical certification work is also done by both SAP and IBM employees (certification work takes place in both Toronto and Waldorf). This would allow you to correct some of the misinformation you list above if you actually do the research with someone in the know (like me).
If you get a chance to speak with someone at SAP who actually knows the details here, ask them about the contents of SAP NW 7.00 SP29, or 7.01 SP14, or 7.02 SP14, or 7.11 SP12, or 7.30 SP10, or 7.31/7.03 SP09 or or 7.40 SP04. These are support packages that are already out there today, available to clients, but as you know there is no “published” note that says this combination is officially supported. Hence my wondering why there is any withholding of value from clients. We do agree however on one thing…”This isn’t the SAP that I know” (or at least have always known from my dealings with some really great technical people there).”
Our analysis of John Appleby’s role with HANA is Hasso Plattner’s hand-picked shill for HANA. Let’s take a look at the definition of a shill.
“A shill, also called a plant or a stooge, is a person who publicly helps or gives credibility to a person or organization without disclosing that they have a close relationship with the person or organization. Shills can carry out their operations in the areas of media, journalism, marketing, politics, confidence games, or other business areas. A shill may also act to discredit opponents or critics of the person or organization in which they have a vested interest through character assassination or other means.
In marketing, shills are often employed to assume the air of satisfied customers and give testimonials to the merits of a given product. This type of shilling is illegal in some jurisdictions, but almost impossible to detect. It may be considered a form of unjust enrichment or unfair competition, as in California’s Business & Professions Code § 17200, which prohibits any “unfair or fraudulent business act or practice and unfair, deceptive, untrue or misleading advertising“.[7]” – Wikipedia
Appleby repeatedly published false information about HANA, and it is difficult to believe that this was done without the express support of SAP. As we will see later, Hasso Plattner even shows up in this post to try to back down Chris Eaton and to support Appleby. And this is not the only article by Appleby to have a comment by Hasso Plattner.
SAP did not hide such notes related to database certification — when it did not have a database to sell. But once it did, SAP switched gears and began protecting HANA in any way that it could. As a long time SAP consultant, I don’t think there is a way of lying invented that SAP has not engaged in, and this is the SAP that I have known since 1997. So I find these statements about “not the SAP I know” ludicrous.
John Appleby’s Response
“Hey Chris,
If you recall, I did reach out you and Paul and the response I got was “we’ll get back to you after quarter close”, and you didn’t reply to any of my questions above either. I thought they were pretty specific in their nature? Are you able to respond to those?
You are on shaky ground, accusing SAP of anti-competitive behavior in the in-memory database market. I thought IBM and SAP had a good relationship and it’s sad to see that IBM feels this way.
I pulled open a BW 7.31 SP09 system and searched the source code for DB2 BLU code and can’t find anything mentioning “ORGANIZE BY COLUMN” (which is the syntax to create a column table in DB2 BLU) so I’m not sure where you get your information from. Perhaps you can share the name of the function modules, programs, or transactions in NetWeaver that would allow the conversion of row objects to BLU column objects?
John
P.S. they did originally release some code in the 7.01 SP14 code-line for BLU, but they then removed it. See SAP Note 1881171 – DB6: Activation of an InfoCube or a DSO fails
P.P.S there is an official statement from SAP and IBM on DB2 BLU tables, updated 17th October 2013
SAP Note 1851853 – DB6: Using DB2 10.5 with SAP Applications. The use of column organized tables is currently not allowed with SAP applications. The use of column organized tables with SAP NetWeaver BW is currently under investigation”
SAP is not only guilty of anticompetitive behavior in the in-memory database market, but the entire business model of SAP is also based upon anticompetitive behavior. The SAP application of type 2 indirect access is obviously a violation of US antitrust law’s tying arrangement clause, as we covered in the article SAP Indirect Access as a Tying Arrangement Violation. The lawsuit by Teradata against SAP specifically accuses SAP of anticompetitive behavior, as we covered in the article How True is SAP’s Motion to Dismiss the Teradata Suit?
IBM consulting has an excellent relationship with SAP. IBM has made enormous amounts of money in implementing SAP. However, the IBM database group stopped having a good relationship with SAP once SAP entered the database market with HANA and began making enormously false claims about HANA, as we covered in the article IBM Finally Fighting Back Against HANA.
Hasso Makes An Appearance!
We find the timing of Hasso’s appearance a bit curious.
Appleby is being called into question by Chris Eaton, and suddenly Hasso appears. Did Appleby reach out to Hasso for a lifeline? We don’t know, but it is indeed peculiar.
Now let us see what Hasso says.
“isn’t it great chris, that you wont see any of these support packages any more once the system is running on the hana enterprise cloud. and this will be done at a fixed monthly price. we should discuss the future here, the optimization of the installed base is very important but doesn’t let us leap forward.”
Hasso comments that there will be no more support packages once the system runs on the HANA Enterprise Cloud, which is now the SAP Cloud, which has almost no production HANA instances running on it even in 2019. So this future state envisioned by Hasso has still not come to pass roughly 5.5 years later. And overall, this comment has nothing to do with the thread. Chris Eaton is asking Appleby to answer questions and make adjustments to his false article.
Hasso is doing nothing here by pivoting the conversation. So not only is the timing peculiar, but Hasso’s comment is nothing but diversionary. But as we will see, this diversion will not last for long.
Chris Eaton’s Response
Chris is going to put on notice that he is now interacting with Hasso Plattner. For people that work in SAP, even interacting with Hasso by blog comment is a big deal. Furthermore, in terms of the power dynamic, it is all with Hasso. Moreover, all Hasso has to do is reach out to a high-level person at IBM, and Chris can be easily spanked for this comment thread.
Given this context, let us see what Chris Eaton says. At first, it seems like Chris Eaton takes the bait.
“I agree Hasso, it will be nice when I can just log into my cloud service provider and ask to run my chosen SAP Application and choose to store the data in BLU Acceleration for Cloud (or wherever
and not have to worry about issues like does this module fit with this widget and do I have to read this OSS note or that one. Clients expect that the company you advise for and my company work together so that they can make their choices and move forward to run their businesses and compete in their markets. Having both our offers working well together (as they have for a very long time now even in an era of co-opetition) is what our mutual clients expect.”
Well, neither SAP nor IBM has done much in the cloud since this time, and in desperation, IBM made a costly acquisition of Red Hat. See our analysis of why IBM’s acquisition of Red Hat will likely not work out. What is the Real Story of How IBM will Use Red Hat?
Overall, there is just not much to this quote. But on the other hand, Hasso has changed the subject. So there is not much for Chris Eaton to respond to.
Hasso Plattner’s Response
“I fully agree with the working together approach. but i can’t see where db2/blu and hana should work together.
if ibm wants to run e.g. sap bw on db2/blu in the cloud for some customers, ibm has to swallow the much higher system costs and that is ok. if we talk about an installation at the customers site, sap should inform the customer about the reality in performance, cost of operation and system costs.”
And all of this is for a straightforward reason. SAP planned to use its application control over the account to push other database vendors out of SAP accounts, with zero technical justification.
Here Hasso lies, and in a major way. HANA is far more expensive in both license and TCO than DB2.
Chris Eaton Responds
“I personally agree with you on the first statement. On the others, well this is business as usual I think. Each company would advise clients on what they believe to be the business value of their offerings and customers decide. I believe one solution has lower costs, you believe the opposite…that’s fine…that’s how the world works and in the end customers decide (we don’t decide for them). And I know our two companies have always had a great collaborative relationship when it comes to ensuring clients success (even when there are some products on both sides that compete on capabilities with each other) and I’m sure as a member of the advisory board you will do whatever you can to make sure that continues so our mutual clients benefit from the great work being done at both companies.”
Brightwork Research and Analysis are entirely independent of all vendors, including all of the vendors discussed here. We, unlike Forrester, did not take money from SAP to create a fake TCO study. How Accurate Was The Forrester TCO Study? Even before HANA was implemented almost anywhere. We have performed the most HANA research of an independent entity and published the most detailed analysis of this topic. We can say that HANA is the highest TCO database that is sold today. DB2 is not even close to the cost of HANA.
Chris Eaton’s Response
“To answer your specific question
1) No
2) 16TB
3) Yes
But don’t forget that with BLU you are not limited in size by the amount of active data that can fit in real memory. So folks have the option to run on any size system they want and choose the price/performance point that is the right one for their business. I’m not sure what documentation people are feeding you but there is no IBM document that states there is a 1TB cap on BLU…if it did that document would be wrong. I know, I work in this code so take it from an expert here. In our past exchanges I pointed out that you were being given false information (the blog about setting the record straight) and looking back at those comments you actually stated that you received incorrect information and corrected the posting (and I respect that).
Yet this time I’m telling you as a DB2 subject matter expert that there is no 1TB limit and yet you insist on sticking to that point. I have to ask why?
Here Chris Eaton pivots back to the questions that Appleby asked. So he only accepted the diversion by Hasso temporarily.
Chris Eaton then contradicts what Appleby previously stated about the amount of active data placed into memory for DB2 BLU. Chris Eaton also points out that Appleby sticks to the 1TB limit even after he is corrected. To us, the reason for this obvious, Appleby wants to tell his customers that DB2 has a 1TB limit. Appleby is, after all, in the business of selling consulting services for HANA, not DB2.
Chris Eaton continues.
On your comments about FP2, you are making conjectures about things I think you know nothing about (since you are a HANA expert I wonder who is sending you these kinds of inaccurate claims to try to make some fallacious argument). FP2 was shipped to support some changes in the client side for DB2 for z/OS v11. It had nothing to do with DB2 BLU or SAP or LUW for that matter. It was actually shipped 6 weeks after FP1 because it was for updates to the client for the DB2 z/OS release so when you make claims about innovation and then refer to a client side release for a different product…well I can only say that I’m sure you are close to the HANA developments but you don’t have the depth on the DB2 development and I would therefore suggest that you rely on the knowledge of those that do (and correct the false claims made above).
More corrections and a clear annoyance with Appleby for writing about topics he does not know and has not researched. In part, this is related to the fact that Appleby does not put adequate effort into any investigation that he performs.
Chris Eaton continues…
On your latest comments. I haven’t accused SAP of anything. I’ve asked why they are not supporting two products that they know work together (since their development team in conjunction with the IBM development team worked in close partnership to make that happen). On the development side the two companies have a fantastic partnership…the teams work closely together to drive value for clients (and that’s why I said above that people involved in the technical partnership here are great and are doing the right thing for customers. I have seen first hand the value customers are deriving from this joint technology partnership). I have always felt that it’s customers first!
I have to intersect here. After working with IBM on several projects, I have never seen IBM put customers anywhere but last. In all of my IBM experiences, they seemed very comfortable lying to customers about SAP. They also gave the distinct impression that if I did not tow the IBM line that they would try to get me replaced on the project. The line for IBM consulting is maximizing the billing hours for IBM resources on the project. Now I know some good people out of IBM’s database group but have never worked with them on a project. IBM’s reputation is that they are utterly cutthroat.
Chris Eaton continues…
And having worked for IBM for a very long time I’ve been in an environment of co-opetition for almost 20 years now (almost any product in IBM has a working relationship with another company that also has products that compete with other offerings from IBM … HW, SW, services). But that’s what helps customers get value when companies (like IBM and others) are open to supporting what customers are asking for. I hope SAP will do the same shortly. I’m not taking shots at any product or company here. I’m pointing out that you are making false claims about DB2 in this posting and that is what I’m asking you to correct so that clients who are trying to make an informed decision actually make it with factual information and not FUD.”
Chris Eaton did accuse SAP of cheating, and we agree that SAP most likely did cheat. SAP is always cheating somehow, so it is usually a reasonable assumption to make.
As we said, when it comes to benchmarking HANA, SAP cheated from 2011 until the time this article was written in 2019.
Appleby’s Response
“Thanks for the response Chris. I will always update my information but given that your first response was incorrect “100TB of data and no hard limit”, I’m glad I waited. There is a hard limit of 16TB of RAM for BLU then, of which you must retain a good quantity for the sort heap in my experience.
Both HANA and BLU have a very similar architecture for hot vs cold data and HANA, like BLU, also only requires the working set to be in memory. For BLU this is done at a block level and HANA it is done at a partition-column level and each has their pros and cons. HANA aggregates much more quickly than BLU as a result, and BLU has slightly lower active memory requirements. Swings and roundabouts.
I like to think of myself as a technology expert and I’m a long-time DB2 user capable of reading the DB2 10.5 FP2 release notes. They are available here. So I repeat my point… there is no innovation in DB2 10.5 FP2, just some client updates. I think we agree on this point.
If you don’t think you’re accusing SAP of anti-competitive behavior then you should re-read your posts before pressing submit.”
Appleby would looooove to bring this conversation to closure.
Finally, we get to something that Appleby says is true: Chis Eaton did accuse SAP of anticompetitive behavior, which puts Chris Eaton and IBM in good company.
Chris Eaton’s Response
“Oh John, this is now in the realm of the laughable. Let me help you out here so you don’t continue to make false, misleading or unsubstantiated claims. If you really want to tell people that BLU is limited in database size and memory, here are limits based on today’s technology. As pointed out above the maximum server supported by BLU today fits 16TB of memory. When I plug that into our best practices sizing guideline spreadsheet (I had to make a new row because we didn’t bother to go that high) 16TB of memory in BLU would be the recommended amount of RAM for 1.8PB (yes that’s 1800TB) of uncompressed user data. Honestly, I don’t expect anyone to run BLU with 1800TB of user data today and as such I really don’t expect anyone to buy 16TB of RAM to support that size database. If you are wondering, the physical limit on the amount of data that can be stored in a DB2 single partition database is 2048PB (2,048,000TB). Which is why I said previously there is no hard limit (should have said, no realistic or practical hard limit). Feel free to quote me if you like that the maximum size database for DB2 BLU today is 1800TB if you want to be accurate and follow IBMs best practices for performance with BLU. I wonder what the size and cost of a HANA system would be to support 1800TB of user data? Theoretically is there a certified configuration that supports the RAM required for that much user data? If you think my facts are wrong, I would like to invite you up to Toronto for a sit down with me and the other BLU experts to discuss the facts here with you. I’d be glad to host you here to discuss how you as a “a long-time DB2 user” (although looking at your LinkedIn profile I don’t see you listing any DB2 experience and don’t see any DB2 endorsements from anyone, nor do I see Bluefin with any information on DB2 practices) but I’m sure you can share your experiences when we sit down and educate you on BLU. So you set the date and I will have a line-up of experts to show you the reality of BLU’s capabilities. I’m not interested in bashing other products here but you should be aware of the capabilities of DB2 if you want to make claims like this blog posting.”
Hmmm…. it looks like we aren’t the only person to accuse Appleby of
“false, misleading or unsubstantiated claims.”
This comment, in particular, is humorous.
“I wonder what the size and cost of a HANA system would be to support 1800TB of user data?”
What Chris Eaton is getting at here is that HANA is exorbitantly priced per GB. An 1800TB database priced in HANA is unthinkably expensive. HANA is also the only database priced this way. Notice further that Appleby will not engage at all on the price of HANA.
Next, Chris Eaton questions Appleby’s claimed DB2 experience. We don’t know what Appleby’s DB2 experience is, but whatever Appleby claims, we can be confident it is less than what he says.
Chris Eaton continues.
“When we sit down to talk perhaps you can tell me what the pros are for having to hold an entire column-partition of data in memory even if the query doesn’t need to process all of that data for the query results (like BLU with data skipping and page level memory caching). I’m not a HANA expert so perhaps you would like to discuss this in person with me. And you can enlighten me on claims that aggregations are faster by storing unnecessary data in memory (rather than using that same memory to hold other, more useful data).
So are you planning to update this blog post with the facts? Are you planning to call those people (that you say ask you for comparisons) back to let them know they may have been misinformed? By the way you also have some errors of omission on the Oracle In-Memory stuff too and if you like I can talk to you about that in Toronto too (if you look me up on linked in you can see that the 3rd most endorsed skill I have is actually Oracle).”
Yes, and this is the illogical nature of HANA, which was originated with what amounts to a crazy idea from Hasso Plattner. The entire database should not be loaded into memory.
And Chris Eaton finishes off by not only accusing (and backing up) Appleby’s claims around DB2 but also Oracle.
The response from Appleby is going to be…..interesting. But note that Chris Eaton did not address the accusation of SAP of anticompetitive practices. Chris likely wants to get away from this point as he works for IBM. However, this is the problem. Eventually, reality intervenes.
Before Appleby can respond, Chris Eaton now receives an endorsement from Julian Stuhler. Earlier, we questioned Hasso Plattner getting involved. Is it possible that Chris Eaton called on Julian Stuhler to endorse Chris? We think this is far less likely, as Appleby is still on the ropes, not Chris.
Julian Stuhler’s Comment
“Jon
I am not really qualified to comment on any of the Hana-specific debate above, but having known Chris Eaton for more than 10 years I am in a great position to speak to his DB2 technical knowledge and character. As well as being one of the most respected IBM technical authorities on DB2 for Linux, Unix and Windows, Chris served as a member of the International DB2 User Group (IDUG) Board of Directors for 10 years (I was also on the Board for several of those, and IDUG President for one of them). He is also in the IDUG Speaker Hall of Fame, one of a few people around the world who have consistently been voted as the best speaker by his peers at IDUG technical conferences. One of Chris’ specific areas of expertise is how key DB2 technologies stack up against competitor’s offerings, and I’ve personally heard him talk knowledgeably and in depth on many aspects of Oracle.
I’ve worked with DB2 as an independent consultant for over 25 years and Chris is definitely one of my “go to” guys in the event of any DB2 for LUW technical issue or query: I greatly respect both his in-depth technical knowledge and his personal integrity.
I like a good technical debate as much as the next guy, but when it descends to attempting to undermine the technical credibility and honesty of someone like Chris, you’ve either lost the argument or lost sight of the original discussion.”
That is easy; Appleby has lost the argument.
Appleby’s Response
“Hey Chris,
I can only assume IBM must be feeling the squeeze by how aggressively you guys are defending yourselves on a SAP blog. I have no problem with updating any factual issues, don’t worry.
The IBM sizer assumes that your working set is 10% of the total data store. It also assumes 10:1 compression with BLU. My experience has shown neither of those to be true in real-world customer scenarios but it obviously depends on the data and the business scenario.
One of the key points that people forget about is that SAP fits its entire ERP for 80,000 users onto one IBM x3950 with 80 cores and 4TB RAM running SAP HANA (2TB data, 2TB calculation memory). 4TB RAM certainly goes a long way! With ERP on HANA, we of course don’t need separate row and column stores for transactional data and operational reporting data. Plus as Hasso Plattner says, we can then use the DR instance for read-only queries for operational reporting.
I will blog separately around this but BLU is, as you well know, not well suited to OLTP workloads, so if you want to run ERP on DB2, you must run it on the DB2 row store. You can (in theory) then use the BLU column store and periodically update BLU with the contents of the row store. But you need a separate row cache, column store with BLU acceleration and ETL. That’s both complex, and wasteful, and introduces latency into the process.
I’m not going to get involved with a “mine is bigger than yours” discussion around skills and LinkedIn endorsements. Not sure why you went there. But for the sake of clarity, Bluefin is a Management Consultancy for customers who run SAP technologies, and 17% of SAP ERP customers run the DB2 RDBMS.”
If Appleby had no problem updating factual issues, we would not have recorded over 100 false statements by Appleby in our Appleby Papers.
Next, Appleby moves into HANA promotion. Then Appleby states…
“With ERP on HANA, we, of course, don’t need separate row and column stores for transactional data and operational reporting data. Plus as Hasso Plattner says, we can then use the DR instance for read-only queries for operational reporting.”
That is what SAP thought at this time, but then in SPS08, suddenly SAP added rows-oriented tables to HANA. Yes, running an entirely column-oriented database for a transaction processing system never made any sense. Appleby himself describes this change in our critique of his article in How Accurate Was John Appleby on HANA SPS08? This article is written in November 2014, and in June of 2014, or seven months later, SAP already had to change its design.
Therefore, what Appleby states here is reversed. HANA’s performance for ERP systems must have been atrocious before they added row oriented stores.
Appleby Continues
“I will blog separately around this but BLU is, as you well know, not well suited to OLTP workloads, so if you want to run ERP on DB2, you must run it on the DB2 row store. You can (in theory) then use the BLU column store and periodically update BLU with the contents of the row store. But you need a separate row cache, column store with BLU acceleration and ETL. That’s both complex, and wasteful, and introduces latency into the process.
I’m not going to get involved with a “mine is bigger than yours” discussion around skills and LinkedIn endorsements. Not sure why you went there. But for the sake of clarity, Bluefin is a Management Consultancy for customers who run SAP technologies, and 17% of SAP ERP customers run the DB2 RDBMS.”
Isn’t it? DB2 was a row-oriented store for decades before it added column-oriented tables and “in memory.”
Appleby does not want to get involved in any discussion where his qualifications are questioned. This is a pattern we have observed by Appleby, that wherever he is weak, he states he lacks interest in going into that particular topic. Chris Eaton only “went there” because he suspected that Appleby was exaggerating his DB2 knowledge.
Let us be clear. When it comes to DB2, Chris Eaton’s is bigger than John Appleby’s.
Finally, Appleby’s statement about the percentage of Bluefin’s customer base that runs DB2 is highly misleading. At this time, Appleby lead Bluefin’s HANA practice, so his only incentive was to sell HANA consulting services. And secondly, HANA was what Bluefin was primarily known for. Chris Eaton rightly pointed out that Bluefin had little DB2 work.
Chris Eaton’s Response
“Hopefully we are getting to the end of this arduous thread. I’m not sure what you mean by squeeze…all I’m trying to do here is make sure that facts are clear and that you (or any others) are not making false statements about DB2 (intentionally or unintentionally misleading, like 6TB limit above…that’s not a limit on the database size at all as I said in my comment above, that’s how much memory servers currently support and is exactly why we optimize not just for all active data in memory). By the way on the 10x compression there are several references that will all say the same thing about 10x or more data compression…you can watch my blog for clients speaking on this very topic.
What Appleby means by “squeeze” is that IBM is feeling the pressure of DB2 being removed in favor of HANA (for what turns out to have been for false claims).
Greg Eaton continues…
Also as I have said many times in other posts, for DB2, BLU is just one of a multitude of capabilities. For OLTP IBM already has an in memory scale out solution that leads the pack called pureScale. It supports up to 128 nodes in a cluster and has centralized in memory component called the CF (taken from the parallel sysplex on the mainframe) which use memory to memory direct write protocols for hot pages and locking. This blog was about BW so I didn’t bother to bring it up but pureScale is already supported by SAP for OLTP.
And finally the only reason I brought up experiences is because you make claims about DB2 that are wrong and quote your credentials of long time user of DB2 to support your claims. I have my doubts that this is true and that’s why I have invited you to come and learn about DB2 and you can share with me your experiences (no need to do that on this blog I don’t think). It was Jon that went down a slippery slope but as Julian points out I do have the credentials to talk about DB2 at great depth.”
Oooohh, here Chris Eaton flat out accuses Appleby of falsifying his DB2 background. This is entirely within Appleby’s behavioral pattern, but it is surprising to see Chris Eaton accuse him of this, especially considering Hasso Plattner is likely monitoring his responses.
And in fact…..
Hasso Plattner Magically Reappears!
We now have the second serendipitous appearance of Hasso Plattner!
“chris, if you want to see what a company could do with 25 tera bytes of dram to analyze 8.000.000.000 records of point of sales data, please come and visit the hpi in potsdam. you guys know the team there. when you see students intelligently analyzing pos data while new data is streaming in at high speed, you might change your mind with regards to scale out and dram sizes. btw the whole system (1000 nodes, 25 tera bytes dram) cost less than 1 million us and was assembled in the us. only if the data is in memory applications like you would see are possible. unfortunately the company supporting the research doesn’t want to go public. the discussion with my phd candidates is completely academic and free of any bias. -hasso “
We learn a lot about Hasso from this quote. He cannot be bothered by any type of capitalization. Later, Hasso discusses his position as a computer science professor, which is odd, as we have yet to run into a P.h.D who refuses to use caps.
Hasso makes some absurd claim, which is “just Hasso being Hasso.”
The amusing part is where Hasso declares that his P.h.D. students lack any bias. How amusing! I wonder how your graduation prospects look at HPI if you perform an analysis that shows that HANA underperforms Oracle or questions using 100% column-oriented tables in a database meant to support ERP?
I also wonder if Larry Ellison created the Larry Ellison Institute, if one could say that those P.h.D.’s were also free of bias?
Appleby’s Response
“I built a similar system for a customer with 8bn POS records on a 4-node 160-core 2TB HANA appliance based on IBM hardware – the cost of this system on the open market is around $500k. We found that 8bn transactions is around 200GB of DRAM, and we replicated master data into all nodes to avoid join colocation problems.
With HANA we expect about 18m aggregations/sec/core so we get real-world performance of around 3 seconds for any aggregation with just 160 cores.
Why would you need 25TB and 1000 cores to do the same? The numbers feel intuitively wrong.
John”
So this builds on Hasso’s pivot of the conversation.
After this, there are several more comments from different participants that we skip as they are not relevant to the main discussion thread we are tracking. And we pick it up with Chris Eaton again.
“Well you can tell that it’s not Thanksgiving day today in Germany or Canada
I’m happy to see you here writing about the values of SAP and even of HANA. I have no issues when someone wants to write blogs to tell the world what they perceive as the value of their solutions. But the issue here Hasso is that John’s initial blog posting was full of inaccurate claims about DB2 and so I corrected him but still this blog contains inaccurate claims about DB2. Note above that I said that the recommendation for 16TB was that much raw data and I also said that I don’t expect anyone to use it for that. But when John claims there is some limit on a BLU system at 1TB (initially) and now 6TB people will read that and think that’s the database size limit (especially because in the column just to the left he talks about 100TB and 500TB for HANA…clearly not the amount of memory on those systems
On the point, yes “every single byte has to come to dram memory before it can be processed” yes of coarse we agree there. But it A) doesn’t have to stay in dram for long if it’s not needed by other workloads and B) it doesn’t have to come into dram at all if we can know in advance the query does not need those bits. So yes of course the database can be much larger than available memory when you look only at the amount of data that needs to be processed at any given time for optimal performance (and even larger when you look at many of today’s databases running on Oracle for example where the data is not compressed at all or poorly compressed).”
We took out the last part of the comment because it began to discuss hockey and the hockey team Hasso owns.
But it will be interesting to see how Hasso responds.
Hasso Plattner’s Response
“that’s true. but i am in bermuda and we will have turkey later.
let’s talk about col store. in my definition a cold store contains only table entries, which under normal circumstances cannot be updated any more. inserts are only taking place when data from the hot store moves to cold store (once or a few times a year). active data has to remain in the hot store. any analysis including cold data has also to access the hot store in case of accounting, sales orders, purchasing orders etc. the cold store has an empty delta store and doesn’t need any secondary indices because all queries will be handled with full column scans. yes, not all data has to be in memory in the cold store. the usage patterns will be monitored and intelligent data provision is possible. as we heart here several times, hana loads ables by requested attributes only. a purge algorithm releases table memory, if teal wasn’t used for some time. if there is not enough memory left to load the requested columns tables will be pushed out of memory based on usage patterns. to make it absolutely clear, hana is not different in principle to any other in memory db when the cold store is concerned.
to filter data in the io-channel, as oracle, sybase iq, and others (blu?) are doing is possible and could be an option for the hana cold store. i don’t know whether the sysbase iq option has been ported already. again we have to protect our cores from doing low level work. it is more important in my opinion to improve repetitive use of large data sets. instead of reducing data for multi dimensional analysis, we can build temporary result sets and reuse them. i described this already for the hot store. this applies to the cold store as well.
i totally agree that facts should be facts. an in memory data base is mathematically fully predictable and all facts have to be very precise. let’s work on that together.
your hockey analogy has a flaw, you really believe you can program the intuition of a coach? good luck.
but be careful, if a player comes to early on the ice you get a penalty, if the player comes to late, you might get scored on. happy thaksgiving
This is a content-free series of paragraphs, at least within the context of this discussion.
Hasso pivots away from defending Appleby’s comments and then states that they will work on precise facts. This coming from Hasso, who lies about Appleby, is not something we take seriously.
Appleby’s Response
“The original point of my blog was simple – and I think the point was simply made: DB2 BLU is not ready and not supported on an EDW like NetWeaver BW.
Technology moves quickly and a 1TB limit was moved to a 16TB limit. The factual error (since corrected) doesn’t have any impact on the original point and meaning of the post.
In fact the Summer 2013 release of DB2 10.5 BLU reminds me very fondly of HANA 1.0 SP01, from Summer 2011. HANA SP01 was well suited to standalone data-marts, as is the current version of BLU. HANA 1.0 SP01 didn’t support scale-out, didn’t have a text analysis engine, or spatial engine, or graphing engine, or planning engine. It couldn’t handle OLTP workloads, much like the DB2 BLU column store. All of that makes a lot of sense for a Version 1 product. I’m not critical for BLU for being a Version 1 product.
As we know, in the last 2 years, HANA grew up – and now you can run complex transactional and analytic workloads on one store, with no duplication of data with indexes or aggregates. This drives huge operational and strategic benefits to those customers with a bold vision to transform their businesses.
What I’m less clear on – and interested in – is what the roadmap for DB2 is in this context. What is clear is that the database market is changing. HANA and Hadoop have killed the EDW market – Teradata and Netezza are in real trouble. HANA has disrupted the database market to some extent, in that Oracle, IBM and Microsoft have build column stores which mimic some of HANA’s capabilities. This is flattering.”
HANA did not kill the EDW market. Hadoop killed the Big Data market, but here is an open question as to whether data science will uncover all of those giant data lakes’ predicted value. It is easy to throw data into a bin. It is much more challenging to deliver value from that data investment. And in 2019, Hadoop is being taken over by other databases.
According to Teradata, one reason that they are in trouble is that SAP was at this time and years after pushing them out of SAP accounts using anticompetitive tactics, as we covered in the article How True is SAP’s Motion to Dismiss the Teradata Suit.
HANA never did disrupt the database market. Let us look at a listing of the most used databases.
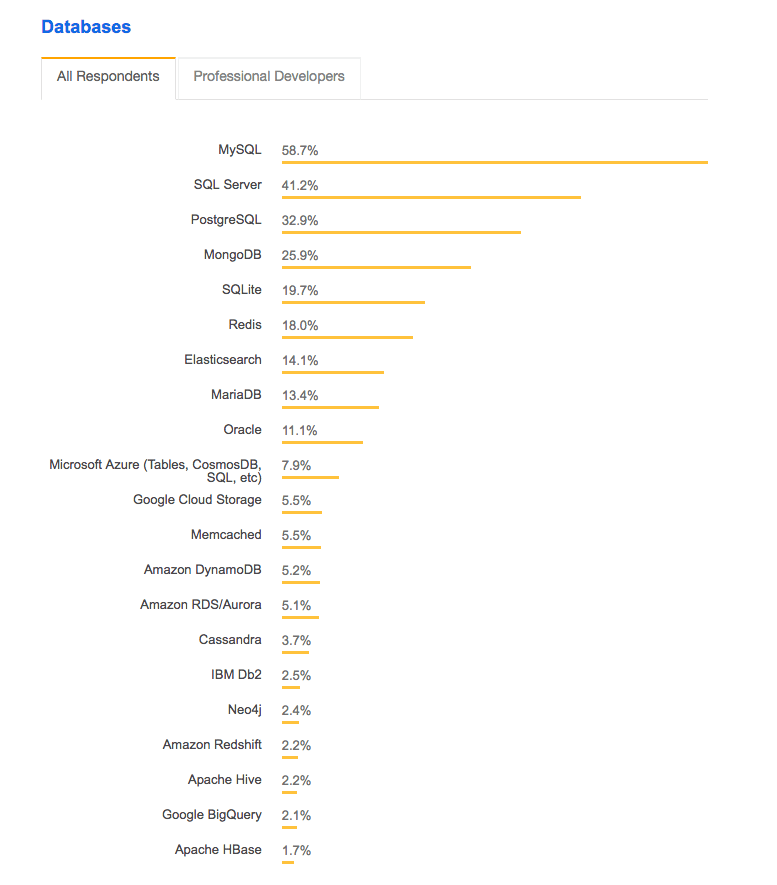
Does this look like disruption? Where is HANA? Let us say HANA is right below Apache HBase. That would be less than 1.7% of the market. Yes, Oracle should be very afraid.
Let us look at DB Engines.
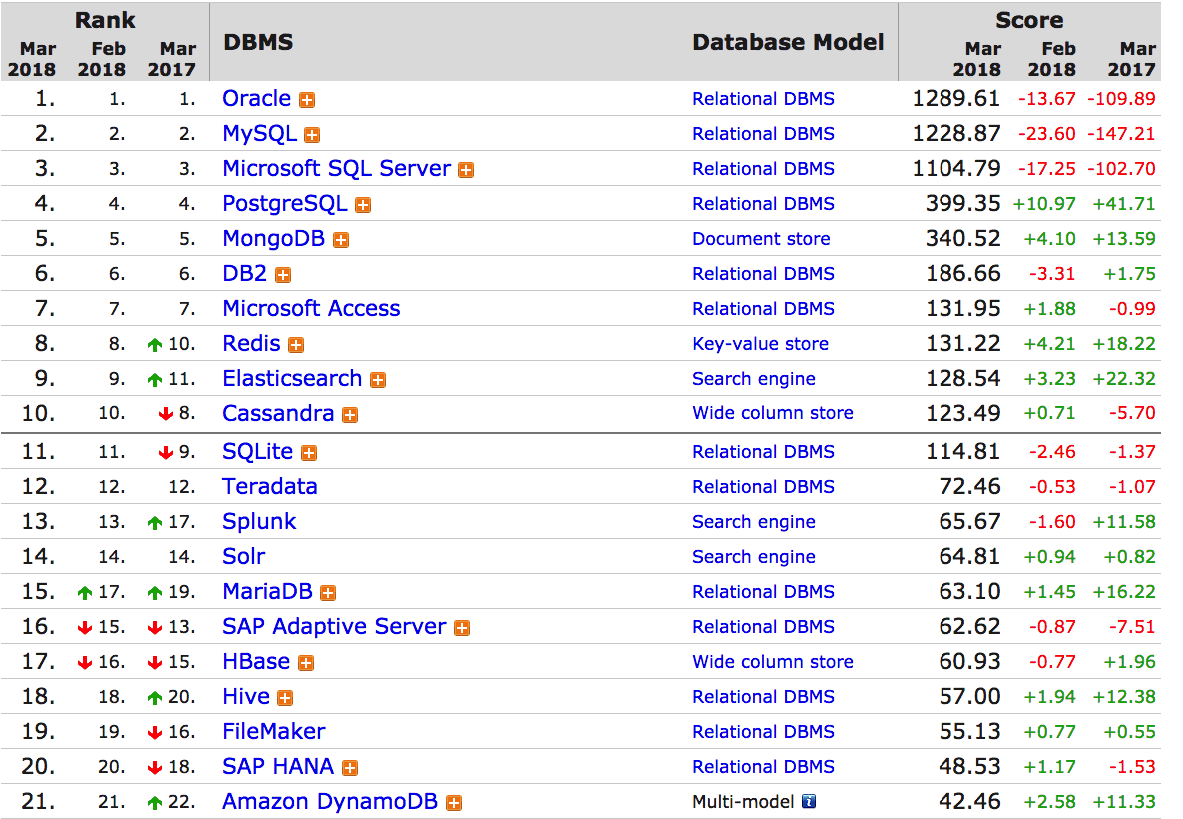 Does this look like disruption?
Does this look like disruption?
Who is disrupting the database market? HANA or PostgreSQL, MongoDB, Redis, and AWS’s RDS. But Appleby’s Bluefin does not implement any of these things. Therefore the true “disruptor” of the database market is, of course……whatever Appleby is responsible for selling consulting services for. (insert in ______)
Appleby continues…
“And what’s also clear is that Oracle, IBM and Microsoft and SAP all have strong customer bases for database, being the 4 leading players.
If I were to simplify the strategies of the top 4 players, I would put them like this:
Oracle: Bolt on a column store that allows customers to replicate row store data and accelerate OLAP workloads. Use this to drive engineered systems revenue. Market heavily.
Microsoft: Provide simple columnar in-memory functionality and make it easy to adopt. Rely on the SME market not wanting to invest and be happy with an incremental improvement.
IBM: I’m really not sure. Seems like different parts of the business want different things.
SAP: Build a platform that is truly different and attempt to disrupt Oracle, Microsoft and IBM.”
We aren’t supporters of any vendor, much less Oracle. However, does Appleby believe that Oracle “markets” more than SAP? Oracle’s marketing copies SAP! We created an explanation that we have typically sent to Oracle resources, which explains the word “hypocrisy.” But in this case, we recommend this article for Appleby Teaching Oracle About Hypocrisy on Lock-In.
There is no evidence that Microsoft’s “in-memory” is more incremental to HANA’s “in-memory.” SAP won’t allow benchmarks to be published against any competing database (SQL Server or otherwise). Therefore it is challenging to take Appleby’s claims seriously.
Appleby continues…
“In the meantime, Hadoop and MongoDB are quietly eating up market share for analytic workloads but aren’t being heavily used for OLTP workloads.
What SAP, Hadoop and MongoDB have in common is that they don’t have a legacy database customer base to keep happy and retain market share from (unless you count ASE and IQ, but SAP is much more invested in HANA).
All of this makes life very interesting.”
Well, finally, Appleby mentions MongoDB. We are entirely in favor of open source databases replacing commercial databases, but Appleby’s point makes no sense. SAP’s only argument here is that they offer a younger database than the other competitors.
Also, SAP has complete legacy ERP and application customers that they need to protect. Should it also be the case that SAP can’t innovate? That turns out to be the case. But is this Appleby’s point? Appleby seems to like to position SAP as some type of startup.
Chris Eaton’s Response
“Then why the full circle for HANA and the quarter circle for DB2 still? Why the statement of 500TB on the HANA side (i.e. storage) and the memory limit on the DB2 side (i.e. memory)? Why the HA inaccuracies still?
By the way I would be surprised if the “strategy” from SAP is to “attempt to disrupt Oracle, Microsoft and IBM”. My guess, and Hasso is likely more appropriate to comment here, is that SAP believes that their strategy is to provide value for clients. In fact the “strategy” of most successful IT companies is to provide value.
Each may go after it in a different way, but company A provides value to a client and in return the client provides monetary value back to that company…that’s how the IT economy works.
That is hypothetically how the IT economy works, but that is not actually how the IT economy works, at least not among the biggest IT providers — and this is because of a little thing called “monopoly power.”
Chris Eaton continues…
Having a strategy to just disrupt another company won’t get you very far (there isn’t much value in that for clients).”
Ahhh…Chris Eaton has caught Appleby in more inconsistencies.
This is where we depart from Chris Eaton. SAP distinctly planned to take as much database market share from Oracle, Microsoft, and IBM, and to do so without providing any value to any of their competitors. SAP already did this, using its ERP system to push out far more capable vendors in other application areas and allowing SAP to sell its vastly inferior applications, as we covered in How ERP System Was a Trojan Horse. Furthermore, IBM, the IBM consulting division, has been complicit in helping SAP distribute false information to push SAP solutions for which IBM has consulting resources trained.
Therefore, IBM has a long history of going to market by supporting SAP’s lies. But now, SAP has turned on IBM.
Appleby’s Response
“Well, this blog is my opinion and I don’t agree that DB2 BLU is scalable for BW workloads, even if it was supported. If you have proof otherwise, I’d love to see it but since DB BLU doesn’t work at all with BW, we are unfortunately left with opinion and hearsay.”
SAP did not allow IBM to provide this proof because it will not allow competitive benchmarking against SAP. No SAP published benchmark for HANA has been performed that shows other databases against HANA.
Appleby continues…
“Both HANA and DB2 BLU are actually memory-bandwidth bound for Data Warehouse applications like SAP BW. This is why SAP mandate 128GB RAM per Intel E7 CPU for BW workloads – the Intel E7 platform and specifically DDR-3 memory, can’t get information to the CPU fast enough for any more. BLU will have precisely the same problem on the E7 platform.
On the Power 7 platform, BLU will fare slightly better, because as you know, the Power 7 CPU has better memory bandwidth. From what I read, P7 is about 50% better than E7 core-core running BLU. You can do 256 cores in one Power795, so that’s equivalent to say 384 E7 cores. Now we are already in the realms of hearsay, which is frustrating, but I hear BLU aggregates around 3-5x less efficiently than HANA so you only have the equivalent of 128 HANA E7 cores, which means you max out at around 1.6TB of active RAM in the real BW world. Neither Hasso or I believe your 1.8PB story for BW workloads because the data is mostly hot.
In the meantime, SAP have tested 1PB of active data in a 100TB HANA cluster, and it works great for BW workloads. I’ll gladly revisit this blog when BW on BLU support is announced and we can do comparisons with real-world data.
SAP have publicly stated that they wanted to disrupt the legacy RDBMS market for the benefit of customers because none of the database vendors were doing this. You can spin this how you like.”
Yes, this last sentence is partially correct. SAP did intend to disrupt the RDBMS market, but it was never for the benefit of customers. It was for money, which is the same reason the only reason that Appleby published false information about HANA.
Appleby Fact Check
Amusingly, someone created the title “Appleby Fact Check” and made the following comment.
First, he noted a previous quote from Appleby.
“Both HANA and DB2 BLU are actually memory-bandwidth bound for Data Warehouse applications like SAP BW. This is why SAP mandate 128GB RAM per Intel E7 CPU for BW workloads – the Intel E7 platform and specifically DDR-3 memory, can’t get information to the CPU fast enough for any more. BLU will have precisely the same problem on the E7 platform.
On the Power 7 platform, BLU will fare slightly better, because as you know, the Power 7 CPU has better memory bandwidth. From what I read, P7 is about 50% better than E7 core-core running BLU. You can do 256 cores in one Power795, so that’s equivalent to say 384 E7 cores. Now we are already in the realms of hearsay, which is frustrating, but I hear BLU aggregates around 3-5x less efficiently than HANA so you only have the equivalent of 128 HANA E7 cores, which means you max out at around 1.6TB of active RAM in the real BW world.”
Then “Appleby Fact Check” stated the following.
“Even if we accept the dodgy 3x to 5x claim which is opposite to IBM claims (let’s actually wait on new benchmarks?)…
128 cores x 128 GB mandated per core = 16384MB = 16 TB active RAM.
This would support far larger than 16TB warehouse in most real world scenarios, i.e. where not all data is very hot. On DB2 with BLU of course, not HANA.”
This is quite true.
But Appleby was none too amused by this comment or the name of the commenter.
Appleby’s Response
“To those who follow my writing:
If I regret one thing about this sequence of articles, it has been the negative impact to the community of being in the firing line between two tech giants. It is a sad day when a blog has responses written by someone who calls themselves “Appleby Fact Check”.
I hope that 2014 brings a more collaborative working environment. The responses to this blog show the darker side of enterprise software.
Happy New Year!”
This is extremely humorous to us, but there can’t be a collaborative working environment on this topic. Appleby sees no future for DB2 for SAP. SAP’s stated plan was for every database to eventually be replaced by HANA. How are other vendors supposed to collaborate on that?
But nothing we can write is as amusing as what Appleby Fact Check writes in response.
Appleby Fact Check’s Response
“Whereas you feel that dishing out endless misinformation about products that are not called SAP HANA is collaborative and enlightened?
I don’t work for a tech giant, therefore that is just another meaningless assertion. Since you like opinions so much, I would venture that you might simply be “in the firing line” of people who don’t like your modus operandi. Putting out such a large amount of misinformation is not an accident.
Happy New Year and here’s hoping for a modicum more objectivity and accuracy in 2014.”
Oh, nice Appleby Fact Check.
Before Appleby can reply, a new commenter jumps in.
Paul Vero’s Comment
“John Appleby wrote: “I can only assume IBM must be feeling the squeeze by how aggressively you guys are defending yourselves on a SAP blog”
Paul’s comment is in reply to the copied quote above.
Paul goes on to say…
Interesting claim. I’ve been reading John’s posts for a while, let’s consider some evidence:
a) Endless anti DB2 BLU posts from John, IMO bordering on rants. I don’t know whether this is off his own bat, but judging by his statements he has a very close relationship with SAP so for all we know he’s their attack dog by proxy. Certainly at every opportunity he spins against DB2 10.5 with BLU Acceleration.
Yes, this is our conclusion also.
Appleby was a proxy or shill for SAP, and the things we wrote were approved by SAP.
b) The withdrawal of SAP Notes that contained details of DB2 BLU support, along with the failure to announce support for BW even though (according to Chris Eaton) the certification tests were actually fully passed some time ago.
SAP has a strong commercial motivation to undermine DB2 by any means necessary.
This is the problem with SAP controlled the note system and also having a competitive product against DB2. We illustrate this with the following graphic.

IBM is merely observing the same anti-competitive behavior that SAP has used against other vendors for decades. Since SAP diversified from its ERP system into other applications, SAP has argued that no non-SAP application can work with SAP ERP like an SAP application and that functionality is secondary to integration.
Again, IBM has no problem with this anticompetitive behavior and supporting it when the victims are other consulting companies, as IBM consulting specifically supports SAP in pushing out non-SAP applications. But when the same tactics are used against IBM’s database business, it is no longer so amusing.
c) The announcement by SAP that they will not be publishing any standard SD benchmarks for HANA, despite its supposedly superior OLTP performance. So large customers with very high OLTP throughput needs cannot check the OLTP performance of HANA with their current databases but instead must cross their fingers and hope. Obviously DB2 has a massive lead on the 3-tier SD benchmark, and my guess is that SAP’s problem is that HANA cannot even get close, hence the announcement.
Yes, and they still, up to 2019, have not published these benchmarks as we covered in the article The Hidden Issue with the SD HANA Benchmark.
The pattern is clear; SAP will allow no published benchmark that does not show HANA as superior to other databases. This explains why no benchmark has been published even 5.5 years after this article.
d) SAP says that instead “[they] are working on a new set of benchmarks, which is more suitable for Suite on HANA”. Interesting. If they were truly confident that HANA has the superior OLTP performance that they claim, not just great OLAP performance, then why not publish HANA results for the SD benchmark as well instead of all the bluster? Shouldn’t customers be allowed to compare?
No, customers do not have the right to compare….according to SAP. SAP what it feels is the right to profit maximize. The capitalist theory might say that SAP has a fiduciary responsibility to its shareholders to rig the benchmarks. Let us ask, under the private company rules, what duty does SAP have to release information about IBM’s database? In fact, what obligation does SAP have to release any accurate benchmark of any kind? Many of those who support the current generally acceptable capitalist model is none. A company can release any information, no matter how false, as long as it meets one objective — to maximize profits.
What this means is that profit-maximizing companies cannot be trusted to provide accurate information to the market. Instead, they provide self-serving information to the market. Therefore, all consumers of this information should be aware that private profit-maximizing entities are unreliable. This is why we recommend checking every one of these private entities and for companies to find entities that will fact check, which has made a concerted effort to be both independent from those they fact check and not to profit maximize.
If one looks at the charter of corporations, their responsibilities are to their shareholders first. Customers and employees and anything else are subordinate and increasingly distant from maximizing profit.
Furthermore, both IBM and SAP work this way. Both SAP and IBM operate under the principle of applying leverage to maximize how much they can extract from customers. It is logical for IBM to ask SAP to behave ethically and highly hypocritically as IBM, like SAP, has a long tradition of putting its interests in front of customers’ interests.
For those interested, this video is quite interested in the history of maximizing shareholder value.
Paul Vero continues…
e) The non-appearance of said “more suitable” benchmark, originally promised for Q3 yet still to appear half way through Q4. I seems it’s proving harder than they thought to find a benchmark that showcases HANA’s superiority! SAP should publish an SD benchmark for HANA in the interim.
Obviously HANA OLTP performance will improve in time, since SAP will rewrite its code to push logic into the database (i.e. a stored procedure approach) while opting not to do the same for rival databases. This will help disguise the fact the column store is inefficient for OLTP purposes. Meanwhile, it seems that hype and spin must cover the gaps.”
This is all true. However, the benchmarks SAP came up with, the BW-EML (now called BWAML and the BWH), have not comparisons against other databases published, even in 2019.
This approach to pushing its code into the database layer is exactly what SAP did. SAP, of course, claimed it was necessary for performance; however, it eliminates portability. And it is anticompetitive. However, we wonder how IBM pushes their customers to DB2 over competing databases for its applications. We don’t know, but we suspect IBM does something similar. Another question we have is whether Oracle pushes the customers of their applications to the Oracle database. How about Microsoft? As for the code pushdown, Oracle has created a PL-SQL language and has been vast proponents of stored procedures. This coincides with Larry Ellison always saying how difficult it is for companies to move away from the Oracle database. Well, one reason for this is that the application layer code has been pushed into the database. Curiously, the only anticompetitive behavior that any of these companies can see is that of their competitors. I have had many conversations with people from SAP, Oracle, IBM, and Microsoft on the topic of anticompetitive practices, and in every single instance when the subject switches to their company, I am told that
“It is just good business.”
That it appears impossible to perceive anticompetitive behavior if the company engaging in the anticompetitive behavior is also sending you checks.
The Federal Trade Commission could put a stop to all of this. They could make it illegal for any application company to own a database, requiring each vendor to sell off its database business. Corporations are by their nature unethical, and we have a long history that shows us that when companies can abuse power in the market unless stopped, they will do so.
The Return of Hasso Plattner!
Once again, when Appleby is called out, Hasso returns in just the nick of time.
“Hey guys keep your calm. let’s look at the benchmark issue first.
the current sd application of the sap erp suites reads tables without projection (didn’t matter in the past), maintains multiple indices (some via db, some as redundant tables), maintains materialized aggregates to achieve a decent response time for oltp reporting and still has some joining of tables trough loops in abap. all this is bad for a columnar in memory db. the current select ‘single’ is 1,4 times slower for a normal projection
(equal for a projection with one attribute, significantly slower for a projection of all attributes of a table with hundreds of attributes. the oltp applications have a large amount of supposedly high speed queries and transactional reporting. some of this had to be moved in the past to the bw for performance reasons. also planning activities should be part of the transactional scope, just think about the daily delivery planning.
without any major changes to the sap erp logic, we achieved an average performance gain beyond a factor two, which was the threshold sap agreed upon with our pilots (that happened at sapphire 2011). the operational savings are substantial, but already the next release of the sap erp suite on hana will take advantage of no aggregates, less indices, no redundant tables , adequate projections, use of imbedded functions in hana for planning and other functionality. these changes will come to sd and other application areas soon. only then it will make sense to work on a new sd benchmark. the current system is at work at sap for more than two month now and i think anybody who really wants to know how it works is more than welcome. definitely our partner ibm has all the connections to do so. the upcoming savings in disk storage (permanent footprint), in the necessary in memory capacity, in simplicity of the data model, the power of using views on views for reporting are mind boggling. to some extend hana and traditional databases cannot be compared any more. databases with two data representations (row AND column) cannot compete with databases with one data representation (row OR column).”
It seems the only time that it is crucial to keep things calm is when Appleby is being called out for lying. It appears if Appleby is lying about HANA, Hasso considers this “calm.” But if Appleby is challenged, suddenly things are no longer “calm.” Hasso could say…
“Please allow Appleby to lie about HANA, DB2, Oracle and SQL Server unimpeded.”
Hasso is just diverting attention away from Paul Vero’s comment. And then, he finishes off by repeating the marketing inaccuracies around HANA. His comment…
“to some extend hana and traditional databases cannot be compared any more”
It is entirely undermined by the fact that even after DB2, Oracle, and SQL Server had column-“in memory” capabilities added, SAP still did not allow the publication of competitive benchmarks.
Hasso continues..
“the notion of using stored procedures is true. twenty years ago i decided against using them in the otlp system, because we couldn’t find a common ground between oracle, ibm, msft and sap’s db. with the unbelievable scan and filter speed of in memory column store (if data is in memory) older principles of data processing are coming back: filter, sort, join, merge etc. the best way to verify this is when you convert brand new applications to hana and achieve orders of magnitude improvements.”
Hasso decided against store procedures (or perhaps others at SAP decided, and Hasso is taking credit for this decision on the part of someone else, as Hasso has never been a primary technical mind at SAP). SAP had no database and was trying to maximize its potential customers for its ERP system by porting it to as many database vendors as was feasible.
Hasso then switches back to the HANA promotion mode. However, his comment is not relevant. There is no reason other database vendors could not see these benefits after adding their column store. But he/SAP is preventing customers from seeing how other databases would compete with HANA.
Hasso continues…
“that hana is becoming a platform with numerous prefabricated algorithms for planning, genomes, predictive analytics etc is a deviation from the old paradigm. the other data base vendors have to follow (i think sap could give them the specs) or be at a disadvantage. customers using hana can choose whether they want to use only the data base functionality (standard oltp AND olap, plus analytics of unstructured data) or exploit the power of the platform.”
Looking back, 5.5 years after this is written, we can say definitively that this did not happen. SAP made this claim on several occasions, as we covered in How Accurate Was Vishal Sikka on HANA’s Future? But none of this came true.
Hasso appears to think that a response to why SAP won’t back up their claims about HANA with benchmarking as an opportunity to restate exaggerated claims around HANA. Even in 2019, HANA has yet to master OLTP and OLAP from one database, as we covered in the article HANA as a Mismatch for S/4HANA and ERP. By 2019, HANA had no significant market for performing unstructured data analysis, as we covered in How Accurate is SAP on Vora?
Hasso continues…
“now we come to ‘data has to be in memory’ or ‘intelligent prefetching’. hana can do both. but since the compression works so well (yes it could be even better, if hana works for olap in non realtime mode only) and the savings through changes in the data models are huge, sap sees no reason not to keep 80-90% of all transactional data in memory (table purging on fixed schedule). sap once has had a seven tera byte data footprint. currently the system runs at one tera byte and it is easily kept in memory. the projection for next year is that he 100% in memory footprint will shrink to less than 500 giga bytes. in ware house scenarios we expect much higher numbers and obviously not all data has to be permanently resident in memory. several scale out scenarios are currently being tested and again main memory doesn’t seem to be the bottleneck.”
And more distraction from the question of proving these unceasing claims of superiority.
Hasso continues…
“with regards to the frequency of corrections i can only say i have never seen a more rigorous testing environment than the one around hana. since hana is doing a lot of leading edge applications (not possible two years ago) it might experience critical feedback from customers. the hana team reacts instantaneously and has a sophisticated escalation procedure up to the executive board. even i on the supervisory board get escalation reports.”
This is not what has been reported to us from the field. We were not tracking HANA back in 2013, but we have been for the past several years. And if you have pressure from SAP sales, you can get excellent HANA support, but the problem is that HANA was a fragile database even in 2019. HANA has lead to data loss at clients. Even if HANA could outperform competitors in benchmarks (which is doubtful considering how SAP lags competitors in database knowledge and database developers), it could not make up for HANA’s long-term instability.
Hasso continues…
“i fully understand that our old partners are upset, that sap invaded their space, but oracle did it with erp, ibm did it with the dream team (siebel,i2,ariba) and microsoft with dynamics. each company has to fight for their own destiny and the best product offering for their customers.”
This is partially true, but in part, entirely false.
None of these companies (and none of them is ideals of ethical behavior) made the number of false claims around their products that SAP did with HANA. It is curious that the strongest point that Hasso has, that these vendors push their application customers to their databases, was not used by SAP. This would open up the topic that all of these companies engage in anti-competitive practices and that all of these companies should be broken up by the Federal Trade Commission. SAP is based in Germany, but the FTC has oversight over SAP’s US behavior or could work with European Union authorities.
Hasso continues…
“please don’t think that marketing or false statements will have any impact over time. there is nothing more transparent than application using an in memory data base in the cloud. nothing can be hidden away.”
This is curious. Hasso directly correlates marketing with false statements. So Hasso agrees that SAP’s marketing equals false statements? It appears that Hasso and we finally agree on something. Also, why is it ok for SAP to make false statements? And if Hasso is correct and false statements don’t work, why do Appleby and Hasso seem so dead set on making them?
“please stick to the facts and be willing to accept new insights.
i wrote this this blog as a professor of computer science at the university of potsdam and as an adviser in the sap hana project. i am not an employee of sap any more.
any comments are welcome. -hasso plattner”
This is a portion of the comment that illustrates what we have found from extensively analyzing Hasso: he is simply dishonest. This comment responds to Paul Vero asking why SAP won’t allow competitive benchmarking and calling out Appleby for providing false information to the market, which is what the Chris Eaton interaction was also about. And after spending a large chunk of text before this reiterating the marketing pitch for HANA instead of answering the question, Hasso asks the reader to “stick to the facts.”
Wasn’t that the point of Paul Vero’s comment? That Appleby was not sticking to the facts?
Then Hasso adds on
“be willing to accept new insights.”
Again Chris Eaton and Paul Vero stated what we could confirm, Appleby and Hasso and SAP, for that matter, do not have new insights on databases. First, neither Appleby nor Hasso knows their subject matter when it comes to databases, but secondly, both men are lying fire hydrants.
Hasso then lies again by stating that he is writing this as a
“professor of computer science at the University of Potsdam.”
Really? So Hasso is writing this and no longer has any connection to or any of his wealth tied up in SAP? Hasso is now completely independent of SAP, and the HPI is not heavily invested in the HANA storyline? This is just amazingly dishonest. Secondly, how is Hasso Plattner, a professor of computer science, anywhere? Hasso has no undergraduate or graduate degree in computer science. And he also has on honorary P.hD. As we covered in the article, Does SAP’s Hasso Plattner Have a Ph.D.?
Let us go over how the academic system works. You require an advanced degree to be a professor. And you must have studied in that area where you are teaching. Hasso worked out a deal with the University of Potsdam, where he was given a professorship if he located his HPI there. But that is corruption. That is not a legitimate professorship.
Paul Vero’s Response
“Thank you for your post. It’s hard to know where to start to reply to so many interesting points, so I’ll start by summarizing what I hope are the areas of apparent agreement, as overall I think there is probably a lot more agreement than disagreement among most of the posters here.”
This seems to be a nod to Hasso’s power because having read this entire thread. This is entirely untrue. There is a massive disagreement. Appleby has been called a liar. As one who falsifies his background, someone who disseminates false information about HANA and competitors, SAP has been accused of hiding SAP notes that show certification of DB2, etc.. It is hard to look at this thread and see “a lot more agreement than disagreement.” But when talking to a person much more powerful than ourselves, it is natural to defer.
Therefore, the reality is bent not to offend the more powerful entity. Hasso has benefited from this distortion field for decades, and it has meant that Hasso now entirely overestimates his knowledge in the areas that he covers.
Paul Vero continues
“Firstly, I think there is general agreement that column-organized databases including HANA cannot compete with row-organized databases on *raw* OLTP performance. However this won’t matter in SAP systems (and many other systems) since there are many mitigations as Hasso has described. Regarding updates, the elimination of indexes and aggregations for reporting. Regarding data retrieval, the elimination of SELECT * in favour of selecting only the required attributes.
On this last point, elimination of SELECT * will of course also significantly improve the performance of row-organized databases (though nowhere near to the same extent as column-organized databases). Unfortunately some programmers ignore this point; changing culture is difficult.”
This is true, in fact, but SAP did not agree with this at the time. They stated that OLTP processing could also be better met with a 100% column-oriented design — which sort of shows the limits of SAP’s database knowledge and anyone who agreed with them at the time. As previously discussed, SAP moved away from this position only six months later when they added row oriented tables to HANA in SPS08, as we covered in the article How Accurate Was John Appleby on HANA SPS08?
Paul Vero continues.
“Secondly, the superiority of column-organized databases for analytics is a given.
Thirdly, it is a long-established principle that performing operations in the database, i.e. the stored procedure approach, is far faster (often orders of magnitude) than working externally. Unfortunately again most programmers ignore this fact and prefer to work outside the database.”
Yes, column-organized tables in databases are better for analytics. But the trade-off stated here regarding the performance of stored procedures is not so cut and dried. There are also many overhead issues with placing stored procedures in databases. Like an immediate loss of database portability, long term maintenance issues, etc.. Paul Vero makes it sound as if programmers are illogical when they don’t use stored procedures. This is not true. For example, we are on the other side of the stored procedure debate and fully aware of the different arguments. The other database vendors disagree that SAP should be pushing code into the database layer, eliminating portability and cutting them out of the SAP market for those SAP products.
But secondly, even if a few of these items are agreed to, none of these things have been the focus of the discussion up to this point. This comment is a bit like saying that all of the participants agree that water is wet and sand is sandy, so let’s first state those topics on which we agree. This simply postpones getting to the actual issue. It is unlikely this preamble would be necessary unless this comment were written in response to Hasso Plattner.
Paul Vero continues (and finally gets to the actual topic areas)
“Now for some areas of greater doubt, to me at least. I’ll pose these as questions with my current take, for people to disagree with
Is HANA database really superior to DB2 BLU (column-organized DB2 database)? Obviously BLU is newer, but from what I’ve read and seen there is already much more similarity than difference. HANA has a lead in some areas, such as support of shared-nothing partitioning across nodes. On the other hand, the DB2 memory management is superior at present and so BLU makes better use of resources. On both these points, it seems generally expected that there will be future convergence.
On the other hand, there are a couple of obvious differences that could persist across releases. With DB2 BLU, they seem to have done a better job with the compression. The fact that BLU can evaluate range predicates on compressed data is a definite advantage, but also an advantage that could be overstated since most predicates evaluate equality (which HANA does support on compressed data). With HANA, the main advantage is better performance for small delta updates to the column-store, allowing operational analytics in the same database. SAP have made much of this and it does seem a significant advantage, certainly in a SAP context. It will be interesting to see whether IBM decide to change tack on this.”
This is all useful information. Here Paul Vero is debating the proposed superiority of HANA versus DB2, which Appleby initially proposed. Let us see Appleby’s comparison graphic again.
Yes, Appleby has HANA completely dominating the other databases.
Paul Vero continues and asks a very poignant question.
“To what extent is SAP still committed to supporting other databases that compete with HANA, and if not then will the perception of SAP shift over time to that of a company more like Oracle? Personally I’ve always respected IT companies that push for the use of open standards (unlike Oracle). I trust that the SELECT * elimination will at least be to the code common to all databases, not just HANA, but why develop a separate HANA procedural scripting language for HANA (SQLScript) rather using the SQL standard, SQL/PSM? Had SAP adopted established standards then these application coding improvements could have benefitted all compliant database technologies instead of just HANA.”
Here, Paul Vero says that Oracle functions to block out competing database vendors by forcing the customers of its applications to use the Oracle database. Let us take this time to insert a Larry Ellison quote.
“Its not enough to win, all others must lose.”
The confusion on the part of Paul Vero is that SAP only supports open standards when it can use the standard to get more customers.
Let us see what Hasso says in reply.
Hasso’s Response
“to whom it may concern,
it is hard to repeat the same arguments again and again.
seven years ago we analyzed at the hpi in potsdam the database call profile for oltp and olap systems. once we decided to move to insert only, disallowed materialized updates, disallowed performance enhancing redundant tables (e.g. with a different sort sequence), eliminated select *, replaced joining by looping over select single there was not much of a difference in the db call profile any more. in oltp systems we find a significant amount of applications, which are of the analytical type. if we take into account that many oltp type applications had to be moved to a data warehouse just for performance reasons (not to slow down data entry) and that modern planning/forecasting/predicting algorithms became realtime applications there is no significant difference between an oltp or an olap system with regards to db call profiles at all.”
the interesting new applications are the ones where massive data input can be analyzed on the fly. an interesting example is to monitor soccer players via sensors in real time with regrads to spacial moves. despite there is most likely no real business to be expected, the fact that 200.000 inserts per second are the highest data entry rate ever experienced in an sap system is remarkable. the system is based on hana.
Hasso goes back into full parrot mode and again pivots away from the question around whether SAP will certify other databases.
“so, i recommend to stop the argument: row for oltp, column for olap.
older applications, especially the 20 year old sd-benchmark scenario are not representative for modern applications any more. if you don’t trust me (i am pretty neutral, because as a professor i would loose my students being biased) ask the now over 1200 startup companies, who switched from classic rdbs to hana.”
That is not true. SD in ECC or S/4HANA works the way it always did. Neither Appleby not Hasso explain why this assertion is valid. They merely make the assertion.
The most likely explanation is that HANA cannot perform competitively in the SD benchmark.
Secondly, Hasso is not a professor. Yes, he may have wiggled the title from The University of Potsdam in return for setting up the HPI at the university. But he is unqualified to be a professor anywhere that he did not found an institute on campus. It is also doubtful that Hasso would lose his students as they most likely worship him (Hasso is worth roughly $12 billion). And it is unlikely Hasso even does much teaching. The number of people worth over $10 billion and still work as university professors is precisely zero. Hasso spends over 1/2 of his time on a sailboat, which is likely why he was in Bermuda when he wrote these replies. Hasso would have had his enormous sailboat docked at plush Bermuda harbor. This is not a man who will be grading many papers.

Does Hasso teach a lot of courses from Bermuda’s Hamilton Harbor?
Secondly, 1200 startup companies did not switch to HANA. This entire paragraph is lies. And the argument was about Appleby providing false information, not
“rows for OLTP and column for OLAP.”
Hasso continues…
“i reported already in this blog, that the sap erp system migrated from a classic rdb to hana with great performance and tco improvements.
to provide possible improvements to the installed base without upgrading to a latest application release not much can be done. but for the latest release of the suite many of the code improvements will be made available to the current row (or row+column) oriented databases. the existing code base will go forward, every function developed for hana will be tested whether it is feasible to run on the other rdbs as well. i think it must be in the interest of sap to move as many customers as possible to the latest release.”
We now know no performance or TCO improvements by moving from the other databases to HANA. The second paragraph is difficult to discern in meaning. SAP intends to block out other databases and actively runs down all other databases in the sales process. Therefore this seems to soft peddle this fact.
Hasso continues…
“some of the facts you stated are not correct. hana compresses the same way like blu or others, but in order to be oltp ready some of the compression potential was traded for speed. and with regards to data skipping while scanning attributes, i think it was already in terex (one of the forefathers of hana).
based on legal advice sap decided not to use any of the existing sql dialects for stored procedures.
so, that’s enough. if you are really interested in more details, please read some of the other blogs in this forum or try out hana yourself in the amazon cloud or contact one of the startups.”
HANA compresses nothing like what SAP and Hasso have claimed, as we covered in the article Is Hasso Plattner and SAP Correct About Database Aggregates? So what Hasso is saying has been demonstrated by many inputs we have received to be false.
If Paul Vero reads other blogs, by either Appleby or Hasso, all that Paul Vero will receive is false information.
Appleby’s Response
“Hasso,
Thanks for this. The point of this blog was (originally) just for those customers who run SAP BW: what is their choice for an in-memory database. I think that HANA makes a compelling argument here, even with the (relatively) limited options for business change that are present in a Data Warehouse like BW.
But the wonderful thing about blogs is that they sometimes take a direction that is totally different to the expected, inside the comments stream. This comment inspired me to write a follow-up blog, where we can continue this discussion. It will probably take the team a few hours to make this link live.”
So let us look at this. Appleby, who led Bluefin’s HANA consulting practice at the time, thinks that HANA makes a compelling argument for BW? We can imagine that any person who leads any consulting practice in any other database would make the same argument.
Appleby was called out as providing false information by three different individuals and was told he did not know much about DB2 by someone with obviously a great deal of knowledge around DB2.
It is highly doubtful that Appleby was happy with the direction that the comments on this blog took.
Appleby’s Response
“Some interesting points here. I’ll try to make a few observations.
First, I have personally built dual-purpose transactional/analytic systems with SAP HANA that consume >200k events/sec and provide real-time reporting on that data. Whilst you can configure Oracle or DB2 to have better bulk-loading performance than HANA, once you add indexes, HANA is faster for inserts. OLTP/OLAP is a legacy concept that we created in the 1990s to solve the analytic performance of transactional systems.
Second, because SAP is an Oracle, Microsoft and IBM VAR, they have some limitations on what they can do, as well as some anti-competitive legislation to work with. As a result, they announced that they will port any functionality onto those database, if the database supports it. The BW team is working hard to support DB2 BLU.
However DB2 BLU as it stands, only solves part of the story. It won’t accelerate BPC or Integrated Planning substantially for those customers that use that with SAP BW. In its current form it’s not suitable for SAP ERP systems so we can’t talk about accelerating financials or simplification. It remains to be seen what Microsoft and Oracle will provide, but it looks to be similar to DB2.
Third – SAP HANA and DB2 BLU are very similar for data-mart scenarios. In fact, IBM customers with DB2 row-based databases will find immediate value porting those to column-organized tables. In many cases the applications will run many times faster with no application change at all.
But when it comes to designing new transactional/analytic business applications, HANA and BLU are chalk and cheese. With HANA you persist information once, and run your application logic, planning functions, analytics, everything, against one column-oriented version of the data and then you build the integration functions and web app in the XS application server inside HANA. You can’t run BLU as a single persistence for an app (other than a data-mart) because its insert performance is poor. So you think OLTP/OLAP and store OLTP data in a row store, ETL to OLAP in a column store table and then you have a separate application server for the app. Up goes the complexity, up goes the memory usage, up goes the cost.
I really encourage you to do some more investigation into BLU and HANA and you will see how different they really are.”
Once again, up to this point, and up to 5.5 years later, there is no published benchmark outside of a Lenovo study that lacks enough detail to say anything, as we covered in the article The Problems with the Strange Lenovo HANA Benchmark.
Appleby and Hasso make a few more comments, but it is mostly a repeat of what was already said to stop the article here.
Conclusion
- Appleby was exposed in this interaction with Chris Eaton.
- We believe that Appleby summoned Hasso Plattner to make a comment that would intimidate and partially divert the discussion.
- Chris Eaton showed that while he was unwilling to challenge Hasso Plattner (and for a good reason), he brought the debate back to Appleby’s false claims at every possible occasion.
- As for Hasso Plattner, he showed enormous dishonesty in his commentary and added to Appleby’s false claims with his false claims.
- Appleby Fact Check, whoever that was, provided contradictions to Appleby and thought that Appleby’s information was so inaccurate that his name needed to be “Appleby Fact Check.”